 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Learning for Dialogue State Tracking
Paper and Code
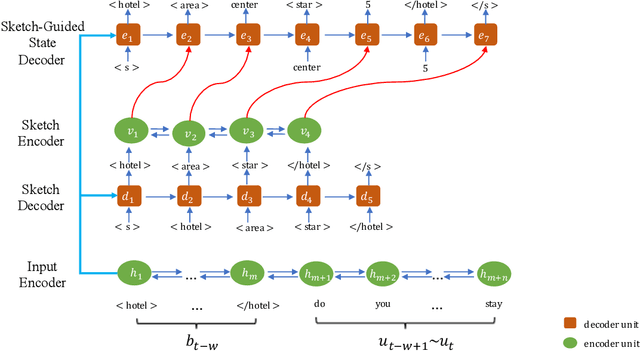
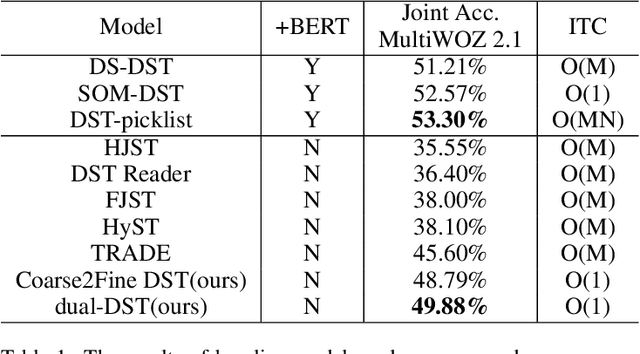
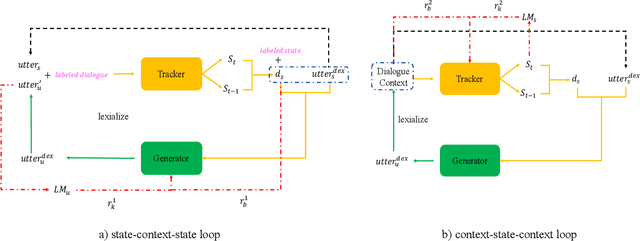
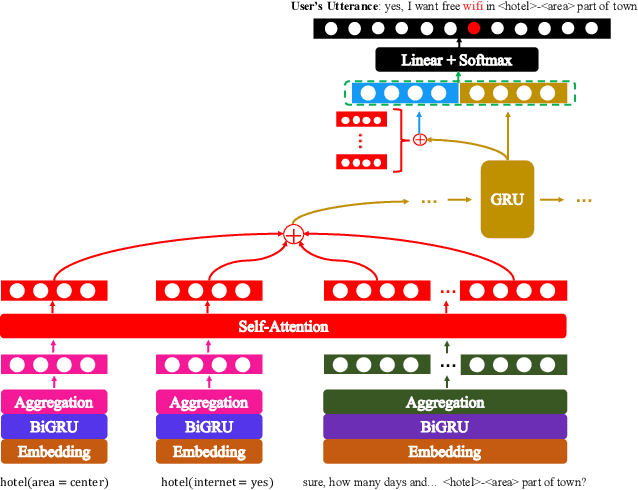
In task-oriented multi-turn dialogue systems, dialogue state refers to a compact representation of the user goal in the context of dialogue history. Dialogue state tracking (DST) is to estimate the dialogue state at each turn. Due to the dependency on complicated dialogue history contexts, DST data annotation is more expensive than single-sentence language understanding, which makes the task more challenging. In this work, we formulate DST as a sequence generation problem and propose a novel dual-learning framework to make full use of unlabeled data. In the dual-learning framework, there are two agents: the primal tracker agent (utterance-to-state generator) and the dual utterance generator agent (state-to-utterance genera-tor). Compared with traditional supervised learning framework, dual learning can iteratively update both agents through the reconstruction error and reward signal respectively without labeled data. Reward sparsity problem is hard to solve in previous DST methods. In this work, the reformulation of DST as a sequence generation model effectively alleviates this problem. We call this primal tracker agent dual-DST. Experimental results on MultiWOZ2.1 dataset show that the proposed dual-DST works very well, especially when labelled data is limited. It achieves comparable performance to the system where labeled data is fully used.