 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCCSBench: Evaluating Compositional Controllability in LLMs for Scientific Document Summarization
Paper and Code
Oct 16, 2024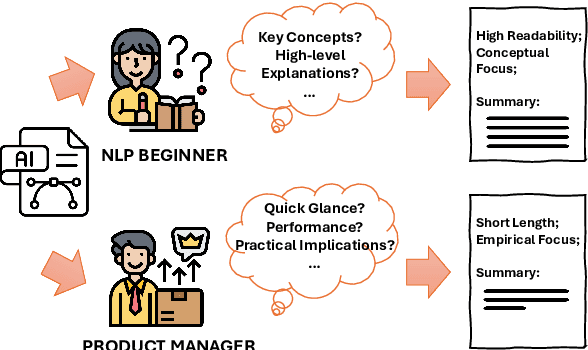
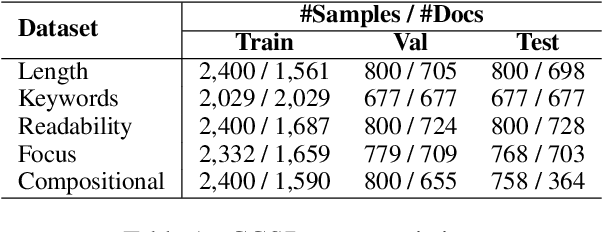
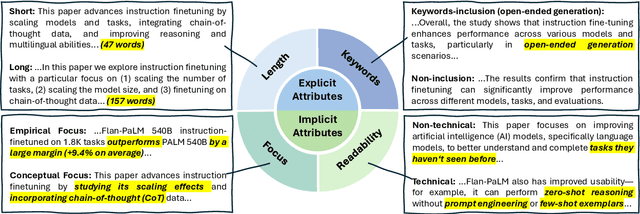

To broaden the dissemination of scientific knowledge to diverse audiences, scientific document summarization must simultaneously control multiple attributes such as length and empirical focus. However, existing research typically focuses on controlling single attributes, leaving the compositional control of multiple attributes underexplored. To address this gap, we introduce CCSBench, a benchmark for compositional controllable summarization in the scientific domain. Our benchmark enables fine-grained control over both explicit attributes (e.g., length), which are objective and straightforward, and implicit attributes (e.g., empirical focus), which are more subjective and conceptual. We conduct extensive experiments on GPT-4, LLaMA2, and other popular LLMs under various settings. Our findings reveal significant limitations in large language models' ability to balance trade-offs between control attributes, especially implicit ones that require deeper understanding and abstract reasoning.