 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemdx: A Cloud Platform for Supporting Data Science and Cross-Disciplinary Research Collaborations
Mar 27, 2022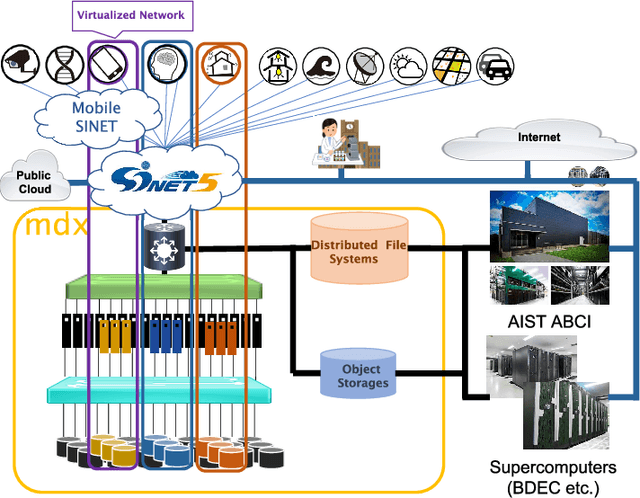
The growing amount of data and advances in data science have created a need for a new kind of cloud platform that provides users with flexibility, strong security, and the ability to couple with supercomputers and edge devices through high-performance networks. We have built such a nation-wide cloud platform, called "mdx" to meet this need. The mdx platform's virtualization service, jointly operated by 9 national universities and 2 national research institutes in Japan, launched in 2021, and more features are in development. Currently mdx is used by researchers in a wide variety of domains, including materials informatics, geo-spatial information science, life science, astronomical science, economics, social science, and computer science. This paper provides an the overview of the mdx platform, details the motivation for its development, reports its current status, and outlines its future plans.
Automatic Graph Partitioning for Very Large-scale Deep Learning
Mar 30, 2021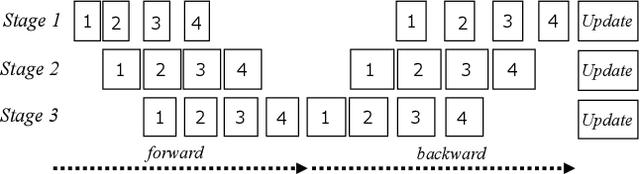
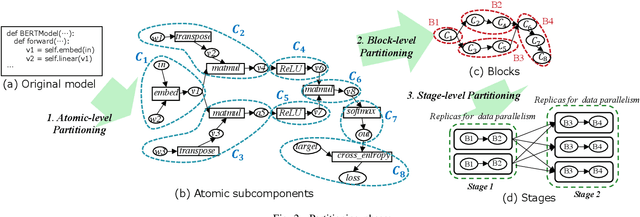
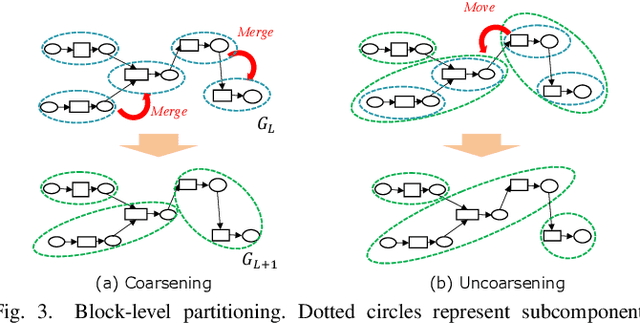
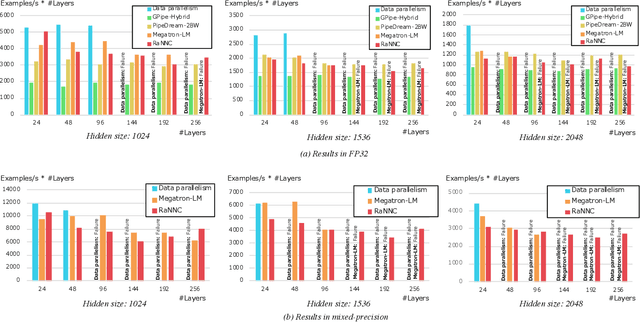
This work proposes RaNNC (Rapid Neural Network Connector) as middleware for automatic hybrid parallelism. In recent deep learning research, as exemplified by T5 and GPT-3, the size of neural network models continues to grow. Since such models do not fit into the memory of accelerator devices, they need to be partitioned by model parallelism techniques. Moreover, to accelerate training for huge training data, we need a combination of model and data parallelisms, i.e., hybrid parallelism. Given a model description for PyTorch without any specification for model parallelism, RaNNC automatically partitions the model into a set of subcomponents so that (1) each subcomponent fits a device memory and (2) a high training throughput for pipeline parallelism is achieved by balancing the computation times of the subcomponents. In our experiments, we compared RaNNC with two popular frameworks, Megatron-LM (hybrid parallelism) and GPipe (originally proposed for model parallelism, but a version allowing hybrid parallelism also exists), for training models with increasingly greater numbers of parameters. In the pre-training of enlarged BERT models, RaNNC successfully trained models five times larger than those Megatron-LM could, and RaNNC's training throughputs were comparable to Megatron-LM's when pre-training the same models. RaNNC also achieved better training throughputs than GPipe on both the enlarged BERT model pre-training (GPipe with hybrid parallelism) and the enlarged ResNet models (GPipe with model parallelism) in all of the settings we tried. These results are remarkable, since RaNNC automatically partitions models without any modification to their descriptions; Megatron-LM and GPipe require users to manually rewrite the models' descriptions.