 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisorientLiDAR: Physical Attacks on LiDAR-based Localization
Sep 16, 2025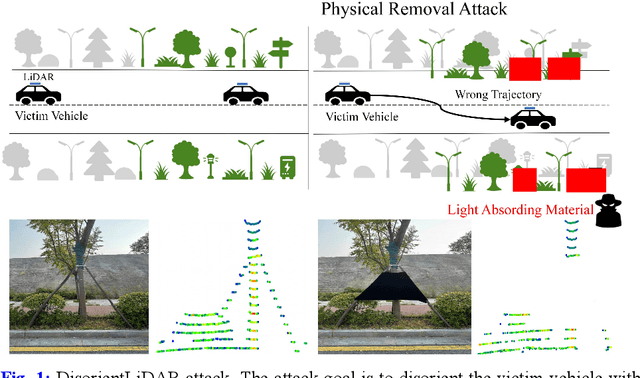
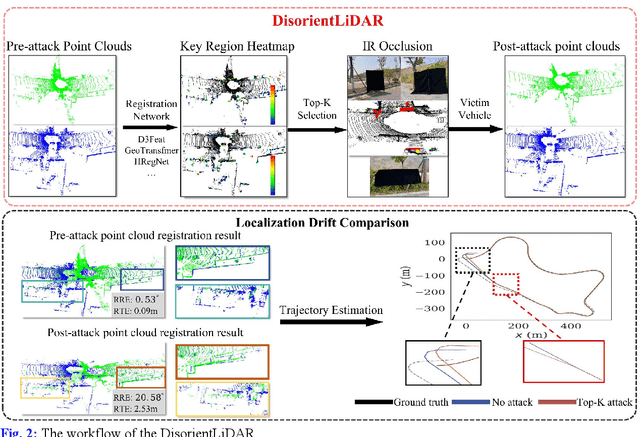
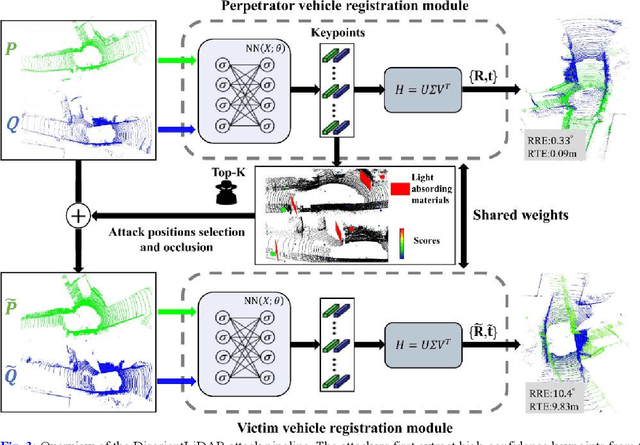
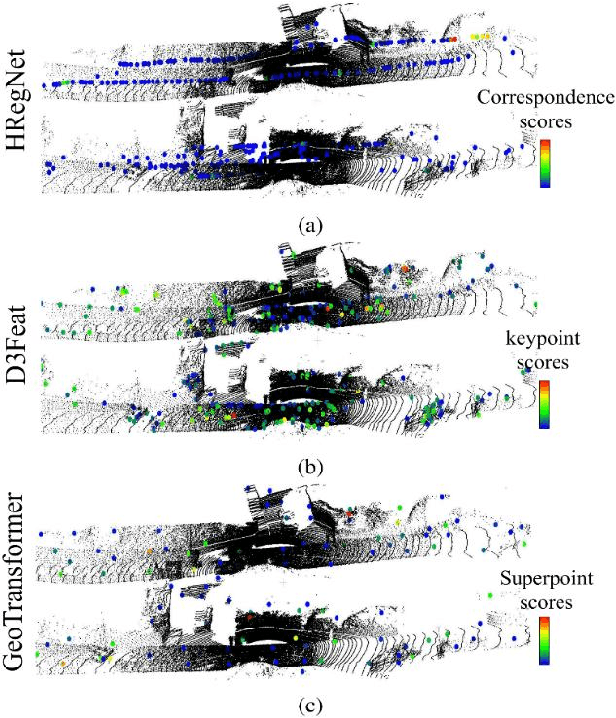
Deep learning models have been shown to be susceptible to adversarial attacks with visually imperceptible perturbations. Even this poses a serious security challenge for the localization of self-driving cars, there has been very little exploration of attack on it, as most of adversarial attacks have been applied to 3D perception. In this work, we propose a novel adversarial attack framework called DisorientLiDAR targeting LiDAR-based localization. By reverse-engineering localization models (e.g., feature extraction networks), adversaries can identify critical keypoints and strategically remove them, thereby disrupting LiDAR-based localization. Our proposal is first evaluated on three state-of-the-art point-cloud registration models (HRegNet, D3Feat, and GeoTransformer) using the KITTI dataset. Experimental results demonstrate that removing regions containing Top-K keypoints significantly degrades their registration accuracy. We further validate the attack's impact on the Autoware autonomous driving platform, where hiding merely a few critical regions induces noticeable localization drift. Finally, we extended our attacks to the physical world by hiding critical regions with near-infrared absorptive materials, thereby successfully replicate the attack effects observed in KITTI data. This step has been closer toward the realistic physical-world attack that demonstrate the veracity and generality of our proposal.
CORAG: A Cost-Constrained Retrieval Optimization System for Retrieval-Augmented Generation
Nov 01, 2024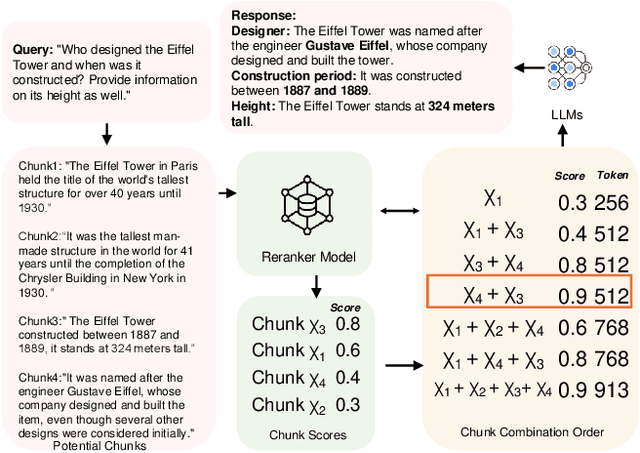

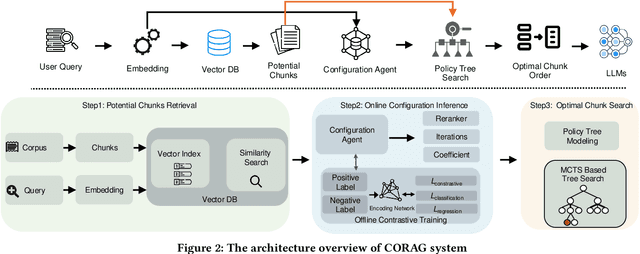
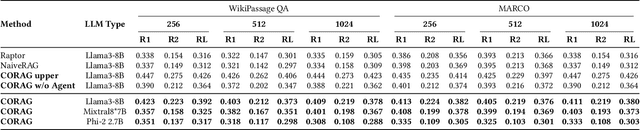
Large Language Models (LLMs) have demonstrated remarkable generation capabilities but often struggle to access up-to-date information, which can lead to hallucinations. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating knowledge from external databases, enabling more accurate and relevant responses. Due to the context window constraints of LLMs, it is impractical to input the entire external database context directly into the model. Instead, only the most relevant information, referred to as chunks, is selectively retrieved. However, current RAG research faces three key challenges. First, existing solutions often select each chunk independently, overlooking potential correlations among them. Second, in practice the utility of chunks is non-monotonic, meaning that adding more chunks can decrease overall utility. Traditional methods emphasize maximizing the number of included chunks, which can inadvertently compromise performance. Third, each type of user query possesses unique characteristics that require tailored handling, an aspect that current approaches do not fully consider. To overcome these challenges, we propose a cost constrained retrieval optimization system CORAG for retrieval-augmented generation. We employ a Monte Carlo Tree Search (MCTS) based policy framework to find optimal chunk combinations sequentially, allowing for a comprehensive consideration of correlations among chunks. Additionally, rather than viewing budget exhaustion as a termination condition, we integrate budget constraints into the optimization of chunk combinations, effectively addressing the non-monotonicity of chunk utility.