 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUG-FedPrompt: Practical Few-shot Federated NLP with Data-augmented Prompts
Paper and Code
Dec 01, 2022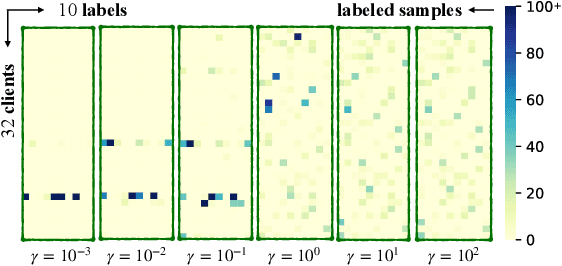

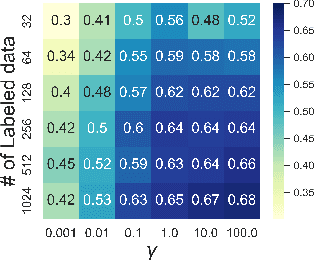

Transformer-based pre-trained models have become the de-facto solution for NLP tasks. Fine-tuning such pre-trained models for downstream tasks often requires tremendous amount of data that is both private and labeled. However, in reality: 1) such private data cannot be collected and is distributed across mobile devices, and 2) well-curated labeled data is scarce. To tackle those issues, we first define a data generator for federated few-shot learning tasks, which encompasses the quantity and distribution of scarce labeled data in a realistic setting. Then we propose AUG-FedPrompt, a prompt-based federated learning algorithm that carefully annotates abundant unlabeled data for data augmentation. AUG-FedPrompt can perform on par with full-set fine-tuning with very few initial labeled data.