 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeg-ReSearch: Segmentation with Interleaved Reasoning and External Search
Feb 04, 2026Segmentation based on language has been a popular topic in computer vision. While recent advances in multimodal large language models (MLLMs) have endowed segmentation systems with reasoning capabilities, these efforts remain confined by the frozen internal knowledge of MLLMs, which limits their potential for real-world scenarios that involve up-to-date information or domain-specific concepts. In this work, we propose \textbf{Seg-ReSearch}, a novel segmentation paradigm that overcomes the knowledge bottleneck of existing approaches. By enabling interleaved reasoning and external search, Seg-ReSearch empowers segmentation systems to handle dynamic, open-world queries that extend beyond the frozen knowledge of MLLMs. To effectively train this capability, we introduce a hierarchical reward design that harmonizes initial guidance with progressive incentives, mitigating the dilemma between sparse outcome signals and rigid step-wise supervision. For evaluation, we construct OK-VOS, a challenging benchmark that explicitly requires outside knowledge for video object segmentation. Experiments on OK-VOS and two existing reasoning segmentation benchmarks demonstrate that our Seg-ReSearch improves state-of-the-art approaches by a substantial margin. Code and data will be released at https://github.com/iSEE-Laboratory/Seg-ReSearch.
Refer-Agent: A Collaborative Multi-Agent System with Reasoning and Reflection for Referring Video Object Segmentation
Feb 03, 2026Referring Video Object Segmentation (RVOS) aims to segment objects in videos based on textual queries. Current methods mainly rely on large-scale supervised fine-tuning (SFT) of Multi-modal Large Language Models (MLLMs). However, this paradigm suffers from heavy data dependence and limited scalability against the rapid evolution of MLLMs. Although recent zero-shot approaches offer a flexible alternative, their performance remains significantly behind SFT-based methods, due to the straightforward workflow designs. To address these limitations, we propose \textbf{Refer-Agent}, a collaborative multi-agent system with alternating reasoning-reflection mechanisms. This system decomposes RVOS into step-by-step reasoning process. During reasoning, we introduce a Coarse-to-Fine frame selection strategy to ensure the frame diversity and textual relevance, along with a Dynamic Focus Layout that adaptively adjusts the agent's visual focus. Furthermore, we propose a Chain-of-Reflection mechanism, which employs a Questioner-Responder pair to generate a self-reflection chain, enabling the system to verify intermediate results and generates feedback for next-round reasoning refinement. Extensive experiments on five challenging benchmarks demonstrate that Refer-Agent significantly outperforms state-of-the-art methods, including both SFT-based models and zero-shot approaches. Moreover, Refer-Agent is flexible and enables fast integration of new MLLMs without any additional fine-tuning costs. Code will be released.
Long-RVOS: A Comprehensive Benchmark for Long-term Referring Video Object Segmentation
May 19, 2025Referring video object segmentation (RVOS) aims to identify, track and segment the objects in a video based on language descriptions, which has received great attention in recent years. However, existing datasets remain focus on short video clips within several seconds, with salient objects visible in most frames. To advance the task towards more practical scenarios, we introduce \textbf{Long-RVOS}, a large-scale benchmark for long-term referring video object segmentation. Long-RVOS contains 2,000+ videos of an average duration exceeding 60 seconds, covering a variety of objects that undergo occlusion, disappearance-reappearance and shot changing. The objects are manually annotated with three different types of descriptions to individually evaluate the understanding of static attributes, motion patterns and spatiotemporal relationships. Moreover, unlike previous benchmarks that rely solely on the per-frame spatial evaluation, we introduce two new metrics to assess the temporal and spatiotemporal consistency. We benchmark 6 state-of-the-art methods on Long-RVOS. The results show that current approaches struggle severely with the long-video challenges. To address this, we further propose ReferMo, a promising baseline method that integrates motion information to expand the temporal receptive field, and employs a local-to-global architecture to capture both short-term dynamics and long-term dependencies. Despite simplicity, ReferMo achieves significant improvements over current methods in long-term scenarios. We hope that Long-RVOS and our baseline can drive future RVOS research towards tackling more realistic and long-form videos.
PVUW 2025 Challenge Report: Advances in Pixel-level Understanding of Complex Videos in the Wild
Apr 15, 2025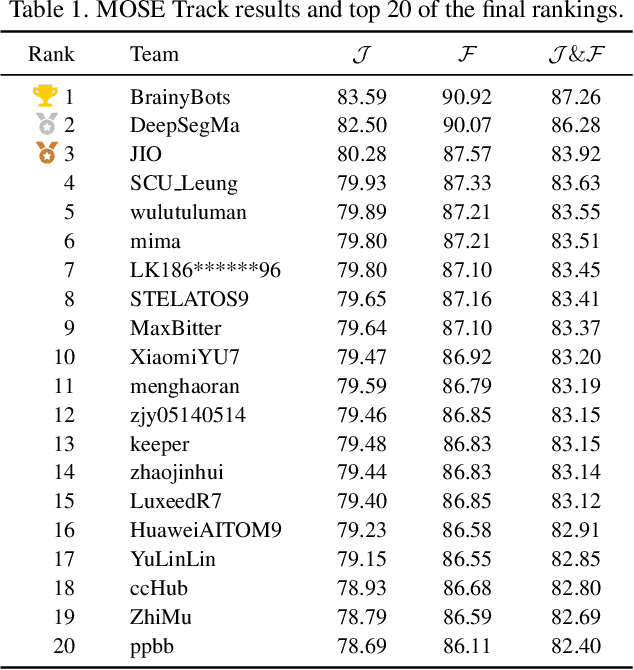
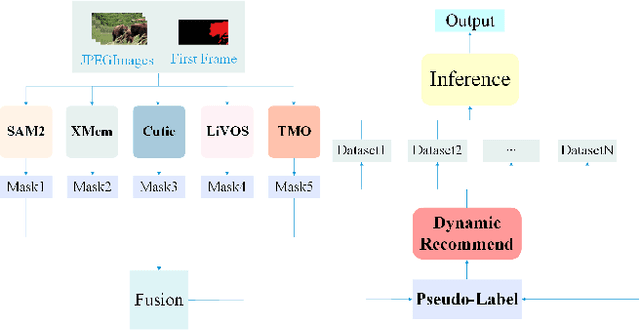
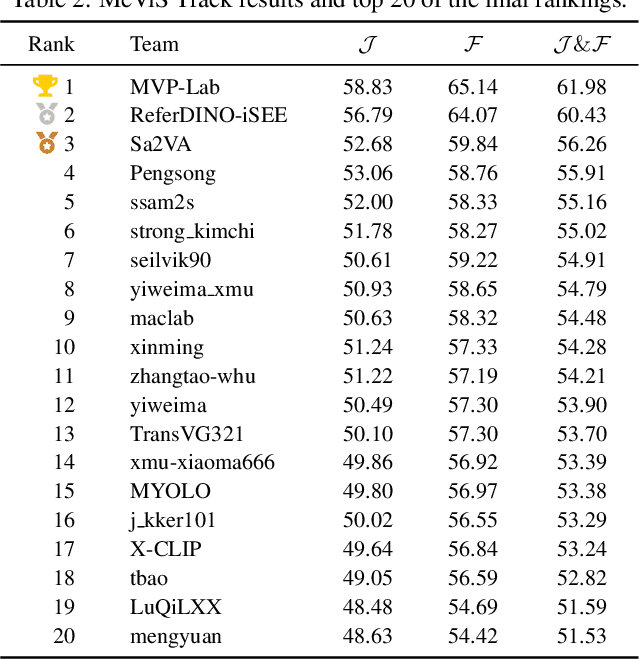
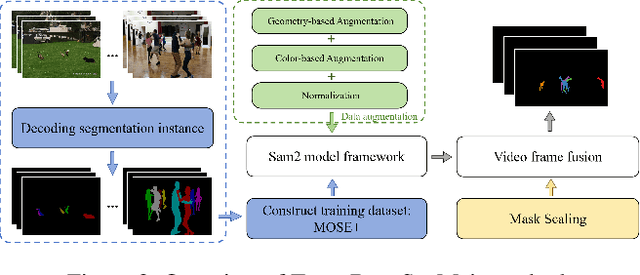
This report provides a comprehensive overview of the 4th Pixel-level Video Understanding in the Wild (PVUW) Challenge, held in conjunction with CVPR 2025. It summarizes the challenge outcomes, participating methodologies, and future research directions. The challenge features two tracks: MOSE, which focuses on complex scene video object segmentation, and MeViS, which targets motion-guided, language-based video segmentation. Both tracks introduce new, more challenging datasets designed to better reflect real-world scenarios. Through detailed evaluation and analysis, the challenge offers valuable insights into the current state-of-the-art and emerging trends in complex video segmentation. More information can be found on the workshop website: https://pvuw.github.io/.
ReferDINO-Plus: 2nd Solution for 4th PVUW MeViS Challenge at CVPR 2025
Mar 30, 2025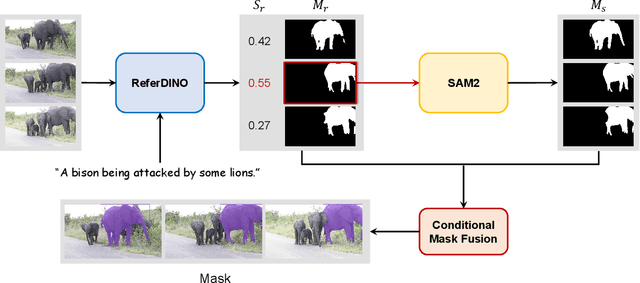
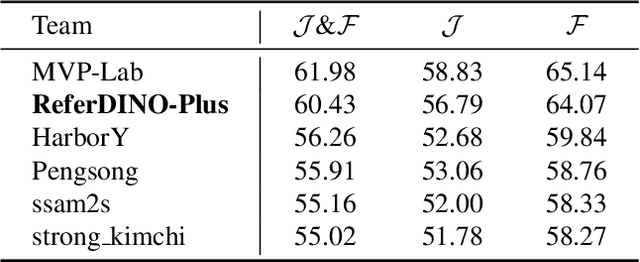

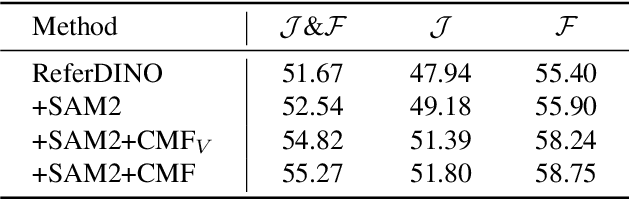
Referring Video Object Segmentation (RVOS) aims to segment target objects throughout a video based on a text description. This task has attracted increasing attention in the field of computer vision due to its promising applications in video editing and human-agent interaction. Recently, ReferDINO has demonstrated promising performance in this task by adapting object-level vision-language knowledge from pretrained foundational image models. In this report, we further enhance its capabilities by incorporating the advantages of SAM2 in mask quality and object consistency. In addition, to effectively balance performance between single-object and multi-object scenarios, we introduce a conditional mask fusion strategy that adaptively fuses the masks from ReferDINO and SAM2. Our solution, termed ReferDINO-Plus, achieves 60.43 \(\mathcal{J}\&\mathcal{F}\) on MeViS test set, securing 2nd place in the MeViS PVUW challenge at CVPR 2025. The code is available at: https://github.com/iSEE-Laboratory/ReferDINO-Plus.