 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCREDIT: Coarse-to-Fine Sequence Generation for Dialogue State Tracking
Paper and Code
Sep 22, 2020

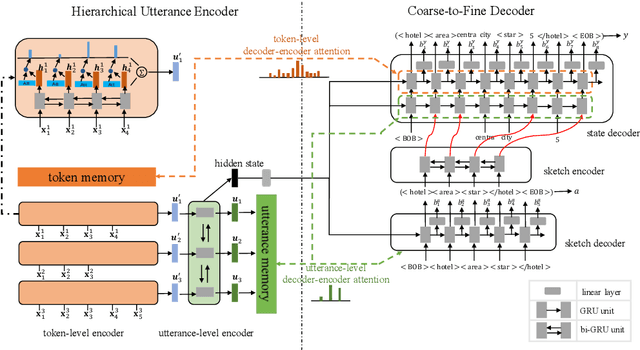
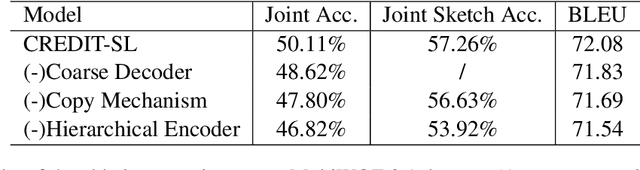
In dialogue systems, a dialogue state tracker aims to accurately find a compact representation of the current dialogue status, based on the entire dialogue history. While previous approaches often define dialogue states as a combination of separate triples ({\em domain-slot-value}), in this paper, we employ a structured state representation and cast dialogue state tracking as a sequence generation problem. Based on this new formulation, we propose a {\bf C}oa{\bf R}s{\bf E}-to-fine {\bf DI}alogue state {\bf T}racking ({\bf CREDIT}) approach. Taking advantage of the structured state representation, which is a marked language sequence, we can further fine-tune the pre-trained model (by supervised learning) by optimizing natural language metrics with the policy gradient method. Like all generative state tracking methods, CREDIT does not rely on pre-defined dialogue ontology enumerating all possible slot values. Experiments demonstrate our tracker achieves encouraging joint goal accuracy for the five domains in MultiWOZ 2.0 and MultiWOZ 2.1 datasets.