 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking the V in Text-VQA Matter
Paper and Code
Aug 01, 2023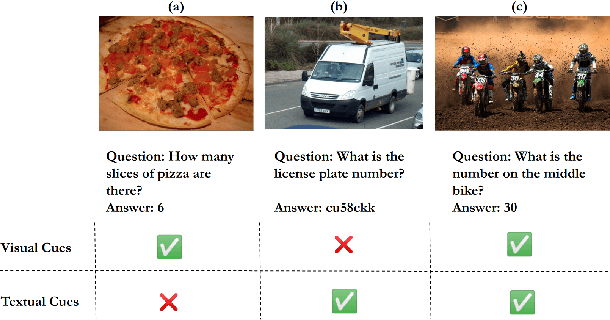

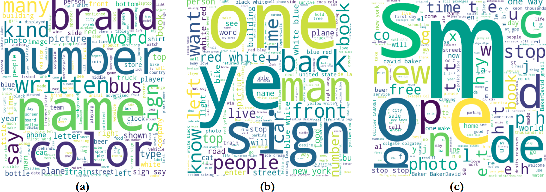

Text-based VQA aims at answering questions by reading the text present in the images. It requires a large amount of scene-text relationship understanding compared to the VQA task. Recent studies have shown that the question-answer pairs in the dataset are more focused on the text present in the image but less importance is given to visual features and some questions do not require understanding the image. The models trained on this dataset predict biased answers due to the lack of understanding of visual context. For example, in questions like "What is written on the signboard?", the answer predicted by the model is always "STOP" which makes the model to ignore the image. To address these issues, we propose a method to learn visual features (making V matter in TextVQA) along with the OCR features and question features using VQA dataset as external knowledge for Text-based VQA. Specifically, we combine the TextVQA dataset and VQA dataset and train the model on this combined dataset. Such a simple, yet effective approach increases the understanding and correlation between the image features and text present in the image, which helps in the better answering of questions. We further test the model on different datasets and compare their qualitative and quantitative results.