 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised 3D Hand Pose Estimation from monocular RGB via Contrastive Learning
Jun 30, 2021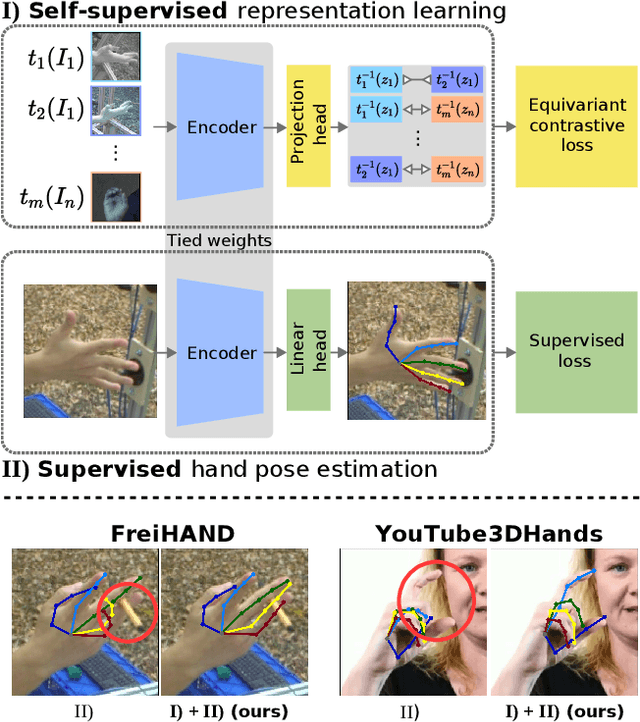
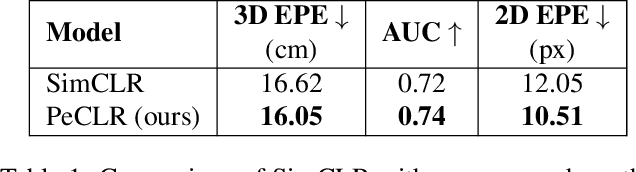
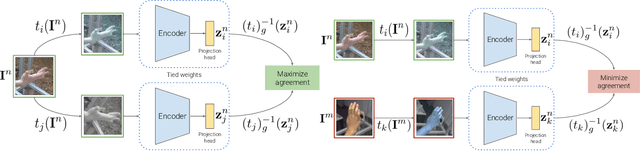
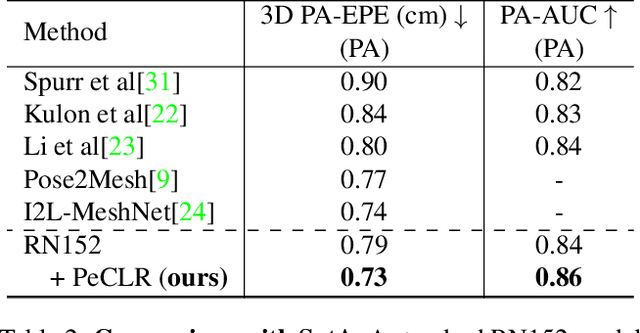
Acquiring accurate 3D annotated data for hand pose estimation is a notoriously difficult problem. This typically requires complex multi-camera setups and controlled conditions, which in turn creates a domain gap that is hard to bridge to fully unconstrained settings. Encouraged by the success of contrastive learning on image classification tasks, we propose a new self-supervised method for the structured regression task of 3D hand pose estimation. Contrastive learning makes use of unlabeled data for the purpose of representation learning via a loss formulation that encourages the learned feature representations to be invariant under any image transformation. For 3D hand pose estimation, it too is desirable to have invariance to appearance transformation such as color jitter. However, the task requires equivariance under affine transformations, such as rotation and translation. To address this issue, we propose an equivariant contrastive objective and demonstrate its effectiveness in the context of 3D hand pose estimation. We experimentally investigate the impact of invariant and equivariant contrastive objectives and show that learning equivariant features leads to better representations for the task of 3D hand pose estimation. Furthermore, we show that a standard ResNet-152, trained on additional unlabeled data, attains an improvement of $7.6\%$ in PA-EPE on FreiHAND and thus achieves state-of-the-art performance without any task specific, specialized architectures.