 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Multi-label Atomic Activity Recognition by Robust Visual Feature and Advanced Attention @ ROAD++ Atomic Activity Recognition 2024
Oct 21, 2024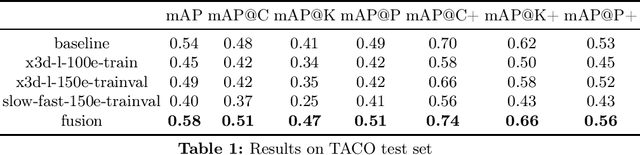
Road++ Track3 proposes a multi-label atomic activity recognition task in traffic scenarios, which can be standardized as a 64-class multi-label video action recognition task. In the multi-label atomic activity recognition task, the robustness of visual feature extraction remains a key challenge, which directly affects the model performance and generalization ability. To cope with these issues, our team optimized three aspects: data processing, model and post-processing. Firstly, the appropriate resolution and video sampling strategy are selected, and a fixed sampling strategy is set on the validation and test sets. Secondly, in terms of model training, the team selects a variety of visual backbone networks for feature extraction, and then introduces the action-slot model, which is trained on the training and validation sets, and reasoned on the test set. Finally, for post-processing, the team combined the strengths and weaknesses of different models for weighted fusion, and the final mAP on the test set was 58%, which is 4% higher than the challenge baseline.
LUAI Challenge 2021 on Learning to Understand Aerial Images
Aug 30, 2021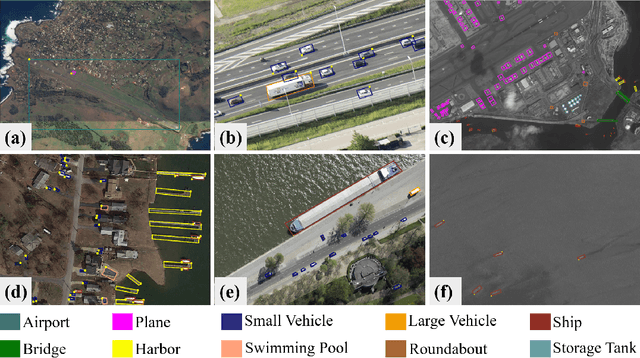

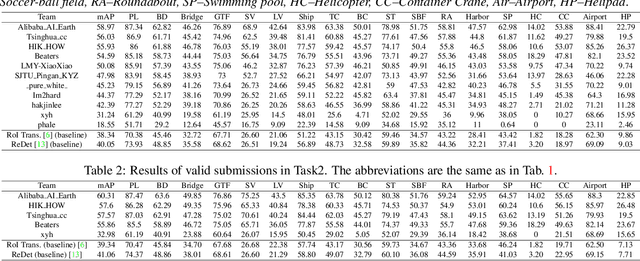
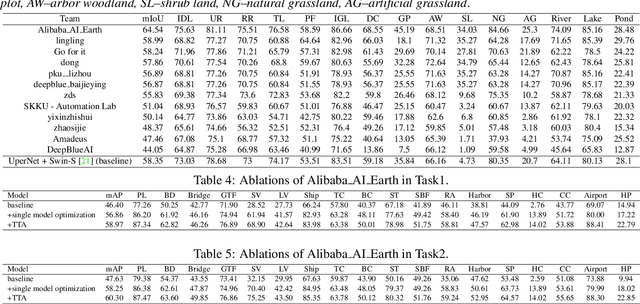
This report summarizes the results of Learning to Understand Aerial Images (LUAI) 2021 challenge held on ICCV 2021, which focuses on object detection and semantic segmentation in aerial images. Using DOTA-v2.0 and GID-15 datasets, this challenge proposes three tasks for oriented object detection, horizontal object detection, and semantic segmentation of common categories in aerial images. This challenge received a total of 146 registrations on the three tasks. Through the challenge, we hope to draw attention from a wide range of communities and call for more efforts on the problems of learning to understand aerial images.