 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Multi-label Atomic Activity Recognition by Robust Visual Feature and Advanced Attention @ ROAD++ Atomic Activity Recognition 2024
Paper and Code
Oct 21, 2024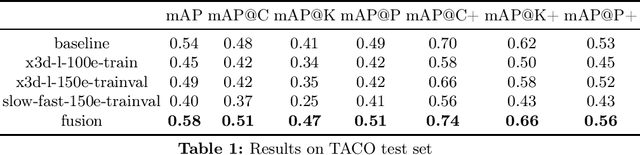
Road++ Track3 proposes a multi-label atomic activity recognition task in traffic scenarios, which can be standardized as a 64-class multi-label video action recognition task. In the multi-label atomic activity recognition task, the robustness of visual feature extraction remains a key challenge, which directly affects the model performance and generalization ability. To cope with these issues, our team optimized three aspects: data processing, model and post-processing. Firstly, the appropriate resolution and video sampling strategy are selected, and a fixed sampling strategy is set on the validation and test sets. Secondly, in terms of model training, the team selects a variety of visual backbone networks for feature extraction, and then introduces the action-slot model, which is trained on the training and validation sets, and reasoned on the test set. Finally, for post-processing, the team combined the strengths and weaknesses of different models for weighted fusion, and the final mAP on the test set was 58%, which is 4% higher than the challenge baseline.