 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
A temporal scale transformer framework for precise remaining useful life prediction in fuel cells
Apr 08, 2025In exploring Predictive Health Management (PHM) strategies for Proton Exchange Membrane Fuel Cells (PEMFC), the Transformer model, widely used in data-driven approaches, excels in many fields but struggles with time series analysis due to its self-attention mechanism, which yields a complexity of the input sequence squared and low computational efficiency. It also faces challenges in capturing both global long-term dependencies and local details effectively. To tackle this, we propose the Temporal Scale Transformer (TSTransformer), an enhanced version of the inverted Transformer (iTransformer). Unlike traditional Transformers that treat each timestep as an input token, TSTransformer maps sequences of varying lengths into tokens at different stages for inter-sequence modeling, using attention to capture multivariate correlations and feed-forward networks (FFN) to encode sequence representations. By integrating a one-dimensional convolutional layer into the multivariate attention for multi-level scaling of K and V matrices, it improves local feature extraction, captures temporal scale characteristics, and reduces token count and computational costs. Experiments comparing TSTransformer with models like Long Short-Term Memory, iTransformer, and Transformer demonstrate its potential as a powerful tool for advancing PHM in renewable energy, effectively addressing the limitations of pure Transformer models in data-driven time series tasks.
Visuo-Tactile-Based Slip Detection Using A Multi-Scale Temporal Convolution Network
Feb 27, 2023



Humans can accurately determine whether the object in hand has slipped or not by visual and tactile perception. However, it is still a challenge for robots to detect in-hand object slip through visuo-tactile fusion. To address this issue, a novel visuo-tactile fusion deep neural network is proposed to detect slip, which is a time-dependent continuous action. By using the multi-scale temporal convolution network (MS-TCN) to extract the temporal features of visual and tactile data, the slip can be detected effectively. In this paper, a 7-dregree-of-freedom (7-DoF) robot manipulator equipped with a camera and a tactile sensor is used for data collection on 50 daily objects with different shapes, materials, sizes, and weights. Therefore, a dataset is built, where the grasping data of 40 objects and 10 objects are used for network training and testing, respectively. The detection accuracy is 96.96% based on the proposed model. Also, the proposed model is compared with a visuo-tactile fusion deep neural network (DNN) based on long short-term memory network (LSTM) on the collected dataset and a public dataset using the GelSight tactile sensor. The results demonstrate that the proposed model performs better on both dataset. The proposed model can help robots grasp daily objects reliably. In addition, it can be used in grasping force control, grasping policy generation and dexterous manipulation.
Visuo-Tactile Manipulation Planning Using Reinforcement Learning with Affordance Representation
Jul 14, 2022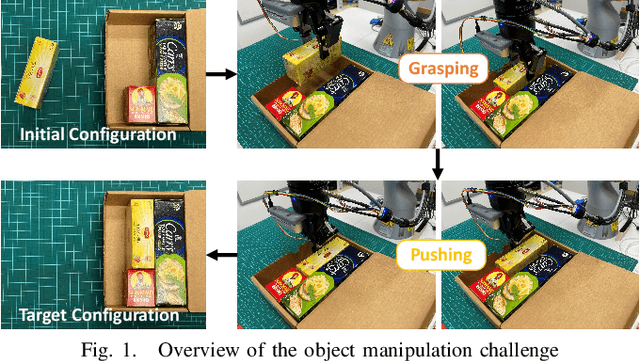
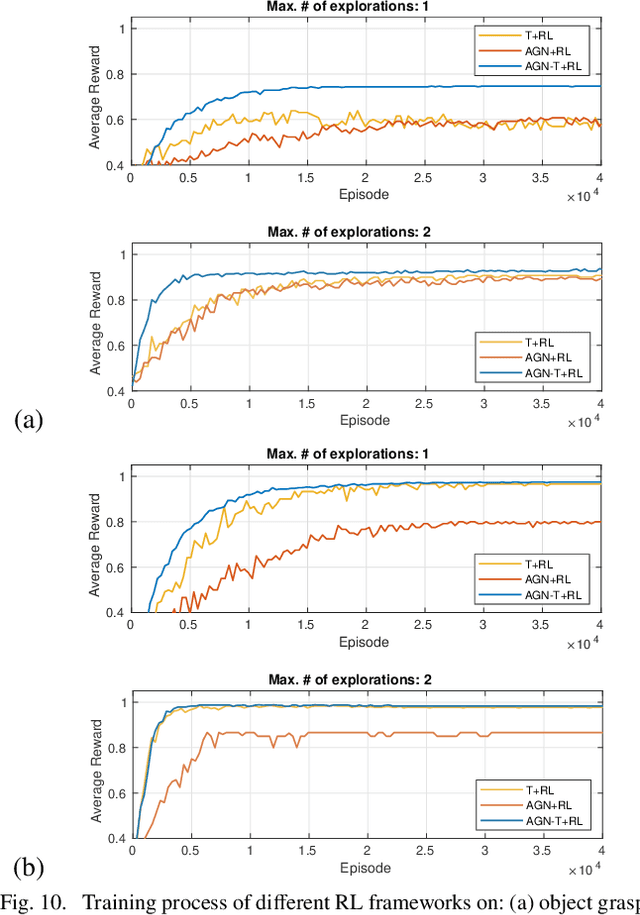
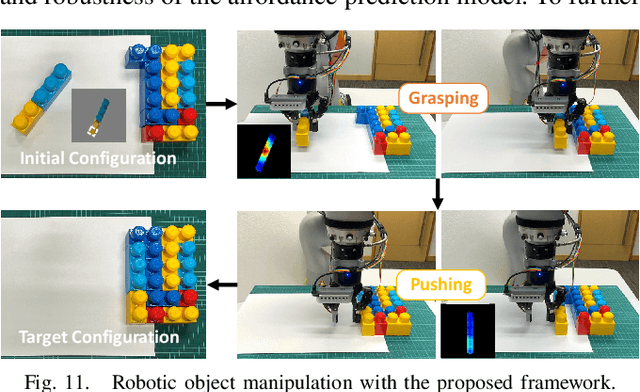
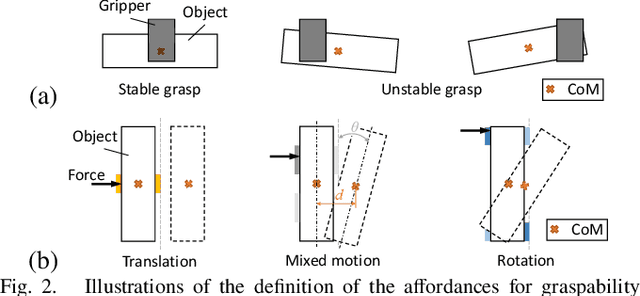
Robots are increasingly expected to manipulate objects in ever more unstructured environments where the object properties have high perceptual uncertainty from any single sensory modality. This directly impacts successful object manipulation. In this work, we propose a reinforcement learning-based motion planning framework for object manipulation which makes use of both on-the-fly multisensory feedback and a learned attention-guided deep affordance model as perceptual states. The affordance model is learned from multiple sensory modalities, including vision and touch (tactile and force/torque), which is designed to predict and indicate the manipulable regions of multiple affordances (i.e., graspability and pushability) for objects with similar appearances but different intrinsic properties (e.g., mass distribution). A DQN-based deep reinforcement learning algorithm is then trained to select the optimal action for successful object manipulation. To validate the performance of the proposed framework, our method is evaluated and benchmarked using both an open dataset and our collected dataset. The results show that the proposed method and overall framework outperform existing methods and achieve better accuracy and higher efficiency.
TAILOR: Teaching with Active and Incremental Learning for Object Registration
May 24, 2022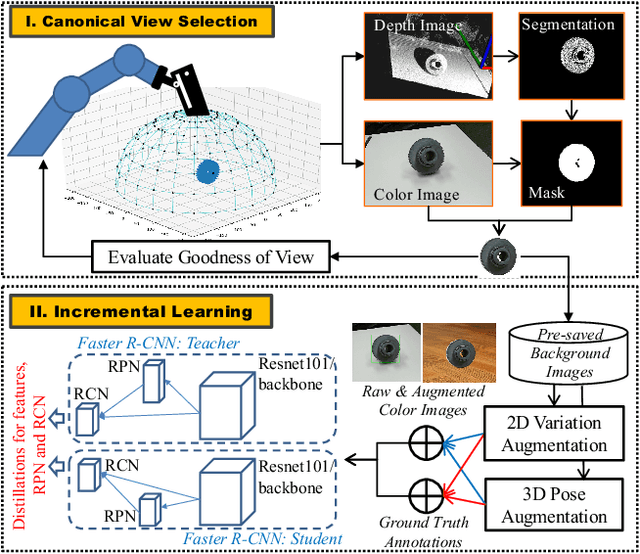
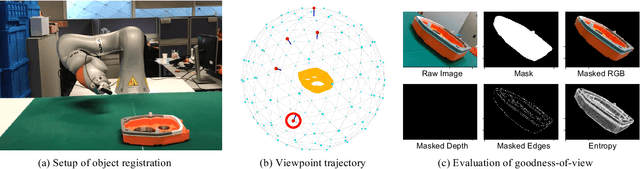

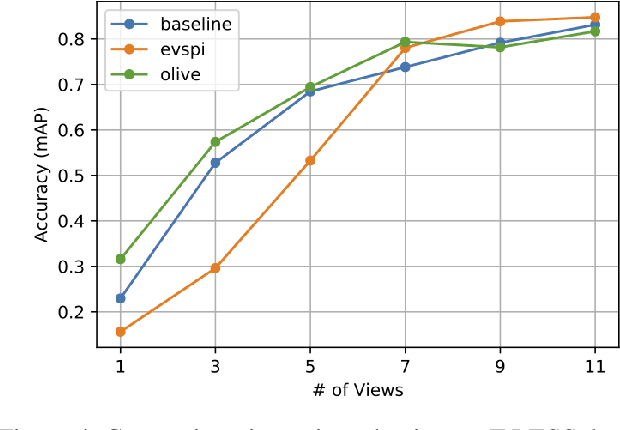
When deploying a robot to a new task, one often has to train it to detect novel objects, which is time-consuming and labor-intensive. We present TAILOR -- a method and system for object registration with active and incremental learning. When instructed by a human teacher to register an object, TAILOR is able to automatically select viewpoints to capture informative images by actively exploring viewpoints, and employs a fast incremental learning algorithm to learn new objects without potential forgetting of previously learned objects. We demonstrate the effectiveness of our method with a KUKA robot to learn novel objects used in a real-world gearbox assembly task through natural interactions.