 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Note on the Evaluation of Clustering Algorithms
Paper and Code
Aug 10, 2019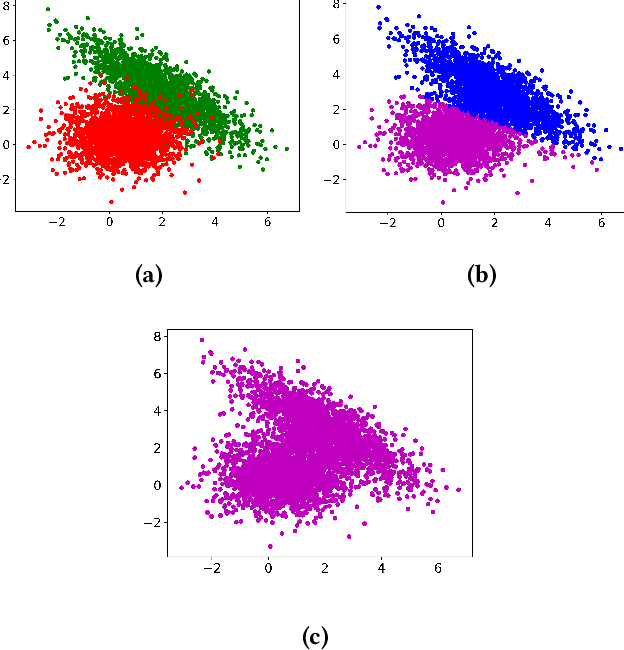
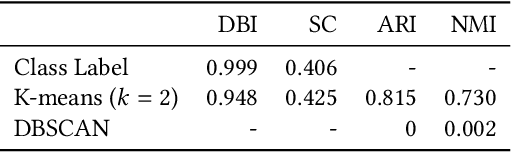
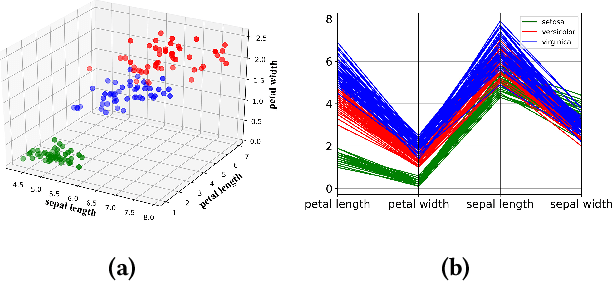
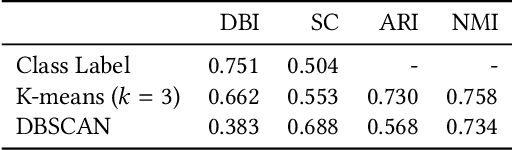
Experimental evaluation is a major research methodology for investigating clustering algorithms. For this purpose, a number of benchmark datasets have been widely used in the literature and their quality plays an important role on the value of the research work. However, in most of the existing studies, little attention has been paid to the specific properties of the datasets and they are often regarded as black-box problems. In our work, with the help of advanced visualization and dimension reduction techniques, we show that there are potential issues with some of the popular benchmark datasets used to evaluate clustering algorithms that may seriously compromise the research quality and even may produce completely misleading results. We suggest that significant efforts need to be devoted to improving the current practice of experimental evaluation of clustering algorithms by having a principled analysis of each benchmark dataset of interest.