 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid and Precise Topological Comparison with Merge Tree Neural Networks
Apr 08, 2024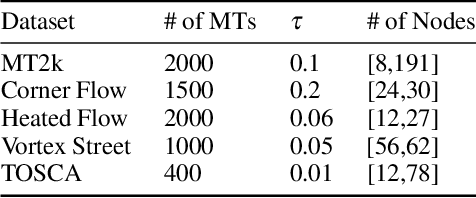
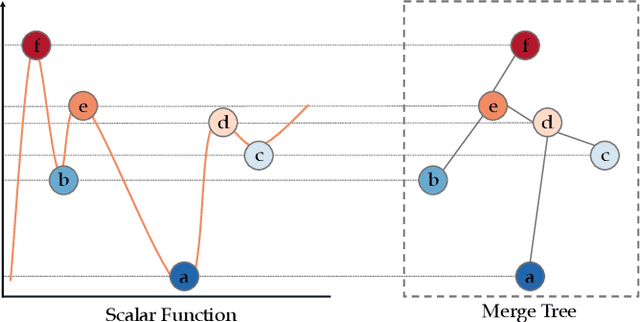
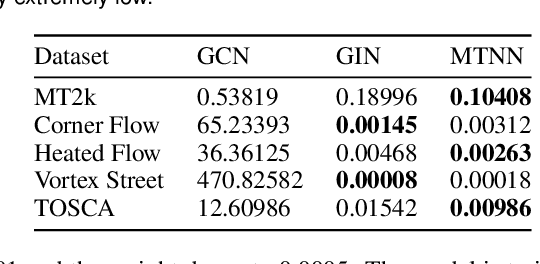
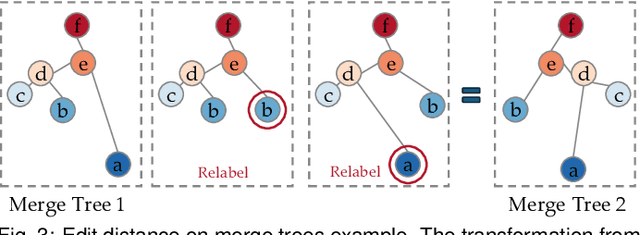
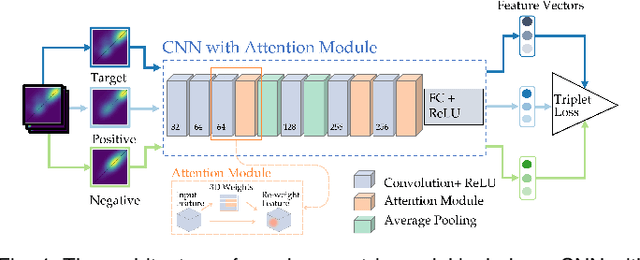
Merge trees are a valuable tool in scientific visualization of scalar fields; however, current methods for merge tree comparisons are computationally expensive, primarily due to the exhaustive matching between tree nodes. To address this challenge, we introduce the merge tree neural networks (MTNN), a learned neural network model designed for merge tree comparison. The MTNN enables rapid and high-quality similarity computation. We first demonstrate how graph neural networks (GNNs), which emerged as an effective encoder for graphs, can be trained to produce embeddings of merge trees in vector spaces that enable efficient similarity comparison. Next, we formulate the novel MTNN model that further improves the similarity comparisons by integrating the tree and node embeddings with a new topological attention mechanism. We demonstrate the effectiveness of our model on real-world data in different domains and examine our model's generalizability across various datasets. Our experimental analysis demonstrates our approach's superiority in accuracy and efficiency. In particular, we speed up the prior state-of-the-art by more than 100x on the benchmark datasets while maintaining an error rate below 0.1%.
Visualizing Topological Importance: A Class-Driven Approach
Sep 22, 2023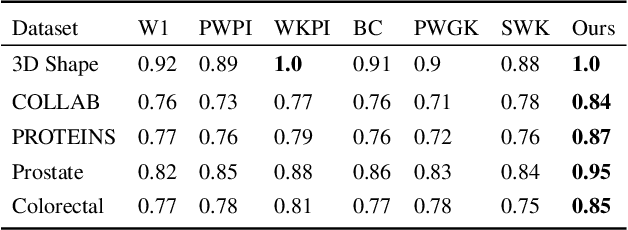
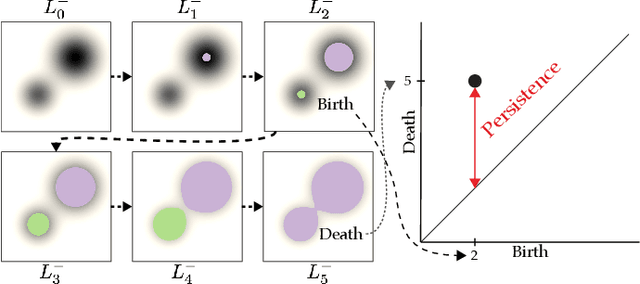
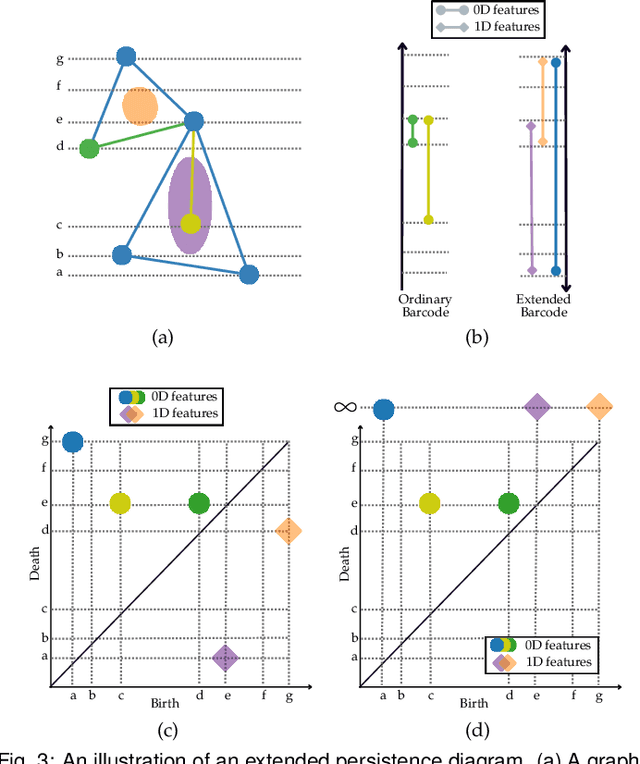
This paper presents the first approach to visualize the importance of topological features that define classes of data. Topological features, with their ability to abstract the fundamental structure of complex data, are an integral component of visualization and analysis pipelines. Although not all topological features present in data are of equal importance. To date, the default definition of feature importance is often assumed and fixed. This work shows how proven explainable deep learning approaches can be adapted for use in topological classification. In doing so, it provides the first technique that illuminates what topological structures are important in each dataset in regards to their class label. In particular, the approach uses a learned metric classifier with a density estimator of the points of a persistence diagram as input. This metric learns how to reweigh this density such that classification accuracy is high. By extracting this weight, an importance field on persistent point density can be created. This provides an intuitive representation of persistence point importance that can be used to drive new visualizations. This work provides two examples: Visualization on each diagram directly and, in the case of sublevel set filtrations on images, directly on the images themselves. This work highlights real-world examples of this approach visualizing the important topological features in graph, 3D shape, and medical image data.
Distance Measures for Geometric Graphs
Sep 26, 2022
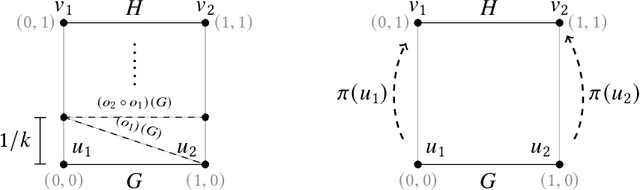
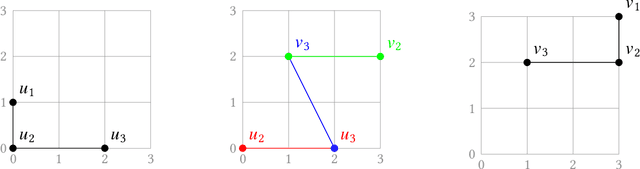
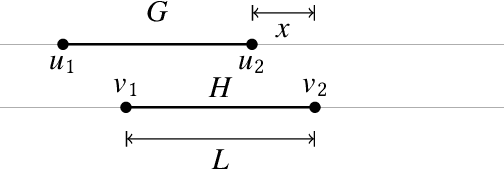
A geometric graph is a combinatorial graph, endowed with a geometry that is inherited from its embedding in a Euclidean space. Formulation of a meaningful measure of (dis-)similarity in both the combinatorial and geometric structures of two such geometric graphs is a challenging problem in pattern recognition. We study two notions of distance measures for geometric graphs, called the geometric edit distance (GED) and geometric graph distance (GGD). While the former is based on the idea of editing one graph to transform it into the other graph, the latter is inspired by inexact matching of the graphs. For decades, both notions have been lending themselves well as measures of similarity between attributed graphs. If used without any modification, however, they fail to provide a meaningful distance measure for geometric graphs -- even cease to be a metric. We have curated their associated cost functions for the context of geometric graphs. Alongside studying the metric properties of GED and GGD, we investigate how the two notions compare. We further our understanding of the computational aspects of GGD by showing that the distance is $\mathcal{NP}$-hard to compute, even if the graphs are planar and arbitrary cost coefficients are allowed.
A Domain-Oblivious Approach for Learning Concise Representations of Filtered Topological Spaces
May 25, 2021
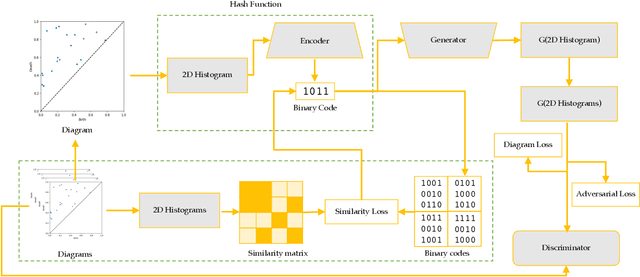

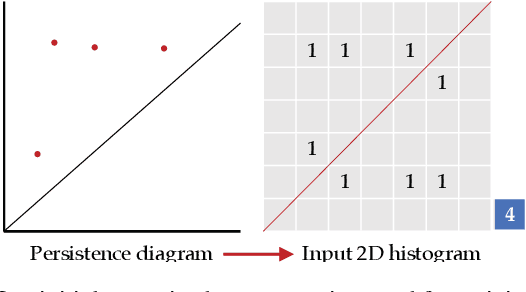
Persistence diagrams have been widely used to quantify the underlying features of filtered topological spaces in data visualization. In many applications, computing distances between diagrams is essential; however, computing these distances has been challenging due to the computational cost. In this paper, we propose a persistence diagram hashing framework that learns a binary code representation of persistence diagrams, which allows for fast computation of distances. This framework is built upon a generative adversarial network (GAN) with a diagram distance loss function to steer the learning process. Instead of attempting to transform diagrams into vectorized representations, we hash diagrams into binary codes, which have natural advantages in large-scale tasks. The training of this model is domain-oblivious in that it can be computed purely from synthetic, randomly created diagrams. As a consequence, our proposed method is directly applicable to various datasets without the need of retraining the model. These binary codes, when compared using fast Hamming distance, better maintain topological similarity properties between datasets than other vectorized representations. To evaluate this method, we apply our framework to the problem of diagram clustering and we compare the quality and performance of our approach to the state-of-the-art. In addition, we show the scalability of our approach on a dataset with 10k persistence diagrams, which is not possible with current techniques. Moreover, our experimental results demonstrate that our method is significantly faster with less memory usage, while retaining comparable or better quality comparisons.