 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnlineSplatter: Pose-Free Online 3D Reconstruction for Free-Moving Objects
Oct 23, 2025Free-moving object reconstruction from monocular video remains challenging, particularly without reliable pose or depth cues and under arbitrary object motion. We introduce OnlineSplatter, a novel online feed-forward framework generating high-quality, object-centric 3D Gaussians directly from RGB frames without requiring camera pose, depth priors, or bundle optimization. Our approach anchors reconstruction using the first frame and progressively refines the object representation through a dense Gaussian primitive field, maintaining constant computational cost regardless of video sequence length. Our core contribution is a dual-key memory module combining latent appearance-geometry keys with explicit directional keys, robustly fusing current frame features with temporally aggregated object states. This design enables effective handling of free-moving objects via spatial-guided memory readout and an efficient sparsification mechanism, ensuring comprehensive yet compact object coverage. Evaluations on real-world datasets demonstrate that OnlineSplatter significantly outperforms state-of-the-art pose-free reconstruction baselines, consistently improving with more observations while maintaining constant memory and runtime.
Unified Prompt Attack Against Text-to-Image Generation Models
Feb 23, 2025
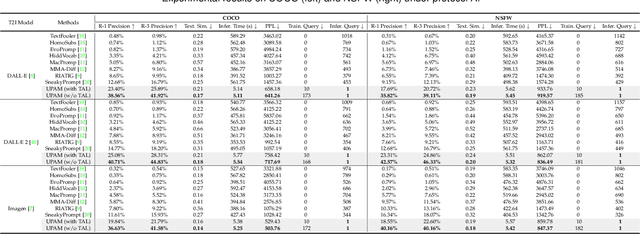


Text-to-Image (T2I) models have advanced significantly, but their growing popularity raises security concerns due to their potential to generate harmful images. To address these issues, we propose UPAM, a novel framework to evaluate the robustness of T2I models from an attack perspective. Unlike prior methods that focus solely on textual defenses, UPAM unifies the attack on both textual and visual defenses. Additionally, it enables gradient-based optimization, overcoming reliance on enumeration for improved efficiency and effectiveness. To handle cases where T2I models block image outputs due to defenses, we introduce Sphere-Probing Learning (SPL) to enable optimization even without image results. Following SPL, our model bypasses defenses, inducing the generation of harmful content. To ensure semantic alignment with attacker intent, we propose Semantic-Enhancing Learning (SEL) for precise semantic control. UPAM also prioritizes the naturalness of adversarial prompts using In-context Naturalness Enhancement (INE), making them harder for human examiners to detect. Additionally, we address the issue of iterative queries--common in prior methods and easily detectable by API defenders--by introducing Transferable Attack Learning (TAL), allowing effective attacks with minimal queries. Extensive experiments validate UPAM's superiority in effectiveness, efficiency, naturalness, and low query detection rates.
Learning to Unlearn for Robust Machine Unlearning
Jul 15, 2024Machine unlearning (MU) seeks to remove knowledge of specific data samples from trained models without the necessity for complete retraining, a task made challenging by the dual objectives of effective erasure of data and maintaining the overall performance of the model. Despite recent advances in this field, balancing between the dual objectives of unlearning remains challenging. From a fresh perspective of generalization, we introduce a novel Learning-to-Unlearn (LTU) framework, which adopts a meta-learning approach to optimize the unlearning process to improve forgetting and remembering in a unified manner. LTU includes a meta-optimization scheme that facilitates models to effectively preserve generalizable knowledge with only a small subset of the remaining set, while thoroughly forgetting the specific data samples. We also introduce a Gradient Harmonization strategy to align the optimization trajectories for remembering and forgetting via mitigating gradient conflicts, thus ensuring efficient and effective model updates. Our approach demonstrates improved efficiency and efficacy for MU, offering a promising solution to the challenges of data rights and model reusability.
Meta Compositional Referring Expression Segmentation
Apr 12, 2023



Referring expression segmentation aims to segment an object described by a language expression from an image. Despite the recent progress on this task, existing models tackling this task may not be able to fully capture semantics and visual representations of individual concepts, which limits their generalization capability, especially when handling novel compositions of learned concepts. In this work, through the lens of meta learning, we propose a Meta Compositional Referring Expression Segmentation (MCRES) framework to enhance model compositional generalization performance. Specifically, to handle various levels of novel compositions, our framework first uses training data to construct a virtual training set and multiple virtual testing sets, where data samples in each virtual testing set contain a level of novel compositions w.r.t. the virtual training set. Then, following a novel meta optimization scheme to optimize the model to obtain good testing performance on the virtual testing sets after training on the virtual training set, our framework can effectively drive the model to better capture semantics and visual representations of individual concepts, and thus obtain robust generalization performance even when handling novel compositions. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our framework.