 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLER-TTE: An Efficient and Effective Framework for En Route Travel Time Estimation with Reinforcement Learning
Jan 26, 2025



En Route Travel Time Estimation (ER-TTE) aims to learn driving patterns from traveled routes to achieve rapid and accurate real-time predictions. However, existing methods ignore the complexity and dynamism of real-world traffic systems, resulting in significant gaps in efficiency and accuracy in real-time scenarios. Addressing this issue is a critical yet challenging task. This paper proposes a novel framework that redefines the implementation path of ER-TTE to achieve highly efficient and effective predictions. Firstly, we introduce a novel pipeline consisting of a Decision Maker and a Predictor to rectify the inefficient prediction strategies of current methods. The Decision Maker performs efficient real-time decisions to determine whether the high-complexity prediction model in the Predictor needs to be invoked, and the Predictor recalculates the travel time or infers from historical prediction results based on these decisions. Next, to tackle the dynamic and uncertain real-time scenarios, we model the online decision-making problem as a Markov decision process and design an intelligent agent based on reinforcement learning for autonomous decision-making. Moreover, to fully exploit the spatio-temporal correlation between online data and offline data, we meticulously design feature representation and encoding techniques based on the attention mechanism. Finally, to improve the flawed training and evaluation strategies of existing methods, we propose an end-to-end training and evaluation approach, incorporating curriculum learning strategies to manage spatio-temporal data for more advanced training algorithms. Extensive evaluations on three real-world datasets confirm that our method significantly outperforms state-of-the-art solutions in both accuracy and efficiency.
Urban Traffic Accident Risk Prediction Revisited: Regionality, Proximity, Similarity and Sparsity
Jul 29, 2024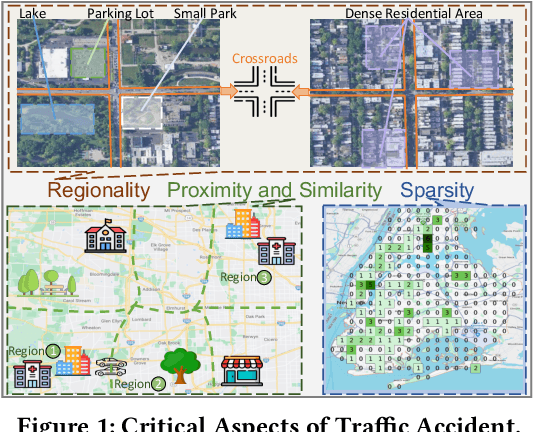
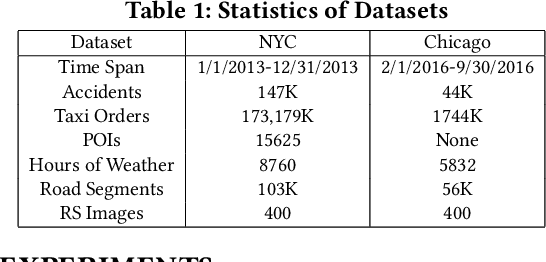
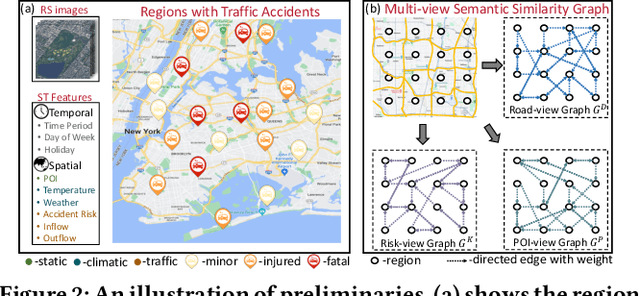
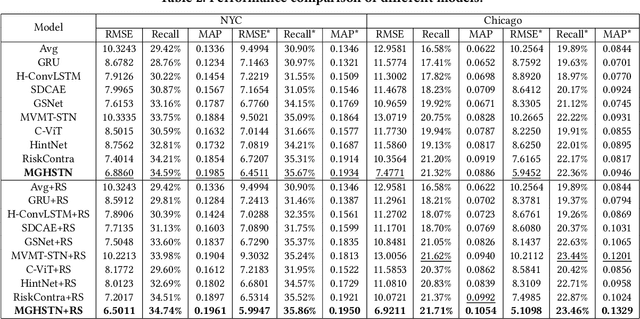
Traffic accidents pose a significant risk to human health and property safety. Therefore, to prevent traffic accidents, predicting their risks has garnered growing interest. We argue that a desired prediction solution should demonstrate resilience to the complexity of traffic accidents. In particular, it should adequately consider the regional background, accurately capture both spatial proximity and semantic similarity, and effectively address the sparsity of traffic accidents. However, these factors are often overlooked or difficult to incorporate. In this paper, we propose a novel multi-granularity hierarchical spatio-temporal network. Initially, we innovate by incorporating remote sensing data, facilitating the creation of hierarchical multi-granularity structure and the comprehension of regional background. We construct multiple high-level risk prediction tasks to enhance model's ability to cope with sparsity. Subsequently, to capture both spatial proximity and semantic similarity, region feature and multi-view graph undergo encoding processes to distill effective representations. Additionally, we propose message passing and adaptive temporal attention module that bridges different granularities and dynamically captures time correlations inherent in traffic accident patterns. At last, a multivariate hierarchical loss function is devised considering the complexity of the prediction purpose. Extensive experiments on two real datasets verify the superiority of our model against the state-of-the-art methods.
STMGF: An Effective Spatial-Temporal Multi-Granularity Framework for Traffic Forecasting
Apr 08, 2024



Accurate Traffic Prediction is a challenging task in intelligent transportation due to the spatial-temporal aspects of road networks. The traffic of a road network can be affected by long-distance or long-term dependencies where existing methods fall short in modeling them. In this paper, we introduce a novel framework known as Spatial-Temporal Multi-Granularity Framework (STMGF) to enhance the capture of long-distance and long-term information of the road networks. STMGF makes full use of different granularity information of road networks and models the long-distance and long-term information by gathering information in a hierarchical interactive way. Further, it leverages the inherent periodicity in traffic sequences to refine prediction results by matching with recent traffic data. We conduct experiments on two real-world datasets, and the results demonstrate that STMGF outperforms all baseline models and achieves state-of-the-art performance.
Towards Effective Next POI Prediction: Spatial and Semantic Augmentation with Remote Sensing Data
Mar 22, 2024



The next point-of-interest (POI) prediction is a significant task in location-based services, yet its complexity arises from the consolidation of spatial and semantic intent. This fusion is subject to the influences of historical preferences, prevailing location, and environmental factors, thereby posing significant challenges. In addition, the uneven POI distribution further complicates the next POI prediction procedure. To address these challenges, we enrich input features and propose an effective deep-learning method within a two-step prediction framework. Our method first incorporates remote sensing data, capturing pivotal environmental context to enhance input features regarding both location and semantics. Subsequently, we employ a region quad-tree structure to integrate urban remote sensing, road network, and POI distribution spaces, aiming to devise a more coherent graph representation method for urban spatial. Leveraging this method, we construct the QR-P graph for the user's historical trajectories to encapsulate historical travel knowledge, thereby augmenting input features with comprehensive spatial and semantic insights. We devise distinct embedding modules to encode these features and employ an attention mechanism to fuse diverse encodings. In the two-step prediction procedure, we initially identify potential spatial zones by predicting user-preferred tiles, followed by pinpointing specific POIs of a designated type within the projected tiles. Empirical findings from four real-world location-based social network datasets underscore the remarkable superiority of our proposed approach over competitive baseline methods.