 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWangchanThaiInstruct: An instruction-following Dataset for Culture-Aware, Multitask, and Multi-domain Evaluation in Thai
Aug 21, 2025Large language models excel at instruction-following in English, but their performance in low-resource languages like Thai remains underexplored. Existing benchmarks often rely on translations, missing cultural and domain-specific nuances needed for real-world use. We present WangchanThaiInstruct, a human-authored Thai dataset for evaluation and instruction tuning, covering four professional domains and seven task types. Created through a multi-stage quality control process with annotators, domain experts, and AI researchers, WangchanThaiInstruct supports two studies: (1) a zero-shot evaluation showing performance gaps on culturally and professionally specific tasks, and (2) an instruction tuning study with ablations isolating the effect of native supervision. Models fine-tuned on WangchanThaiInstruct outperform those using translated data in both in-domain and out-of-domain benchmarks. These findings underscore the need for culturally and professionally grounded instruction data to improve LLM alignment in low-resource, linguistically diverse settings.
PyThaiNLP: Thai Natural Language Processing in Python
Dec 07, 2023
We present PyThaiNLP, a free and open-source natural language processing (NLP) library for Thai language implemented in Python. It provides a wide range of software, models, and datasets for Thai language. We first provide a brief historical context of tools for Thai language prior to the development of PyThaiNLP. We then outline the functionalities it provided as well as datasets and pre-trained language models. We later summarize its development milestones and discuss our experience during its development. We conclude by demonstrating how industrial and research communities utilize PyThaiNLP in their work. The library is freely available at https://github.com/pythainlp/pythainlp.
An Efficient Self-Supervised Cross-View Training For Sentence Embedding
Nov 06, 2023Self-supervised sentence representation learning is the task of constructing an embedding space for sentences without relying on human annotation efforts. One straightforward approach is to finetune a pretrained language model (PLM) with a representation learning method such as contrastive learning. While this approach achieves impressive performance on larger PLMs, the performance rapidly degrades as the number of parameters decreases. In this paper, we propose a framework called Self-supervised Cross-View Training (SCT) to narrow the performance gap between large and small PLMs. To evaluate the effectiveness of SCT, we compare it to 5 baseline and state-of-the-art competitors on seven Semantic Textual Similarity (STS) benchmarks using 5 PLMs with the number of parameters ranging from 4M to 340M. The experimental results show that STC outperforms the competitors for PLMs with less than 100M parameters in 18 of 21 cases.
WangchanBERTa: Pretraining transformer-based Thai Language Models
Jan 24, 2021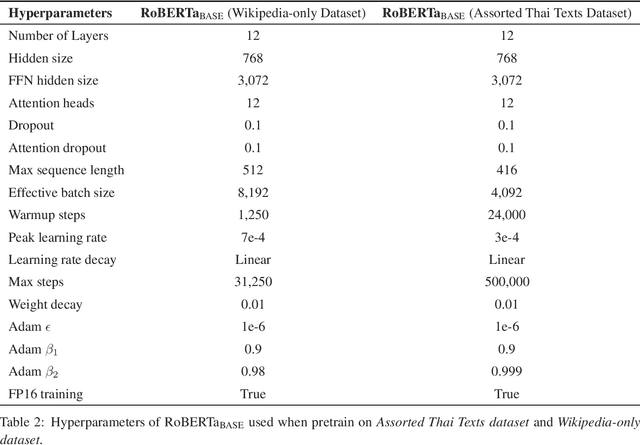
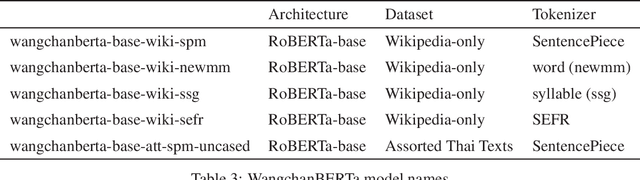
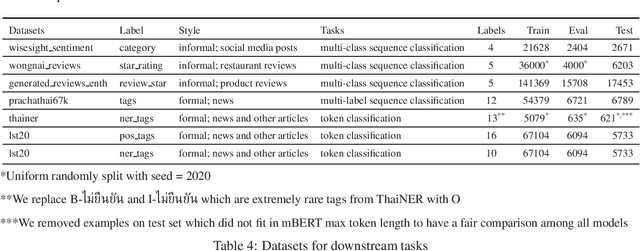
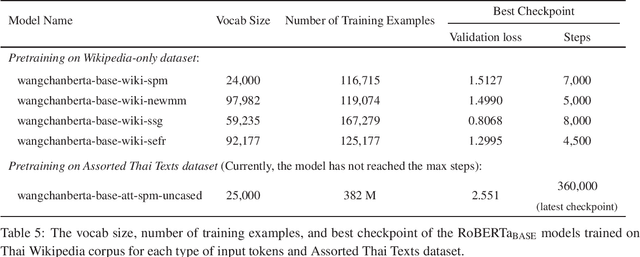
Transformer-based language models, more specifically BERT-based architectures have achieved state-of-the-art performance in many downstream tasks. However, for a relatively low-resource language such as Thai, the choices of models are limited to training a BERT-based model based on a much smaller dataset or finetuning multi-lingual models, both of which yield suboptimal downstream performance. Moreover, large-scale multi-lingual pretraining does not take into account language-specific features for Thai. To overcome these limitations, we pretrain a language model based on RoBERTa-base architecture on a large, deduplicated, cleaned training set (78GB in total size), curated from diverse domains of social media posts, news articles and other publicly available datasets. We apply text processing rules that are specific to Thai most importantly preserving spaces, which are important chunk and sentence boundaries in Thai before subword tokenization. We also experiment with word-level, syllable-level and SentencePiece tokenization with a smaller dataset to explore the effects on tokenization on downstream performance. Our model wangchanberta-base-att-spm-uncased trained on the 78.5GB dataset outperforms strong baselines (NBSVM, CRF and ULMFit) and multi-lingual models (XLMR and mBERT) on both sequence classification and token classification tasks in human-annotated, mono-lingual contexts.
scb-mt-en-th-2020: A Large English-Thai Parallel Corpus
Jul 07, 2020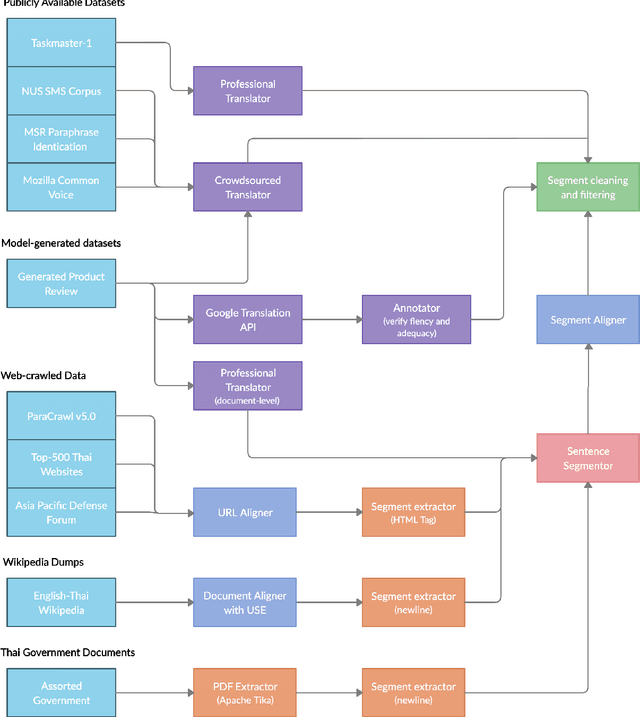
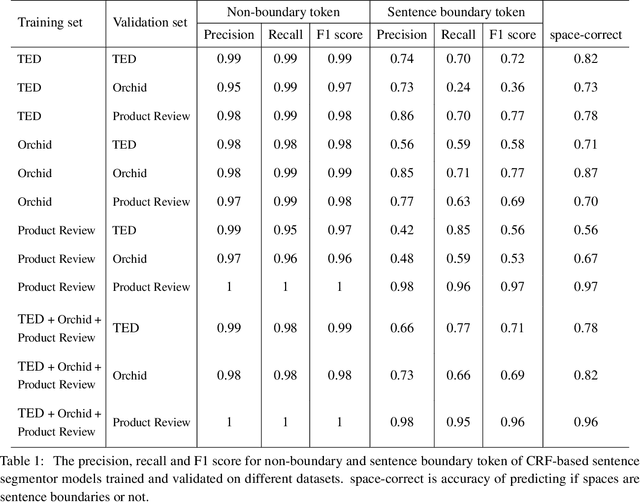
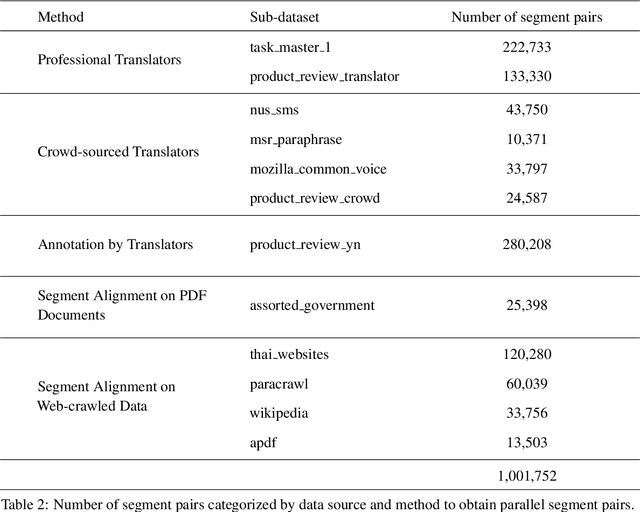
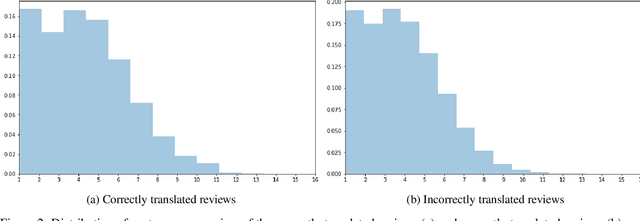
The primary objective of our work is to build a large-scale English-Thai dataset for machine translation. We construct an English-Thai machine translation dataset with over 1 million segment pairs, curated from various sources, namely news, Wikipedia articles, SMS messages, task-based dialogs, web-crawled data and government documents. Methodology for gathering data, building parallel texts and removing noisy sentence pairs are presented in a reproducible manner. We train machine translation models based on this dataset. Our models' performance are comparable to that of Google Translation API (as of May 2020) for Thai-English and outperform Google when the Open Parallel Corpus (OPUS) is included in the training data for both Thai-English and English-Thai translation. The dataset, pre-trained models, and source code to reproduce our work are available for public use.