 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTotal Normal Curvature Regularization and its Minimization for Surface and Image Smoothing
Dec 25, 2025We introduce a novel formulation for curvature regularization by penalizing normal curvatures from multiple directions. This total normal curvature regularization is capable of producing solutions with sharp edges and precise isotropic properties. To tackle the resulting high-order nonlinear optimization problem, we reformulate it as the task of finding the steady-state solution of a time-dependent partial differential equation (PDE) system. Time discretization is achieved through operator splitting, where each subproblem at the fractional steps either has a closed-form solution or can be efficiently solved using advanced algorithms. Our method circumvents the need for complex parameter tuning and demonstrates robustness to parameter choices. The efficiency and effectiveness of our approach have been rigorously validated in the context of surface and image smoothing problems.
Total Curvature Regularization and its_Minimization for Surface and Image Smoothing
Dec 22, 2025We introduce a novel formulation for curvature regularization by penalizing normal curvatures from multiple directions. This total normal curvature regularization is capable of producing solutions with sharp edges and precise isotropic properties. To tackle the resulting high-order nonlinear optimization problem, we reformulate it as the task of finding the steady-state solution of a time-dependent partial differential equation (PDE) system. Time discretization is achieved through operator splitting, where each subproblem at the fractional steps either has a closed-form solution or can be efficiently solved using advanced algorithms. Our method circumvents the need for complex parameter tuning and demonstrates robustness to parameter choices. The efficiency and effectiveness of our approach have been rigorously validated in the context of surface and image smoothing problems.
STDA: Spatio-Temporal Dual-Encoder Network Incorporating Driver Attention to Predict Driver Behaviors Under Safety-Critical Scenarios
Aug 03, 2024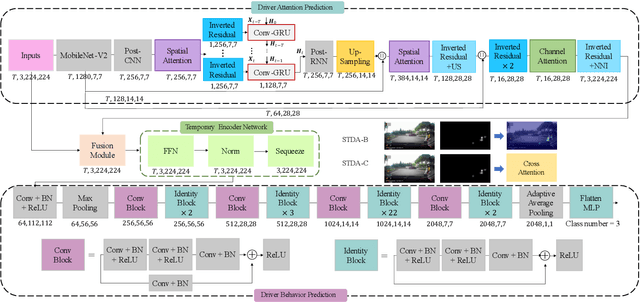
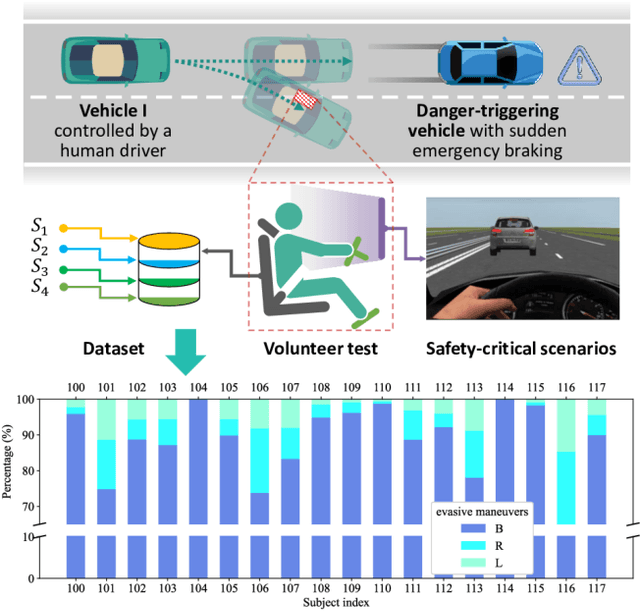
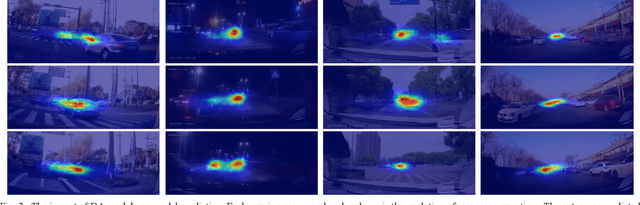
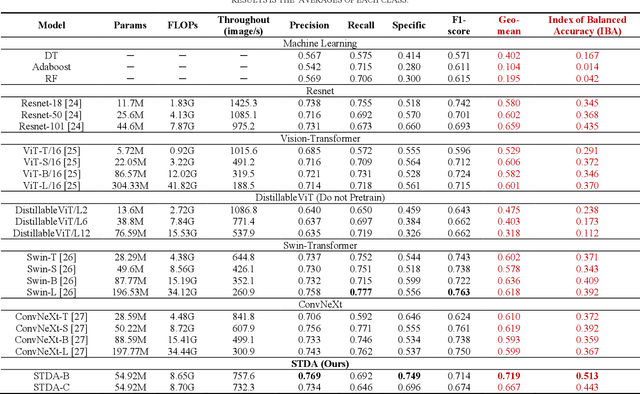
Accurate behavior prediction for vehicles is essential but challenging for autonomous driving. Most existing studies show satisfying performance under regular scenarios, but most neglected safety-critical scenarios. In this study, a spatio-temporal dual-encoder network named STDA for safety-critical scenarios was developed. Considering the exceptional capabilities of human drivers in terms of situational awareness and comprehending risks, driver attention was incorporated into STDA to facilitate swift identification of the critical regions, which is expected to improve both performance and interpretability. STDA contains four parts: the driver attention prediction module, which predicts driver attention; the fusion module designed to fuse the features between driver attention and raw images; the temporary encoder module used to enhance the capability to interpret dynamic scenes; and the behavior prediction module to predict the behavior. The experiment data are used to train and validate the model. The results show that STDA improves the G-mean from 0.659 to 0.719 when incorporating driver attention and adopting a temporal encoder module. In addition, extensive experimentation has been conducted to validate that the proposed module exhibits robust generalization capabilities and can be seamlessly integrated into other mainstream models.