 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised 3D Hand Pose Estimation via Biomechanical Constraints
Paper and Code
Mar 20, 2020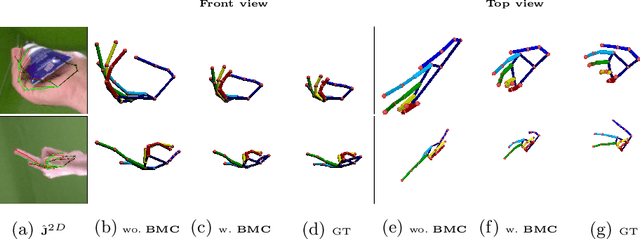



Estimating 3D hand pose from 2D images is a difficult, inverse problem due to the inherent scale and depth ambiguities. Current state-of-the-art methods train fully supervised deep neural networks with 3D ground-truth data. However, acquiring 3D annotations is expensive, typically requiring calibrated multi-view setups or labor intensive manual annotations. While annotations of 2D keypoints are much easier to obtain, how to efficiently leverage such weakly-supervised data to improve the task of 3D hand pose prediction remains an important open question. The key difficulty stems from the fact that direct application of additional 2D supervision mostly benefits the 2D proxy objective but does little to alleviate the depth and scale ambiguities. Embracing this challenge we propose a set of novel losses. We show by extensive experiments that our proposed constraints significantly reduce the depth ambiguity and allow the network to more effectively leverage additional 2D annotated images. For example, on the challenging freiHAND dataset using additional 2D annotation without our proposed biomechanical constraints reduces the depth error by only $15\%$, whereas the error is reduced significantly by $50\%$ when the proposed biomechanical constraints are used.