 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFedNLP: An efficient FedNLP framework
Paper and Code
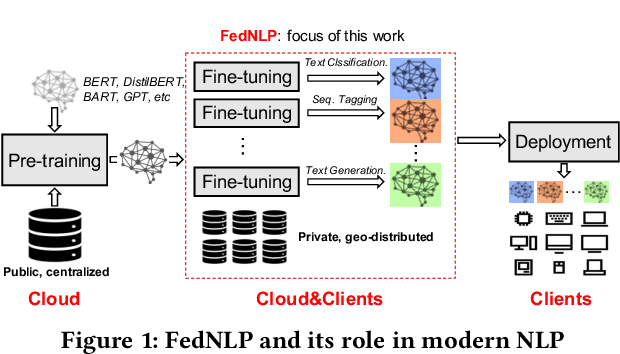
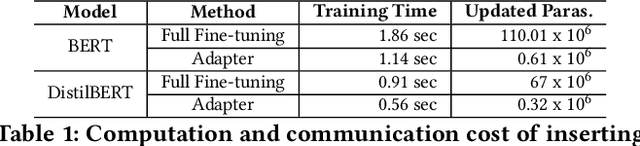
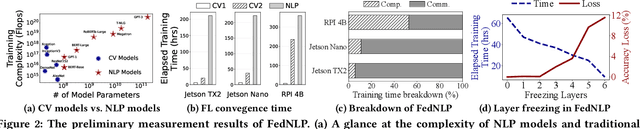

Transformer-based pre-trained models have revolutionized NLP for superior performance and generality. Fine-tuning pre-trained models for downstream tasks often require private data, for which federated learning is the de-facto approach (i.e., FedNLP). However, our measurements show that FedNLP is prohibitively slow due to the large model sizes and the resultant high network/computation cost. Towards practical FedNLP, we identify as the key building blocks adapters, small bottleneck modules inserted at a variety of model layers. A key challenge is to properly configure the depth and width of adapters, to which the training speed and efficiency is highly sensitive. No silver-bullet configuration exists: the optimal choice varies across downstream NLP tasks, desired model accuracy, and client resources. A silver-bullet configuration does not exist and a non-optimal configuration could significantly slow down the training. To automate adapter configuration, we propose AutoFedNLP, a framework that enhances the existing FedNLP with two novel designs. First, AutoFedNLP progressively upgrades the adapter configuration throughout a training session. Second, AutoFedNLP continuously profiles future adapter configurations by allocating participant devices to trial groups. To minimize client-side computations, AutoFedNLP exploits the fact that a FedNLP client trains on the same samples repeatedly between consecutive changes of adapter configurations, and caches computed activations on clients. Extensive experiments show that AutoFedNLP can reduce FedNLP's model convergence delay to no more than several hours, which is up to 155.5$\times$ faster compared to vanilla FedNLP and 48$\times$ faster compared to strong baselines.