 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingshu: A Generalist Foundation Model for Unified Multimodal Medical Understanding and Reasoning
Jun 08, 2025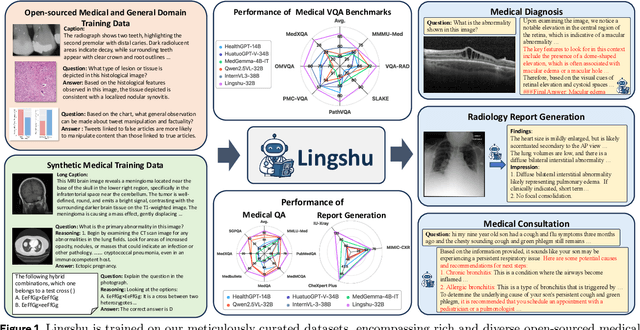
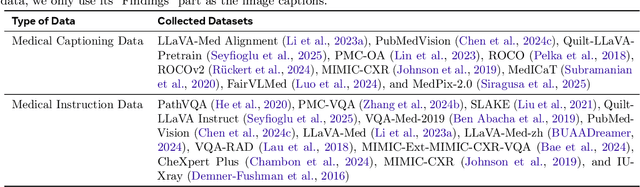
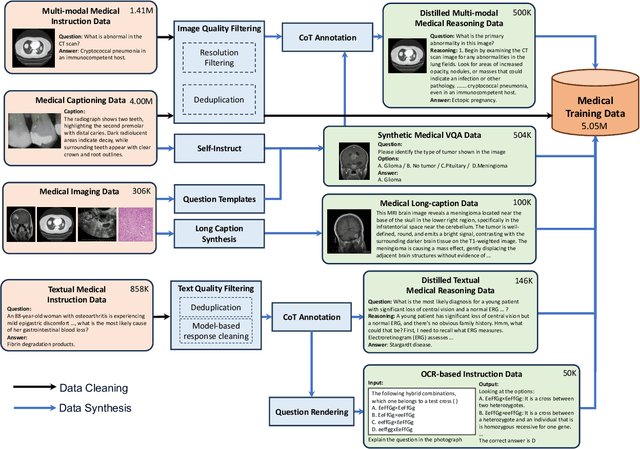

Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities in understanding common visual elements, largely due to their large-scale datasets and advanced training strategies. However, their effectiveness in medical applications remains limited due to the inherent discrepancies between data and tasks in medical scenarios and those in the general domain. Concretely, existing medical MLLMs face the following critical limitations: (1) limited coverage of medical knowledge beyond imaging, (2) heightened susceptibility to hallucinations due to suboptimal data curation processes, (3) lack of reasoning capabilities tailored for complex medical scenarios. To address these challenges, we first propose a comprehensive data curation procedure that (1) efficiently acquires rich medical knowledge data not only from medical imaging but also from extensive medical texts and general-domain data; and (2) synthesizes accurate medical captions, visual question answering (VQA), and reasoning samples. As a result, we build a multimodal dataset enriched with extensive medical knowledge. Building on the curated data, we introduce our medical-specialized MLLM: Lingshu. Lingshu undergoes multi-stage training to embed medical expertise and enhance its task-solving capabilities progressively. Besides, we preliminarily explore the potential of applying reinforcement learning with verifiable rewards paradigm to enhance Lingshu's medical reasoning ability. Additionally, we develop MedEvalKit, a unified evaluation framework that consolidates leading multimodal and textual medical benchmarks for standardized, fair, and efficient model assessment. We evaluate the performance of Lingshu on three fundamental medical tasks, multimodal QA, text-based QA, and medical report generation. The results show that Lingshu consistently outperforms the existing open-source multimodal models on most tasks ...
LLM-R2: A Large Language Model Enhanced Rule-based Rewrite System for Boosting Query Efficiency
Apr 19, 2024



Query rewrite, which aims to generate more efficient queries by altering a SQL query's structure without changing the query result, has been an important research problem. In order to maintain equivalence between the rewritten query and the original one during rewriting, traditional query rewrite methods always rewrite the queries following certain rewrite rules. However, some problems still remain. Firstly, existing methods of finding the optimal choice or sequence of rewrite rules are still limited and the process always costs a lot of resources. Methods involving discovering new rewrite rules typically require complicated proofs of structural logic or extensive user interactions. Secondly, current query rewrite methods usually rely highly on DBMS cost estimators which are often not accurate. In this paper, we address these problems by proposing a novel method of query rewrite named LLM-R2, adopting a large language model (LLM) to propose possible rewrite rules for a database rewrite system. To further improve the inference ability of LLM in recommending rewrite rules, we train a contrastive model by curriculum to learn query representations and select effective query demonstrations for the LLM. Experimental results have shown that our method can significantly improve the query execution efficiency and outperform the baseline methods. In addition, our method enjoys high robustness across different datasets.
Semantic-Aware Contrastive Sentence Representation Learning with Large Language Models
Oct 17, 2023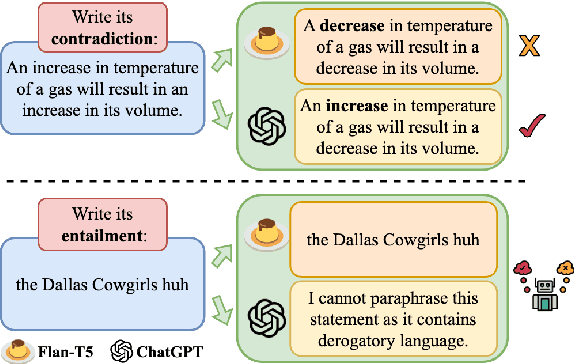
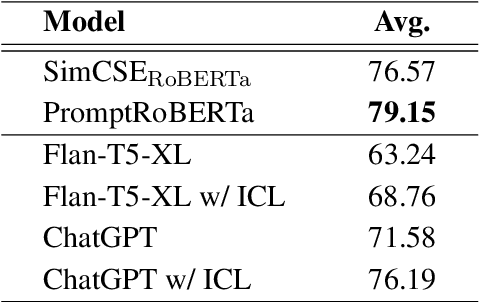
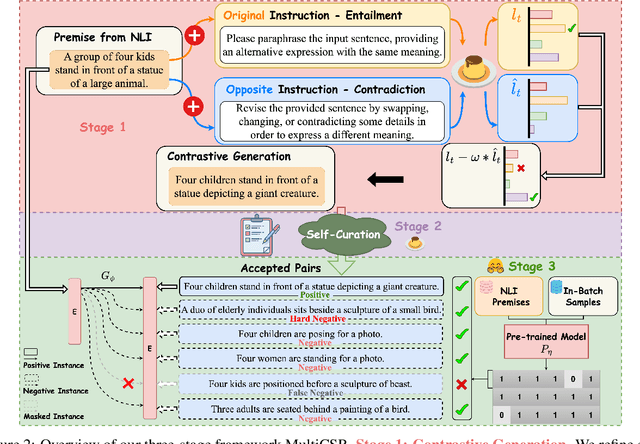

Contrastive learning has been proven to be effective in learning better sentence representations. However, to train a contrastive learning model, large numbers of labeled sentences are required to construct positive and negative pairs explicitly, such as those in natural language inference (NLI) datasets. Unfortunately, acquiring sufficient high-quality labeled data can be both time-consuming and resource-intensive, leading researchers to focus on developing methods for learning unsupervised sentence representations. As there is no clear relationship between these unstructured randomly-sampled sentences, building positive and negative pairs over them is tricky and problematic. To tackle these challenges, in this paper, we propose SemCSR, a semantic-aware contrastive sentence representation framework. By leveraging the generation and evaluation capabilities of large language models (LLMs), we can automatically construct a high-quality NLI-style corpus without any human annotation, and further incorporate the generated sentence pairs into learning a contrastive sentence representation model. Extensive experiments and comprehensive analyses demonstrate the effectiveness of our proposed framework for learning a better sentence representation with LLMs.