 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
CORD: Bridging the Audio-Text Reasoning Gap via Weighted On-policy Cross-modal Distillation
Jan 23, 2026Large Audio Language Models (LALMs) have garnered significant research interest. Despite being built upon text-based large language models (LLMs), LALMs frequently exhibit a degradation in knowledge and reasoning capabilities. We hypothesize that this limitation stems from the failure of current training paradigms to effectively bridge the acoustic-semantic gap within the feature representation space. To address this challenge, we propose CORD, a unified alignment framework that performs online cross-modal self-distillation. Specifically, it aligns audio-conditioned reasoning with its text-conditioned counterpart within a unified model. Leveraging the text modality as an internal teacher, CORD performs multi-granularity alignment throughout the audio rollout process. At the token level, it employs on-policy reverse KL divergence with importance-aware weighting to prioritize early and semantically critical tokens. At the sequence level, CORD introduces a judge-based global reward to optimize complete reasoning trajectories via Group Relative Policy Optimization (GRPO). Empirical results across multiple benchmarks demonstrate that CORD consistently enhances audio-conditioned reasoning and substantially bridges the audio-text performance gap with only 80k synthetic training samples, validating the efficacy and data efficiency of our on-policy, multi-level cross-modal alignment approach.
MoE Adapter for Large Audio Language Models: Sparsity, Disentanglement, and Gradient-Conflict-Free
Jan 08, 2026Extending the input modality of Large Language Models~(LLMs) to the audio domain is essential for achieving comprehensive multimodal perception. However, it is well-known that acoustic information is intrinsically \textit{heterogeneous}, entangling attributes such as speech, music, and environmental context. Existing research is limited to a dense, parameter-shared adapter to model these diverse patterns, which induces \textit{gradient conflict} during optimization, as parameter updates required for distinct attributes contradict each other. To address this limitation, we introduce the \textit{\textbf{MoE-Adapter}}, a sparse Mixture-of-Experts~(MoE) architecture designed to decouple acoustic information. Specifically, it employs a dynamic gating mechanism that routes audio tokens to specialized experts capturing complementary feature subspaces while retaining shared experts for global context, thereby mitigating gradient conflicts and enabling fine-grained feature learning. Comprehensive experiments show that the MoE-Adapter achieves superior performance on both audio semantic and paralinguistic tasks, consistently outperforming dense linear baselines with comparable computational costs. Furthermore, we will release the related code and models to facilitate future research.
ERNIE: Enhanced Representation through Knowledge Integration
Apr 19, 2019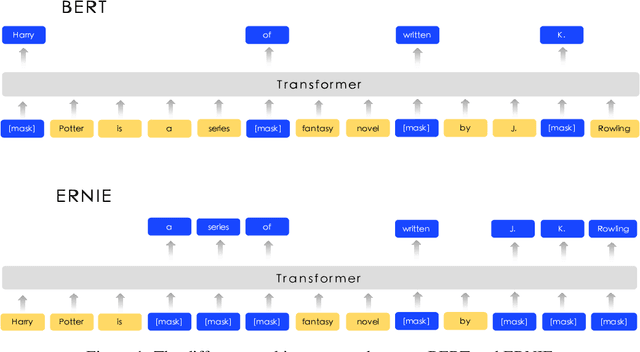
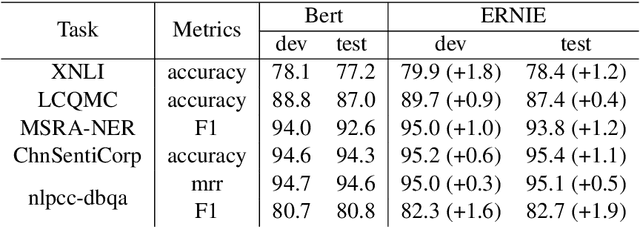

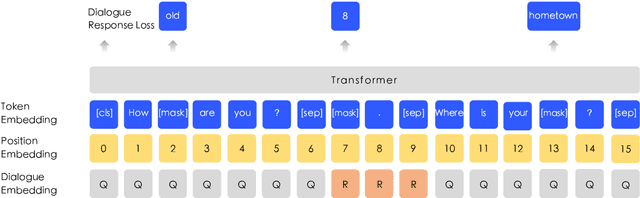
We present a novel language representation model enhanced by knowledge called ERNIE (Enhanced Representation through kNowledge IntEgration). Inspired by the masking strategy of BERT, ERNIE is designed to learn language representation enhanced by knowledge masking strategies, which includes entity-level masking and phrase-level masking. Entity-level strategy masks entities which are usually composed of multiple words.Phrase-level strategy masks the whole phrase which is composed of several words standing together as a conceptual unit.Experimental results show that ERNIE outperforms other baseline methods, achieving new state-of-the-art results on five Chinese natural language processing tasks including natural language inference, semantic similarity, named entity recognition, sentiment analysis and question answering. We also demonstrate that ERNIE has more powerful knowledge inference capacity on a cloze test.