 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYouZhi: Towards High-Concurrency Financial LLMs via Adaptive GQA-to-MLA Transition
Jun 04, 2026Large language models (LLMs) drive significant financial innovations, yet their high-concurrency deployment is severely bottlenecked by KV cache memory overhead, which inflates infrastructure costs and throttles scalability. To address this, we propose YouZhi-LLM, a highly efficient financial LLM empowered by a comprehensive structural transition and training pipeline natively built on the Huawei Ascend ecosystem. At its algorithmic core, YouZhi-LLM features a layer-adaptive GQA-to-MLA transition framework that dynamically assigns per-layer FreqFold sizes, maximizing KV-cache compression while minimizing perplexity degradation. To recover representation capacity and inject domain expertise, the Ascend-based training pipeline seamlessly integrates generalized knowledge distillation with financial-specific supervised fine-tuning. Evaluations demonstrate the superiority of this systematic approach, with the adaptive transition reducing perplexity degradation by up to 35% over uniform baselines. Crucially, when evaluated on Ascend NPUs via vLLM-Ascend, the massive KV-cache reduction translates directly into deployment efficiency. Compared to their respective base models, YouZhi-7B yields a 12.3% improvement in average financial benchmark score alongside a 2.69$\times$ increase in maximum concurrency; similarly, YouZhi-14B achieves a 7.0% accuracy gain and a 2.43$\times$ concurrency boost, establishing a new paradigm for cost-effective, high-throughput financial inference.
Federated Fine-tuning of Billion-Sized Language Models across Mobile Devices
Aug 26, 2023Large Language Models (LLMs) are transforming the landscape of mobile intelligence. Federated Learning (FL), a method to preserve user data privacy, is often employed in fine-tuning LLMs to downstream mobile tasks, an approach known as FedLLM. Though recent efforts have addressed the network issue induced by the vast model size, they have not practically mitigated vital challenges concerning integration with mobile devices, such as significant memory consumption and sluggish model convergence. In response to these challenges, this work introduces FwdLLM, an innovative FL protocol designed to enhance the FedLLM efficiency. The key idea of FwdLLM to employ backpropagation (BP)-free training methods, requiring devices only to execute ``perturbed inferences''. Consequently, FwdLLM delivers way better memory efficiency and time efficiency (expedited by mobile NPUs and an expanded array of participant devices). FwdLLM centers around three key designs: (1) it combines BP-free training with parameter-efficient training methods, an essential way to scale the approach to the LLM era; (2) it systematically and adaptively allocates computational loads across devices, striking a careful balance between convergence speed and accuracy; (3) it discriminatively samples perturbed predictions that are more valuable to model convergence. Comprehensive experiments with five LLMs and three NLP tasks illustrate FwdLLM's significant advantages over conventional methods, including up to three orders of magnitude faster convergence and a 14.6x reduction in memory footprint. Uniquely, FwdLLM paves the way for federated learning of billion-parameter LLMs such as LLaMA on COTS mobile devices -- a feat previously unattained.
Federated NLP in Few-shot Scenarios
Dec 12, 2022Natural language processing (NLP) sees rich mobile applications. To support various language understanding tasks, a foundation NLP model is often fine-tuned in a federated, privacy-preserving setting (FL). This process currently relies on at least hundreds of thousands of labeled training samples from mobile clients; yet mobile users often lack willingness or knowledge to label their data. Such an inadequacy of data labels is known as a few-shot scenario; it becomes the key blocker for mobile NLP applications. For the first time, this work investigates federated NLP in the few-shot scenario (FedFSL). By retrofitting algorithmic advances of pseudo labeling and prompt learning, we first establish a training pipeline that delivers competitive accuracy when only 0.05% (fewer than 100) of the training data is labeled and the remaining is unlabeled. To instantiate the workflow, we further present a system FFNLP, addressing the high execution cost with novel designs. (1) Curriculum pacing, which injects pseudo labels to the training workflow at a rate commensurate to the learning progress; (2) Representational diversity, a mechanism for selecting the most learnable data, only for which pseudo labels will be generated; (3) Co-planning of a model's training depth and layer capacity. Together, these designs reduce the training delay, client energy, and network traffic by up to 46.0$\times$, 41.2$\times$ and 3000.0$\times$, respectively. Through algorithm/system co-design, FFNLP demonstrates that FL can apply to challenging settings where most training samples are unlabeled.
AUG-FedPrompt: Practical Few-shot Federated NLP with Data-augmented Prompts
Dec 01, 2022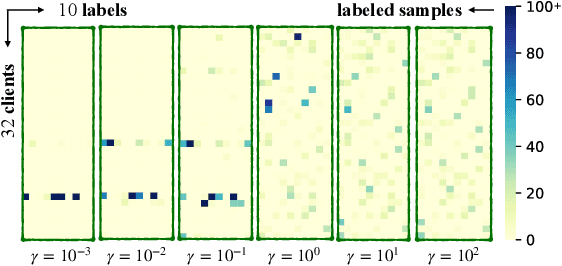

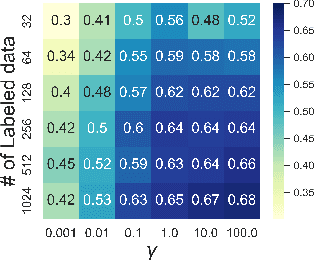

Transformer-based pre-trained models have become the de-facto solution for NLP tasks. Fine-tuning such pre-trained models for downstream tasks often requires tremendous amount of data that is both private and labeled. However, in reality: 1) such private data cannot be collected and is distributed across mobile devices, and 2) well-curated labeled data is scarce. To tackle those issues, we first define a data generator for federated few-shot learning tasks, which encompasses the quantity and distribution of scarce labeled data in a realistic setting. Then we propose AUG-FedPrompt, a prompt-based federated learning algorithm that carefully annotates abundant unlabeled data for data augmentation. AUG-FedPrompt can perform on par with full-set fine-tuning with very few initial labeled data.
AutoFedNLP: An efficient FedNLP framework
May 20, 2022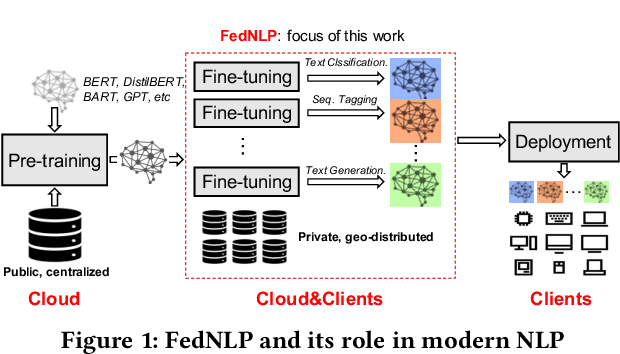
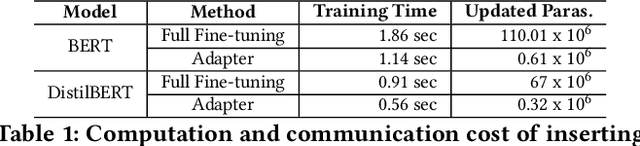
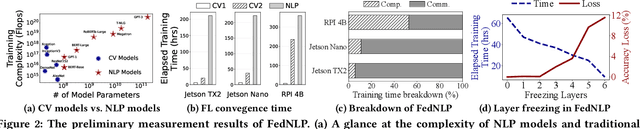

Transformer-based pre-trained models have revolutionized NLP for superior performance and generality. Fine-tuning pre-trained models for downstream tasks often require private data, for which federated learning is the de-facto approach (i.e., FedNLP). However, our measurements show that FedNLP is prohibitively slow due to the large model sizes and the resultant high network/computation cost. Towards practical FedNLP, we identify as the key building blocks adapters, small bottleneck modules inserted at a variety of model layers. A key challenge is to properly configure the depth and width of adapters, to which the training speed and efficiency is highly sensitive. No silver-bullet configuration exists: the optimal choice varies across downstream NLP tasks, desired model accuracy, and client resources. A silver-bullet configuration does not exist and a non-optimal configuration could significantly slow down the training. To automate adapter configuration, we propose AutoFedNLP, a framework that enhances the existing FedNLP with two novel designs. First, AutoFedNLP progressively upgrades the adapter configuration throughout a training session. Second, AutoFedNLP continuously profiles future adapter configurations by allocating participant devices to trial groups. To minimize client-side computations, AutoFedNLP exploits the fact that a FedNLP client trains on the same samples repeatedly between consecutive changes of adapter configurations, and caches computed activations on clients. Extensive experiments show that AutoFedNLP can reduce FedNLP's model convergence delay to no more than several hours, which is up to 155.5$\times$ faster compared to vanilla FedNLP and 48$\times$ faster compared to strong baselines.