 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Motion Factorization for Compositional Video Generation
Mar 10, 2026Compositional video generation aims to synthesize multiple instances with diverse appearance and motion, which is widely applicable in real-world scenarios. However, current approaches mainly focus on binding semantics, neglecting to understand diverse motion categories specified in prompts. In this paper, we propose a motion factorization framework that decomposes complex motion into three primary categories: motionlessness, rigid motion, and non-rigid motion. Specifically, our framework follows a planning before generation paradigm. (1) During planning, we reason about motion laws on the motion graph to obtain frame-wise changes in the shape and position of each instance. This alleviates semantic ambiguities in the user prompt by organizing it into a structured representation of instances and their interactions. (2) During generation, we modulate the synthesis of distinct motion categories in a disentangled manner. Conditioned on the motion cues, guidance branches stabilize appearance in motionless regions, preserve rigid-body geometry, and regularize local non-rigid deformations. Crucially, our two modules are model-agnostic, which can be seamlessly incorporated into various diffusion model architectures. Extensive experiments demonstrate that our framework achieves impressive performance in motion synthesis on real-world benchmarks. Our code will be released soon.
PaperSearchQA: Learning to Search and Reason over Scientific Papers with RLVR
Jan 26, 2026Search agents are language models (LMs) that reason and search knowledge bases (or the web) to answer questions; recent methods supervise only the final answer accuracy using reinforcement learning with verifiable rewards (RLVR). Most RLVR search agents tackle general-domain QA, which limits their relevance to technical AI systems in science, engineering, and medicine. In this work we propose training agents to search and reason over scientific papers -- this tests technical question-answering, it is directly relevant to real scientists, and the capabilities will be crucial to future AI Scientist systems. Concretely, we release a search corpus of 16 million biomedical paper abstracts and construct a challenging factoid QA dataset called PaperSearchQA with 60k samples answerable from the corpus, along with benchmarks. We train search agents in this environment to outperform non-RL retrieval baselines; we also perform further quantitative analysis and observe interesting agent behaviors like planning, reasoning, and self-verification. Our corpus, datasets, and benchmarks are usable with the popular Search-R1 codebase for RLVR training and released on https://huggingface.co/collections/jmhb/papersearchqa. Finally, our data creation methods are scalable and easily extendable to other scientific domains.
Visual Prompting for One-shot Controllable Video Editing without Inversion
Apr 19, 2025



One-shot controllable video editing (OCVE) is an important yet challenging task, aiming to propagate user edits that are made -- using any image editing tool -- on the first frame of a video to all subsequent frames, while ensuring content consistency between edited frames and source frames. To achieve this, prior methods employ DDIM inversion to transform source frames into latent noise, which is then fed into a pre-trained diffusion model, conditioned on the user-edited first frame, to generate the edited video. However, the DDIM inversion process accumulates errors, which hinder the latent noise from accurately reconstructing the source frames, ultimately compromising content consistency in the generated edited frames. To overcome it, our method eliminates the need for DDIM inversion by performing OCVE through a novel perspective based on visual prompting. Furthermore, inspired by consistency models that can perform multi-step consistency sampling to generate a sequence of content-consistent images, we propose a content consistency sampling (CCS) to ensure content consistency between the generated edited frames and the source frames. Moreover, we introduce a temporal-content consistency sampling (TCS) based on Stein Variational Gradient Descent to ensure temporal consistency across the edited frames. Extensive experiments validate the effectiveness of our approach.
Training-free Dense-Aligned Diffusion Guidance for Modular Conditional Image Synthesis
Apr 03, 2025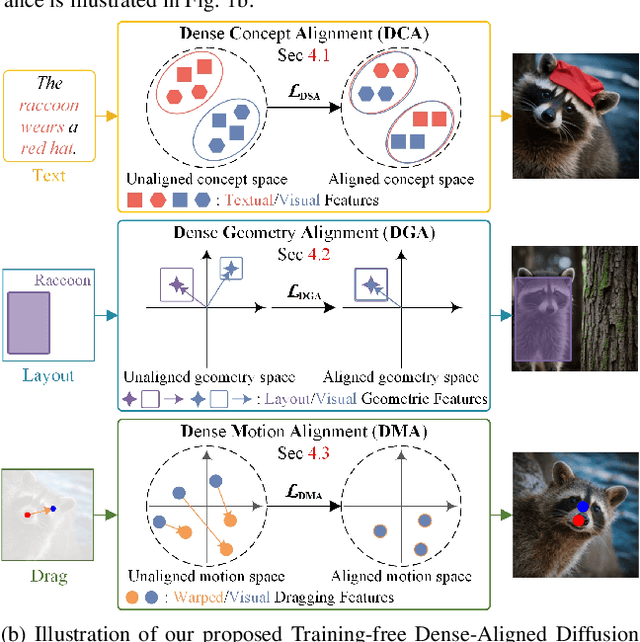
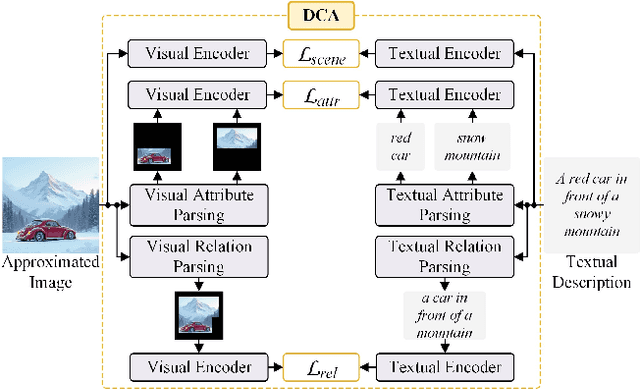
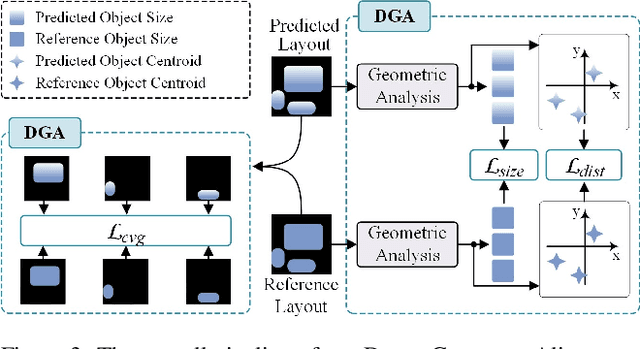
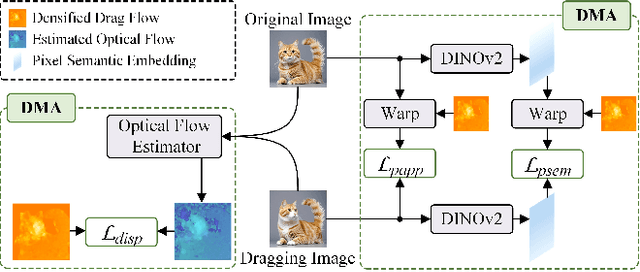
Conditional image synthesis is a crucial task with broad applications, such as artistic creation and virtual reality. However, current generative methods are often task-oriented with a narrow scope, handling a restricted condition with constrained applicability. In this paper, we propose a novel approach that treats conditional image synthesis as the modular combination of diverse fundamental condition units. Specifically, we divide conditions into three primary units: text, layout, and drag. To enable effective control over these conditions, we design a dedicated alignment module for each. For the text condition, we introduce a Dense Concept Alignment (DCA) module, which achieves dense visual-text alignment by drawing on diverse textual concepts. For the layout condition, we propose a Dense Geometry Alignment (DGA) module to enforce comprehensive geometric constraints that preserve the spatial configuration. For the drag condition, we introduce a Dense Motion Alignment (DMA) module to apply multi-level motion regularization, ensuring that each pixel follows its desired trajectory without visual artifacts. By flexibly inserting and combining these alignment modules, our framework enhances the model's adaptability to diverse conditional generation tasks and greatly expands its application range. Extensive experiments demonstrate the superior performance of our framework across a variety of conditions, including textual description, segmentation mask (bounding box), drag manipulation, and their combinations. Code is available at https://github.com/ZixuanWang0525/DADG.
Unified Prompt Attack Against Text-to-Image Generation Models
Feb 23, 2025
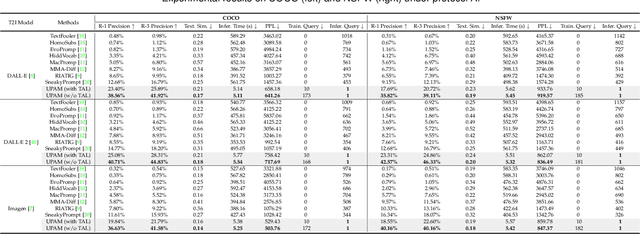


Text-to-Image (T2I) models have advanced significantly, but their growing popularity raises security concerns due to their potential to generate harmful images. To address these issues, we propose UPAM, a novel framework to evaluate the robustness of T2I models from an attack perspective. Unlike prior methods that focus solely on textual defenses, UPAM unifies the attack on both textual and visual defenses. Additionally, it enables gradient-based optimization, overcoming reliance on enumeration for improved efficiency and effectiveness. To handle cases where T2I models block image outputs due to defenses, we introduce Sphere-Probing Learning (SPL) to enable optimization even without image results. Following SPL, our model bypasses defenses, inducing the generation of harmful content. To ensure semantic alignment with attacker intent, we propose Semantic-Enhancing Learning (SEL) for precise semantic control. UPAM also prioritizes the naturalness of adversarial prompts using In-context Naturalness Enhancement (INE), making them harder for human examiners to detect. Additionally, we address the issue of iterative queries--common in prior methods and easily detectable by API defenders--by introducing Transferable Attack Learning (TAL), allowing effective attacks with minimal queries. Extensive experiments validate UPAM's superiority in effectiveness, efficiency, naturalness, and low query detection rates.
Diff-Tracker: Text-to-Image Diffusion Models are Unsupervised Trackers
Jul 11, 2024



We introduce Diff-Tracker, a novel approach for the challenging unsupervised visual tracking task leveraging the pre-trained text-to-image diffusion model. Our main idea is to leverage the rich knowledge encapsulated within the pre-trained diffusion model, such as the understanding of image semantics and structural information, to address unsupervised visual tracking. To this end, we design an initial prompt learner to enable the diffusion model to recognize the tracking target by learning a prompt representing the target. Furthermore, to facilitate dynamic adaptation of the prompt to the target's movements, we propose an online prompt updater. Extensive experiments on five benchmark datasets demonstrate the effectiveness of our proposed method, which also achieves state-of-the-art performance.
UPAM: Unified Prompt Attack in Text-to-Image Generation Models Against Both Textual Filters and Visual Checkers
May 18, 2024Text-to-Image (T2I) models have raised security concerns due to their potential to generate inappropriate or harmful images. In this paper, we propose UPAM, a novel framework that investigates the robustness of T2I models from the attack perspective. Unlike most existing attack methods that focus on deceiving textual defenses, UPAM aims to deceive both textual and visual defenses in T2I models. UPAM enables gradient-based optimization, offering greater effectiveness and efficiency than previous methods. Given that T2I models might not return results due to defense mechanisms, we introduce a Sphere-Probing Learning (SPL) scheme to support gradient optimization even when no results are returned. Additionally, we devise a Semantic-Enhancing Learning (SEL) scheme to finetune UPAM for generating target-aligned images. Our framework also ensures attack stealthiness. Extensive experiments demonstrate UPAM's effectiveness and efficiency.
Unsupervised Domain Adaptation via Domain-Adaptive Diffusion
Aug 26, 2023Unsupervised Domain Adaptation (UDA) is quite challenging due to the large distribution discrepancy between the source domain and the target domain. Inspired by diffusion models which have strong capability to gradually convert data distributions across a large gap, we consider to explore the diffusion technique to handle the challenging UDA task. However, using diffusion models to convert data distribution across different domains is a non-trivial problem as the standard diffusion models generally perform conversion from the Gaussian distribution instead of from a specific domain distribution. Besides, during the conversion, the semantics of the source-domain data needs to be preserved for classification in the target domain. To tackle these problems, we propose a novel Domain-Adaptive Diffusion (DAD) module accompanied by a Mutual Learning Strategy (MLS), which can gradually convert data distribution from the source domain to the target domain while enabling the classification model to learn along the domain transition process. Consequently, our method successfully eases the challenge of UDA by decomposing the large domain gap into small ones and gradually enhancing the capacity of classification model to finally adapt to the target domain. Our method outperforms the current state-of-the-arts by a large margin on three widely used UDA datasets.
Diffusion-based Image Translation with Label Guidance for Domain Adaptive Semantic Segmentation
Aug 23, 2023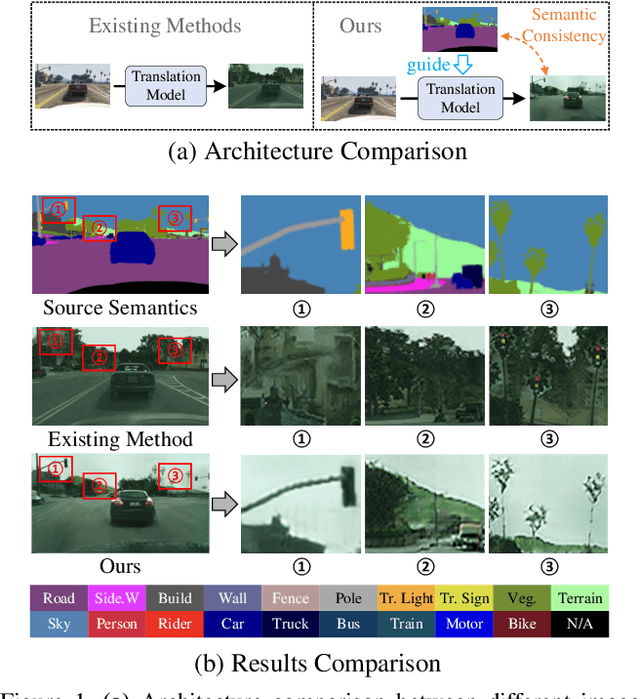
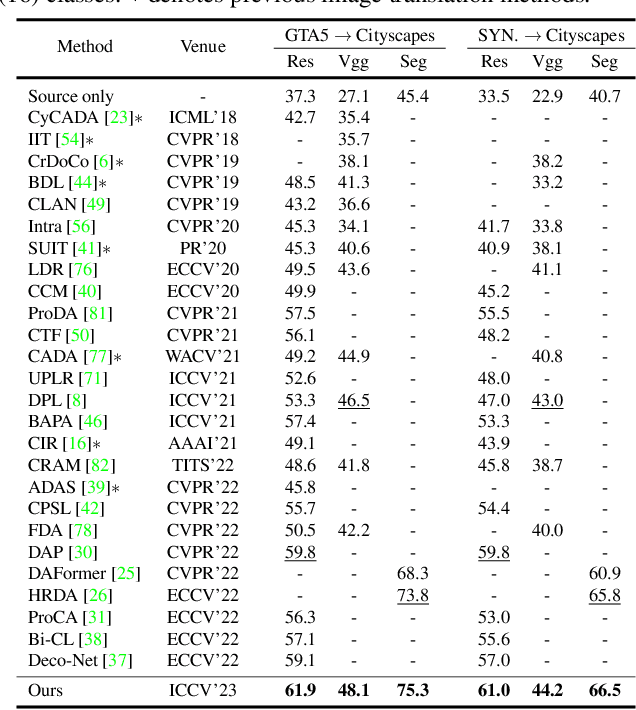


Translating images from a source domain to a target domain for learning target models is one of the most common strategies in domain adaptive semantic segmentation (DASS). However, existing methods still struggle to preserve semantically-consistent local details between the original and translated images. In this work, we present an innovative approach that addresses this challenge by using source-domain labels as explicit guidance during image translation. Concretely, we formulate cross-domain image translation as a denoising diffusion process and utilize a novel Semantic Gradient Guidance (SGG) method to constrain the translation process, conditioning it on the pixel-wise source labels. Additionally, a Progressive Translation Learning (PTL) strategy is devised to enable the SGG method to work reliably across domains with large gaps. Extensive experiments demonstrate the superiority of our approach over state-of-the-art methods.
Semantic-Aware Domain Generalized Segmentation
Apr 02, 2022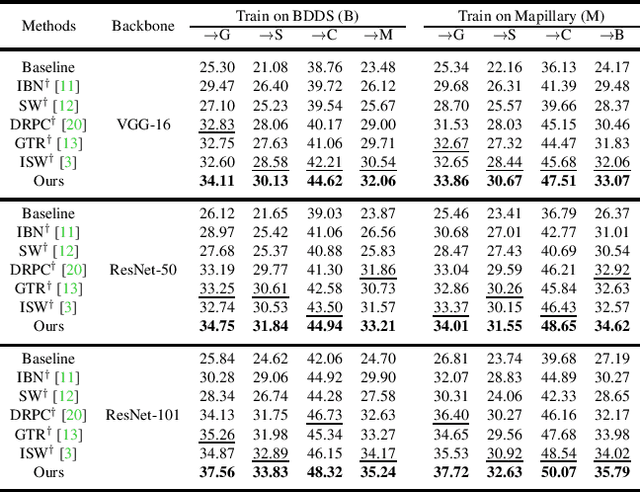
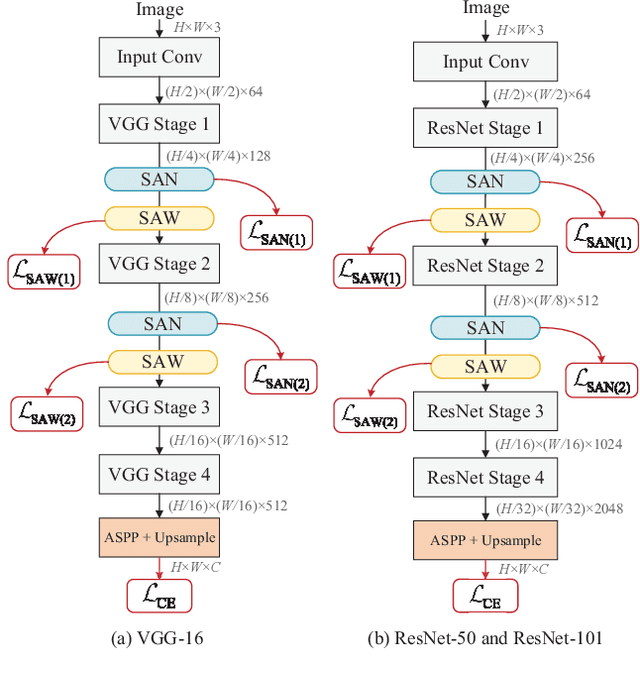
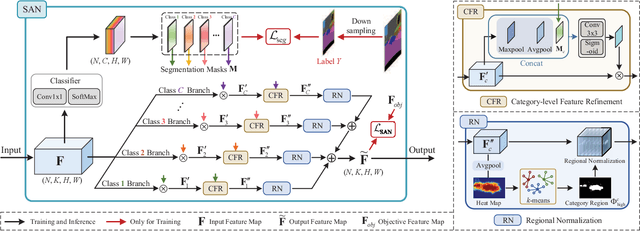

Deep models trained on source domain lack generalization when evaluated on unseen target domains with different data distributions. The problem becomes even more pronounced when we have no access to target domain samples for adaptation. In this paper, we address domain generalized semantic segmentation, where a segmentation model is trained to be domain-invariant without using any target domain data. Existing approaches to tackle this problem standardize data into a unified distribution. We argue that while such a standardization promotes global normalization, the resulting features are not discriminative enough to get clear segmentation boundaries. To enhance separation between categories while simultaneously promoting domain invariance, we propose a framework including two novel modules: Semantic-Aware Normalization (SAN) and Semantic-Aware Whitening (SAW). Specifically, SAN focuses on category-level center alignment between features from different image styles, while SAW enforces distributed alignment for the already center-aligned features. With the help of SAN and SAW, we encourage both intra-category compactness and inter-category separability. We validate our approach through extensive experiments on widely-used datasets (i.e. GTAV, SYNTHIA, Cityscapes, Mapillary and BDDS). Our approach shows significant improvements over existing state-of-the-art on various backbone networks. Code is available at https://github.com/leolyj/SAN-SAW