 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multilingual Name Type Classification Using Convolutional Networks
Jan 16, 2026We present a convolutional neural network approach for classifying proper names by language and entity type. Our model, Onomas-CNN X, combines parallel convolution branches with depthwise-separable operations and hierarchical classification to process names efficiently on CPU hardware. We evaluate the architecture on a large multilingual dataset covering 104 languages and four entity types (person, organization, location, other). Onomas-CNN X achieves 92.1% accuracy while processing 2,813 names per second on a single CPU core - 46 times faster than fine-tuned XLM-RoBERTa with comparable accuracy. The model reduces energy consumption by a factor of 46 compared to transformer baselines. Our experiments demonstrate that specialized CNN architectures remain competitive with large pre-trained models for focused NLP tasks when sufficient training data exists.
PolyIPA -- Multilingual Phoneme-to-Grapheme Conversion Model
Dec 12, 2024This paper presents PolyIPA, a novel multilingual phoneme-to-grapheme conversion model designed for multilingual name transliteration, onomastic research, and information retrieval. The model leverages two helper models developed for data augmentation: IPA2vec for finding soundalikes across languages, and similarIPA for handling phonetic notation variations. Evaluated on a test set that spans multiple languages and writing systems, the model achieves a mean Character Error Rate of 0.055 and a character-level BLEU score of 0.914, with particularly strong performance on languages with shallow orthographies. The implementation of beam search further improves practical utility, with top-3 candidates reducing the effective error rate by 52.7\% (to CER: 0.026), demonstrating the model's effectiveness for cross-linguistic applications.
AyutthayaAlpha: A Thai-Latin Script Transliteration Transformer
Dec 05, 2024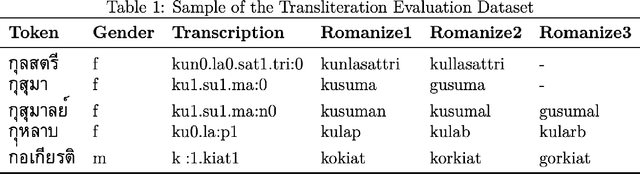
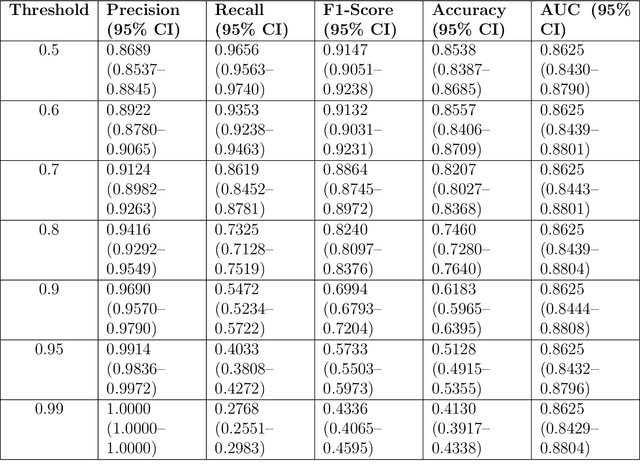
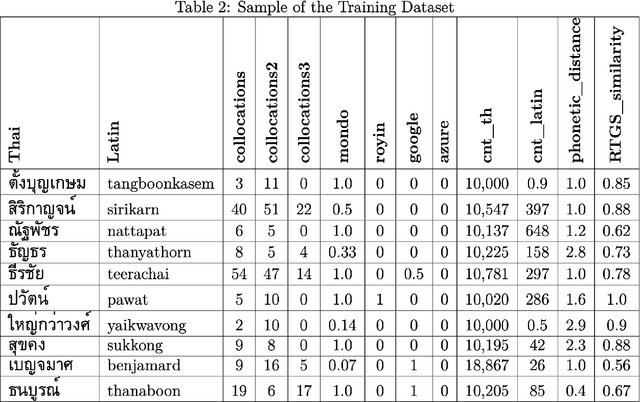
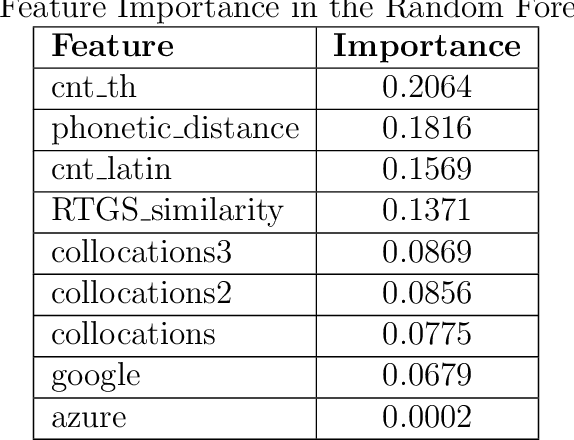
This study introduces AyutthayaAlpha, an advanced transformer-based machine learning model designed for the transliteration of Thai proper names into Latin script. Our system achieves state-of-the-art performance with 82.32% first-token accuracy and 95.24% first-three-token accuracy, while maintaining a low character error rate of 0.0047. The complexity of Thai phonology, including tonal features and vowel length distinctions, presents significant challenges for accurate transliteration, which we address through a novel two-model approach: AyutthayaAlpha-Small, based on the ByT5 architecture, and AyutthayaAlpha-VerySmall, a computationally efficient variant that unexpectedly outperforms its larger counterpart. Our research combines linguistic rules with deep learning, training on a carefully curated dataset of 1.2 million Thai-Latin name pairs, augmented through strategic upsampling to 2.7 million examples. Extensive evaluations against existing transliteration methods and human expert benchmarks demonstrate that AyutthayaAlpha not only achieves superior accuracy but also effectively captures personal and cultural preferences in name romanization. The system's practical applications extend to cross-lingual information retrieval, international data standardization, and identity verification systems, with particular relevance for government databases, academic institutions, and global business operations. This work represents a significant advance in bridging linguistic gaps between Thai and Latin scripts, while respecting the cultural and personal dimensions of name transliteration.
BERTić -- The Transformer Language Model for Bosnian, Croatian, Montenegrin and Serbian
Apr 19, 2021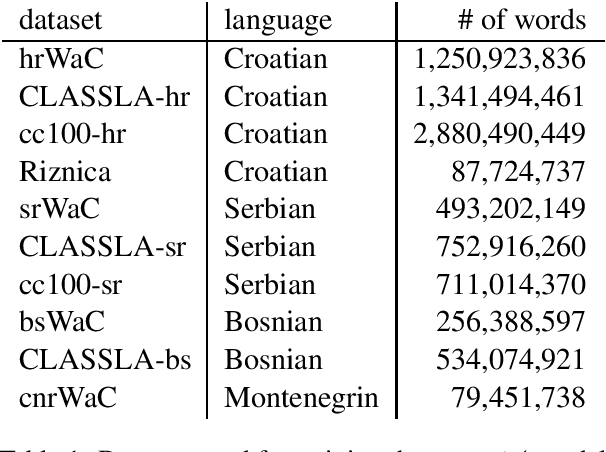


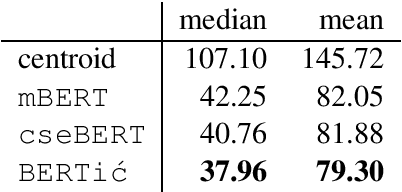
In this paper we describe a transformer model pre-trained on 8 billion tokens of crawled text from the Croatian, Bosnian, Serbian and Montenegrin web domains. We evaluate the transformer model on the tasks of part-of-speech tagging, named-entity-recognition, geo-location prediction and commonsense causal reasoning, showing improvements on all tasks over state-of-the-art models. For commonsense reasoning evaluation, we introduce COPA-HR -- a translation of the Choice of Plausible Alternatives (COPA) dataset into Croatian. The BERTi\'c model is made available for free usage and further task-specific fine-tuning through HuggingFace.