 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Boosting for Robust Self-Supervised Visual Transformer Pre-training
Apr 12, 2023



Learning with large-scale unlabeled data has become a powerful tool for pre-training Visual Transformers (VTs). However, prior works tend to overlook that, in real-world scenarios, the input data may be corrupted and unreliable. Pre-training VTs on such corrupted data can be challenging, especially when we pre-train via the masked autoencoding approach, where both the inputs and masked ``ground truth" targets can potentially be unreliable in this case. To address this limitation, we introduce the Token Boosting Module (TBM) as a plug-and-play component for VTs that effectively allows the VT to learn to extract clean and robust features during masked autoencoding pre-training. We provide theoretical analysis to show how TBM improves model pre-training with more robust and generalizable representations, thus benefiting downstream tasks. We conduct extensive experiments to analyze TBM's effectiveness, and results on four corrupted datasets demonstrate that TBM consistently improves performance on downstream tasks.
Meta Compositional Referring Expression Segmentation
Apr 12, 2023



Referring expression segmentation aims to segment an object described by a language expression from an image. Despite the recent progress on this task, existing models tackling this task may not be able to fully capture semantics and visual representations of individual concepts, which limits their generalization capability, especially when handling novel compositions of learned concepts. In this work, through the lens of meta learning, we propose a Meta Compositional Referring Expression Segmentation (MCRES) framework to enhance model compositional generalization performance. Specifically, to handle various levels of novel compositions, our framework first uses training data to construct a virtual training set and multiple virtual testing sets, where data samples in each virtual testing set contain a level of novel compositions w.r.t. the virtual training set. Then, following a novel meta optimization scheme to optimize the model to obtain good testing performance on the virtual testing sets after training on the virtual training set, our framework can effectively drive the model to better capture semantics and visual representations of individual concepts, and thus obtain robust generalization performance even when handling novel compositions. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our framework.
Training Free Graph Neural Networks for Graph Matching
Jan 14, 2022
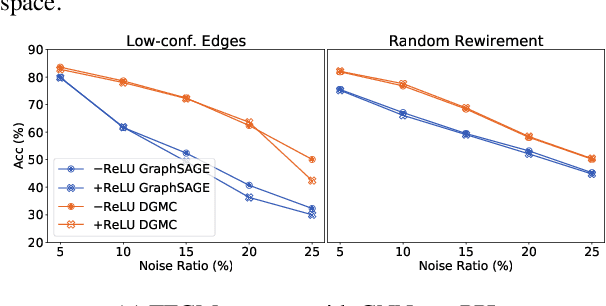
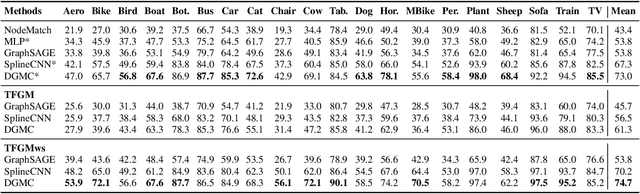
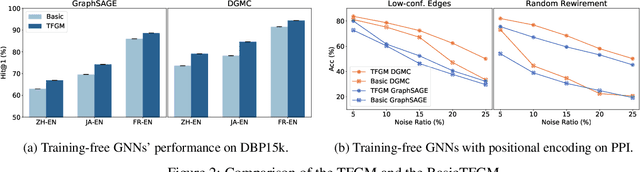
We present TFGM (Training Free Graph Matching), a framework to boost the performance of Graph Neural Networks (GNNs) based graph matching without training. TFGM sidesteps two crucial problems when training GNNs: 1) the limited supervision due to expensive annotation, and 2) training's computational cost. A basic framework, BasicTFGM, is first proposed by adopting the inference stage of graph matching methods. Our analysis shows that the BasicTFGM is a linear relaxation to the quadratic assignment formulation of graph matching. This guarantees the preservation of structure compatibility and an efficient polynomial complexity. Empirically, we further improve the BasicTFGM by handcrafting two types of matching priors into the architecture of GNNs: comparing node neighborhoods of different localities and utilizing annotation data if available. For evaluation, we conduct extensive experiments on a broad set of settings, including supervised keypoint matching between images, semi-supervised entity alignment between knowledge graphs, and unsupervised alignment between protein interaction networks. Applying TFGM on various GNNs shows promising improvements over baselines. Further ablation studies demonstrate the effective and efficient training-free property of TFGM. Our code is available at https://github.com/acharkq/Training-Free-Graph-Matching.
NExT-QA:Next Phase of Question-Answering to Explaining Temporal Actions
May 23, 2021
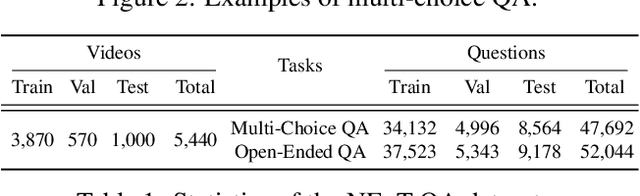


We introduce NExT-QA, a rigorously designed video question answering (VideoQA) benchmark to advance video understanding from describing to explaining the temporal actions. Based on the dataset, we set up multi-choice and open-ended QA tasks targeting causal action reasoning, temporal action reasoning, and common scene comprehension. Through extensive analysis of baselines and established VideoQA techniques, we find that top-performing methods excel at shallow scene descriptions but are weak in causal and temporal action reasoning. Furthermore, the models that are effective on multi-choice QA, when adapted to open-ended QA, still struggle in generalizing the answers. This raises doubt on the ability of these models to reason and highlights possibilities for improvement. With detailed results for different question types and heuristic observations for future works, we hope NExT-QA will guide the next generation of VQA research to go beyond superficial scene description towards a deeper understanding of videos. (The dataset and related resources are available at https://github.com/doc-doc/NExT-QA.git)
Visual Relation Grounding in Videos
Jul 21, 2020

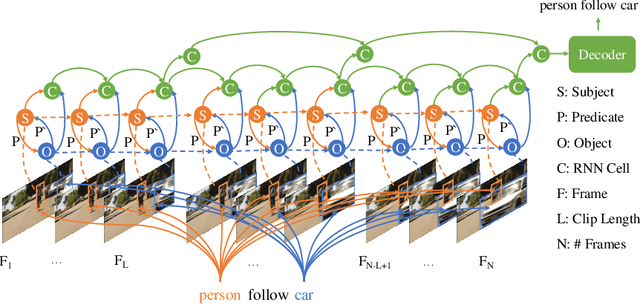
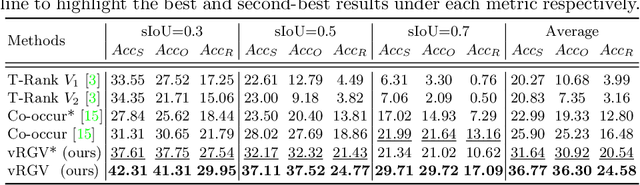
In this paper, we explore a novel task named visual Relation Grounding in Videos (vRGV). The task aims at spatio-temporally localizing the given relations in the form of subject-predicate-object in the videos, so as to provide supportive visual facts for other high-level video-language tasks (e.g., video-language grounding and video question answering). The challenges in this task include but not limited to: (1) both the subject and object are required to be spatio-temporally localized to ground a query relation; (2) the temporal dynamic nature of visual relations in videos is difficult to capture; and (3) the grounding should be achieved without any direct supervision in space and time. To ground the relations, we tackle the challenges by collaboratively optimizing two sequences of regions over a constructed hierarchical spatio-temporal region graph through relation attending and reconstruction, in which we further propose a message passing mechanism by spatial attention shifting between visual entities. Experimental results demonstrate that our model can not only outperform baseline approaches significantly, but also produces visually meaningful facts to support visual grounding. (Code is available at https://github.com/doc-doc/vRGV).