 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Language Bias in Cross-Lingual Job Retrieval: A Recruitment Platform Perspective
Feb 05, 2025Understanding the textual components of resumes and job postings is critical for improving job-matching accuracy and optimizing job search systems in online recruitment platforms. However, existing works primarily focus on analyzing individual components within this information, requiring multiple specialized tools to analyze each aspect. Such disjointed methods could potentially hinder overall generalizability in recruitment-related text processing. Therefore, we propose a unified sentence encoder that utilized multi-task dual-encoder framework for jointly learning multiple component into the unified sentence encoder. The results show that our method outperforms other state-of-the-art models, despite its smaller model size. Moreover, we propose a novel metric, Language Bias Kullback-Leibler Divergence (LBKL), to evaluate language bias in the encoder, demonstrating significant bias reduction and superior cross-lingual performance.
AyutthayaAlpha: A Thai-Latin Script Transliteration Transformer
Dec 05, 2024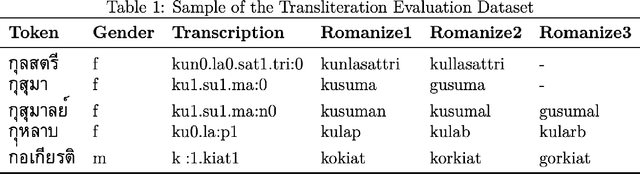
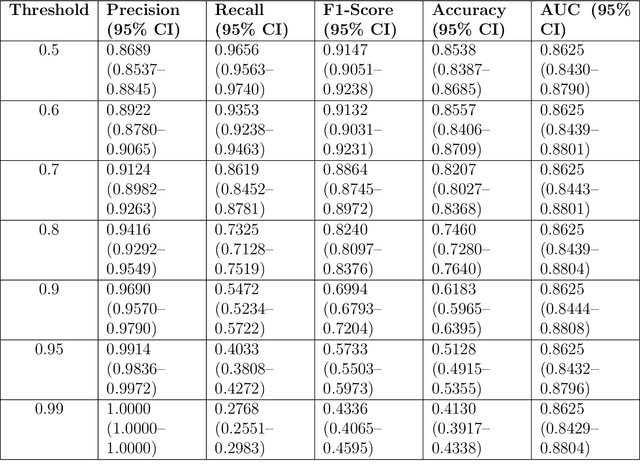
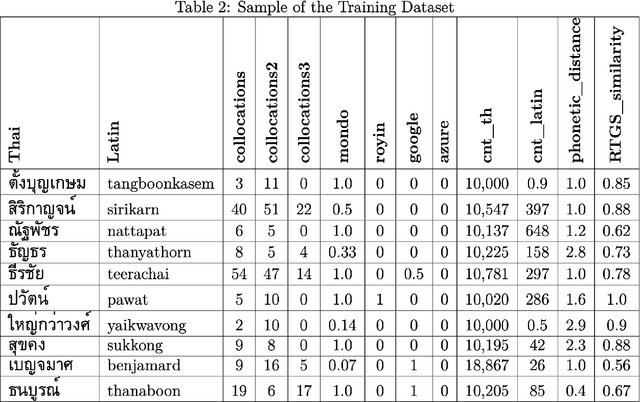
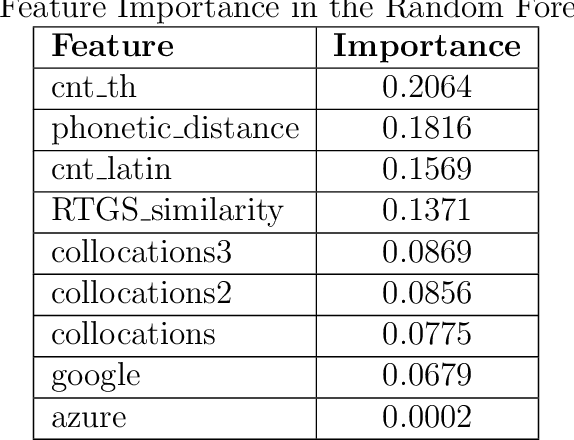
This study introduces AyutthayaAlpha, an advanced transformer-based machine learning model designed for the transliteration of Thai proper names into Latin script. Our system achieves state-of-the-art performance with 82.32% first-token accuracy and 95.24% first-three-token accuracy, while maintaining a low character error rate of 0.0047. The complexity of Thai phonology, including tonal features and vowel length distinctions, presents significant challenges for accurate transliteration, which we address through a novel two-model approach: AyutthayaAlpha-Small, based on the ByT5 architecture, and AyutthayaAlpha-VerySmall, a computationally efficient variant that unexpectedly outperforms its larger counterpart. Our research combines linguistic rules with deep learning, training on a carefully curated dataset of 1.2 million Thai-Latin name pairs, augmented through strategic upsampling to 2.7 million examples. Extensive evaluations against existing transliteration methods and human expert benchmarks demonstrate that AyutthayaAlpha not only achieves superior accuracy but also effectively captures personal and cultural preferences in name romanization. The system's practical applications extend to cross-lingual information retrieval, international data standardization, and identity verification systems, with particular relevance for government databases, academic institutions, and global business operations. This work represents a significant advance in bridging linguistic gaps between Thai and Latin scripts, while respecting the cultural and personal dimensions of name transliteration.
Representing the Under-Represented: Cultural and Core Capability Benchmarks for Developing Thai Large Language Models
Oct 07, 2024



The rapid advancement of large language models (LLMs) has highlighted the need for robust evaluation frameworks that assess their core capabilities, such as reasoning, knowledge, and commonsense, leading to the inception of certain widely-used benchmark suites such as the H6 benchmark. However, these benchmark suites are primarily built for the English language, and there exists a lack thereof for under-represented languages, in terms of LLM development, such as Thai. On the other hand, developing LLMs for Thai should also include enhancing the cultural understanding as well as core capabilities. To address these dual challenge in Thai LLM research, we propose two key benchmarks: Thai-H6 and Thai Cultural and Linguistic Intelligence Benchmark (ThaiCLI). Through a thorough evaluation of various LLMs with multi-lingual capabilities, we provide a comprehensive analysis of the proposed benchmarks and how they contribute to Thai LLM development. Furthermore, we will make both the datasets and evaluation code publicly available to encourage further research and development for Thai LLMs.
Learning Job Title Representation from Job Description Aggregation Network
Jun 12, 2024



Learning job title representation is a vital process for developing automatic human resource tools. To do so, existing methods primarily rely on learning the title representation through skills extracted from the job description, neglecting the rich and diverse content within. Thus, we propose an alternative framework for learning job titles through their respective job description (JD) and utilize a Job Description Aggregator component to handle the lengthy description and bidirectional contrastive loss to account for the bidirectional relationship between the job title and its description. We evaluated the performance of our method on both in-domain and out-of-domain settings, achieving a superior performance over the skill-based approach.
AttaCut: A Fast and Accurate Neural Thai Word Segmenter
Nov 16, 2019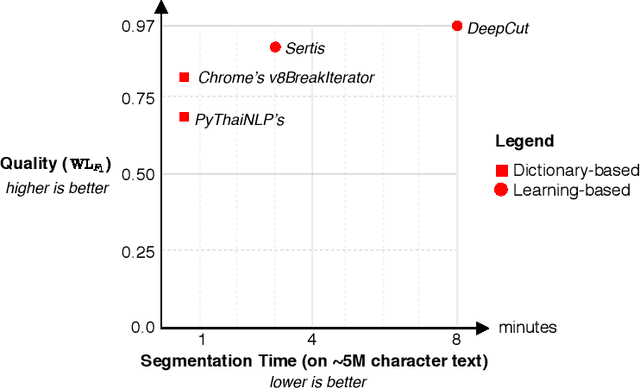

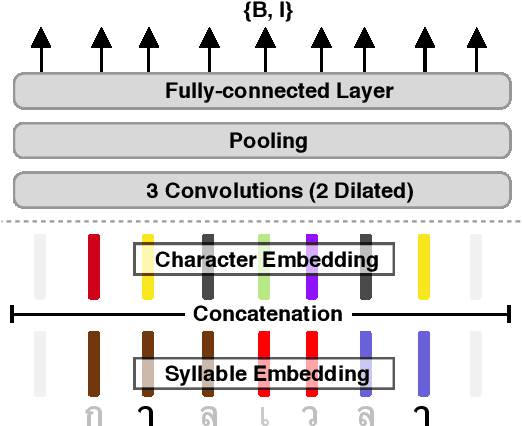

Word segmentation is a fundamental pre-processing step for Thai Natural Language Processing. The current off-the-shelf solutions are not benchmarked consistently, so it is difficult to compare their trade-offs. We conducted a speed and accuracy comparison of the popular systems on three different domains and found that the state-of-the-art deep learning system is slow and moreover does not use sub-word structures to guide the model. Here, we propose a fast and accurate neural Thai Word Segmenter that uses dilated CNN filters to capture the environment of each character and uses syllable embeddings as features. Our system runs at least 5.6x faster and outperforms the previous state-of-the-art system on some domains. In addition, we develop the first ML-based Thai orthographical syllable segmenter, which yields syllable embeddings to be used as features by the word segmenter.