 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Robustness of Subtask Distillation under Spurious Correlation
Jan 31, 2026Subtask distillation is an emerging paradigm in which compact, specialized models are extracted from large, general-purpose 'foundation models' for deployment in environments with limited resources or in standalone computer systems. Although distillation uses a teacher model, it still relies on a dataset that is often limited in size and may lack representativeness or exhibit spurious correlations. In this paper, we evaluate established distillation methods, as well as the recent SubDistill method, when using data with spurious correlations for distillation. As the strength of the correlations increases, we observe a widening gap between advanced methods, such as SubDistill, which remain fairly robust, and some baseline methods, which degrade to near-random performance. Overall, our study underscores the challenges of knowledge distillation when applied to imperfect, real-world datasets, particularly those with spurious correlations.
Distilling Lightweight Domain Experts from Large ML Models by Identifying Relevant Subspaces
Jan 09, 2026Knowledge distillation involves transferring the predictive capabilities of large, high-performing AI models (teachers) to smaller models (students) that can operate in environments with limited computing power. In this paper, we address the scenario in which only a few classes and their associated intermediate concepts are relevant to distill. This scenario is common in practice, yet few existing distillation methods explicitly focus on the relevant subtask. To address this gap, we introduce 'SubDistill', a new distillation algorithm with improved numerical properties that only distills the relevant components of the teacher model at each layer. Experiments on CIFAR-100 and ImageNet with Convolutional and Transformer models demonstrate that SubDistill outperforms existing layer-wise distillation techniques on a representative set of subtasks. Our benchmark evaluations are complemented by Explainable AI analyses showing that our distilled student models more closely match the decision structure of the original teacher model.
PyThaiNLP: Thai Natural Language Processing in Python
Dec 07, 2023
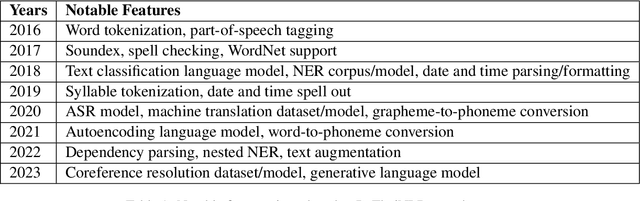
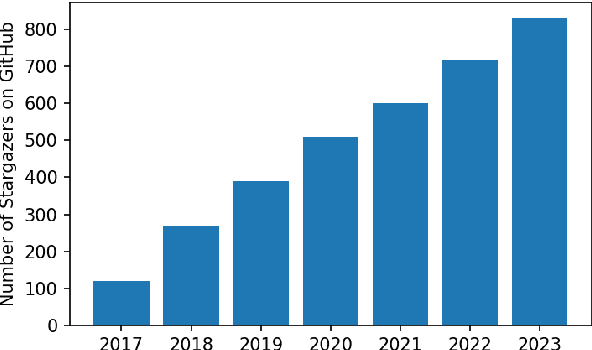
We present PyThaiNLP, a free and open-source natural language processing (NLP) library for Thai language implemented in Python. It provides a wide range of software, models, and datasets for Thai language. We first provide a brief historical context of tools for Thai language prior to the development of PyThaiNLP. We then outline the functionalities it provided as well as datasets and pre-trained language models. We later summarize its development milestones and discuss our experience during its development. We conclude by demonstrating how industrial and research communities utilize PyThaiNLP in their work. The library is freely available at https://github.com/pythainlp/pythainlp.
Disentangled Explanations of Neural Network Predictions by Finding Relevant Subspaces
Dec 30, 2022



Explainable AI transforms opaque decision strategies of ML models into explanations that are interpretable by the user, for example, identifying the contribution of each input feature to the prediction at hand. Such explanations, however, entangle the potentially multiple factors that enter into the overall complex decision strategy. We propose to disentangle explanations by finding relevant subspaces in activation space that can be mapped to more abstract human-understandable concepts and enable a joint attribution on concepts and input features. To automatically extract the desired representation, we propose new subspace analysis formulations that extend the principle of PCA and subspace analysis to explanations. These novel analyses, which we call principal relevant component analysis (PRCA) and disentangled relevant subspace analysis (DRSA), optimize relevance of projected activations rather than the more traditional variance or kurtosis. This enables a much stronger focus on subspaces that are truly relevant for the prediction and the explanation, in particular, ignoring activations or concepts to which the prediction model is invariant. Our approach is general enough to work alongside common attribution techniques such as Shapley Value, Integrated Gradients, or LRP. Our proposed methods show to be practically useful and compare favorably to the state of the art as demonstrated on benchmarks and three use cases.
AttaCut: A Fast and Accurate Neural Thai Word Segmenter
Nov 16, 2019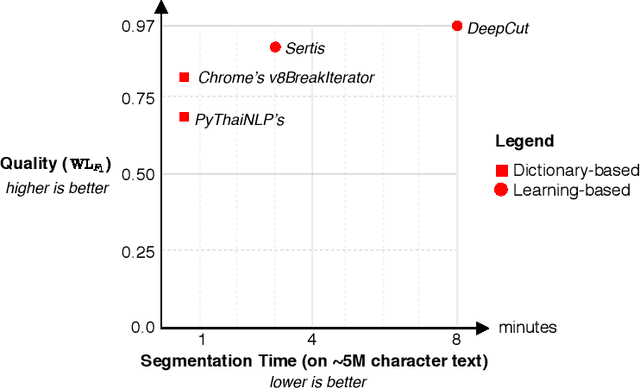

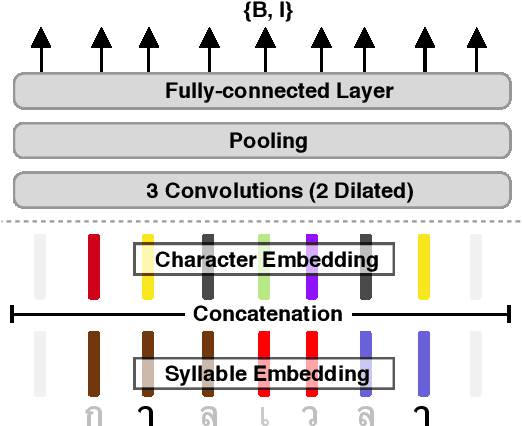

Word segmentation is a fundamental pre-processing step for Thai Natural Language Processing. The current off-the-shelf solutions are not benchmarked consistently, so it is difficult to compare their trade-offs. We conducted a speed and accuracy comparison of the popular systems on three different domains and found that the state-of-the-art deep learning system is slow and moreover does not use sub-word structures to guide the model. Here, we propose a fast and accurate neural Thai Word Segmenter that uses dilated CNN filters to capture the environment of each character and uses syllable embeddings as features. Our system runs at least 5.6x faster and outperforms the previous state-of-the-art system on some domains. In addition, we develop the first ML-based Thai orthographical syllable segmenter, which yields syllable embeddings to be used as features by the word segmenter.