 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aware Contrastive Sentence Representation Learning with Large Language Models
Paper and Code
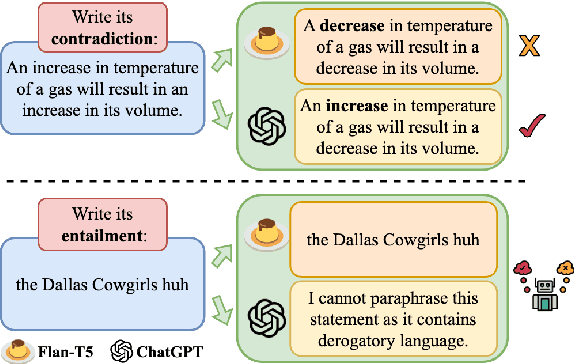
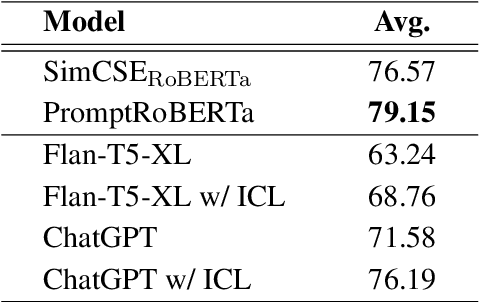
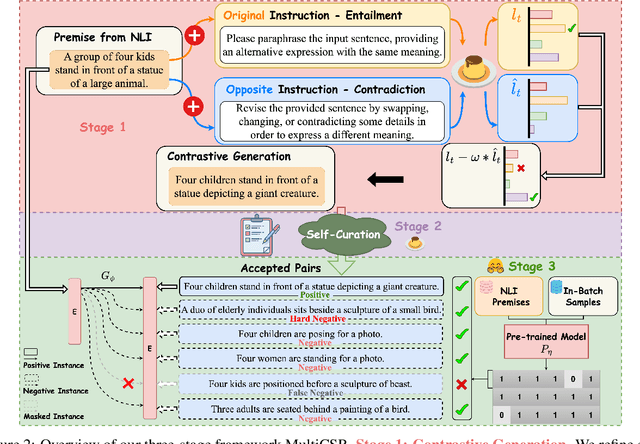

Contrastive learning has been proven to be effective in learning better sentence representations. However, to train a contrastive learning model, large numbers of labeled sentences are required to construct positive and negative pairs explicitly, such as those in natural language inference (NLI) datasets. Unfortunately, acquiring sufficient high-quality labeled data can be both time-consuming and resource-intensive, leading researchers to focus on developing methods for learning unsupervised sentence representations. As there is no clear relationship between these unstructured randomly-sampled sentences, building positive and negative pairs over them is tricky and problematic. To tackle these challenges, in this paper, we propose SemCSR, a semantic-aware contrastive sentence representation framework. By leveraging the generation and evaluation capabilities of large language models (LLMs), we can automatically construct a high-quality NLI-style corpus without any human annotation, and further incorporate the generated sentence pairs into learning a contrastive sentence representation model. Extensive experiments and comprehensive analyses demonstrate the effectiveness of our proposed framework for learning a better sentence representation with LLMs.