 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriple Preference Optimization: Achieving Better Alignment with Less Data in a Single Step Optimization
Paper and Code
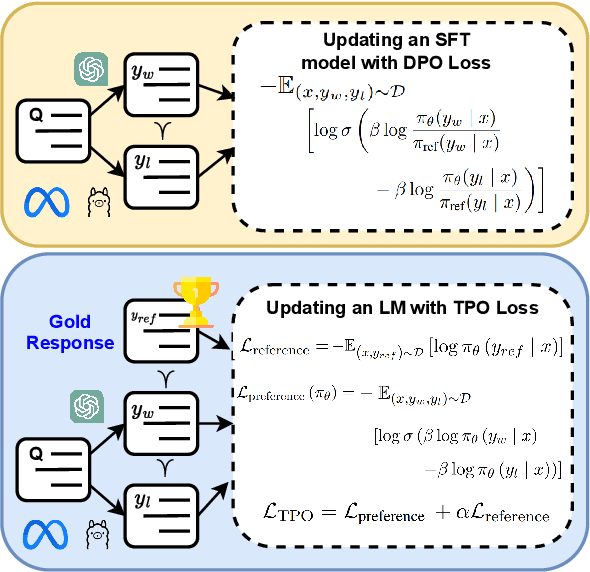



Large Language Models (LLMs) perform well across diverse tasks, but aligning them with human demonstrations is challenging. Recently, Reinforcement Learning (RL)-free methods like Direct Preference Optimization (DPO) have emerged, offering improved stability and scalability while retaining competitive performance relative to RL-based methods. However, while RL-free methods deliver satisfactory performance, they require significant data to develop a robust Supervised Fine-Tuned (SFT) model and an additional step to fine-tune this model on a preference dataset, which constrains their utility and scalability. In this paper, we introduce Triple Preference Optimization (TPO), a new preference learning method designed to align an LLM with three preferences without requiring a separate SFT step and using considerably less data. Through a combination of practical experiments and theoretical analysis, we show the efficacy of TPO as a single-step alignment strategy. Specifically, we fine-tuned the Phi-2 (2.7B) and Mistral (7B) models using TPO directly on the UltraFeedback dataset, achieving superior results compared to models aligned through other methods such as SFT, DPO, KTO, IPO, CPO, and ORPO. Moreover, the performance of TPO without the SFT component led to notable improvements in the MT-Bench score, with increases of +1.27 and +0.63 over SFT and DPO, respectively. Additionally, TPO showed higher average accuracy, surpassing DPO and SFT by 4.2% and 4.97% on the Open LLM Leaderboard benchmarks. Our code is publicly available at https://github.com/sahsaeedi/triple-preference-optimization .