 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePan-infection Foundation Framework Enables Multiple Pathogen Prediction
Dec 31, 2024


Host-response-based diagnostics can improve the accuracy of diagnosing bacterial and viral infections, thereby reducing inappropriate antibiotic prescriptions. However, the existing cohorts with limited sample size and coarse infections types are unable to support the exploration of an accurate and generalizable diagnostic model. Here, we curate the largest infection host-response transcriptome data, including 11,247 samples across 89 blood transcriptome datasets from 13 countries and 21 platforms. We build a diagnostic model for pathogen prediction starting from a pan-infection model as foundation (AUC = 0.97) based on the pan-infection dataset. Then, we utilize knowledge distillation to efficiently transfer the insights from this "teacher" model to four lightweight pathogen "student" models, i.e., staphylococcal infection (AUC = 0.99), streptococcal infection (AUC = 0.94), HIV infection (AUC = 0.93), and RSV infection (AUC = 0.94), as well as a sepsis "student" model (AUC = 0.99). The proposed knowledge distillation framework not only facilitates the diagnosis of pathogens using pan-infection data, but also enables an across-disease study from pan-infection to sepsis. Moreover, the framework enables high-degree lightweight design of diagnostic models, which is expected to be adaptively deployed in clinical settings.
Online Hierarchical Clustering Approximations
Sep 20, 2019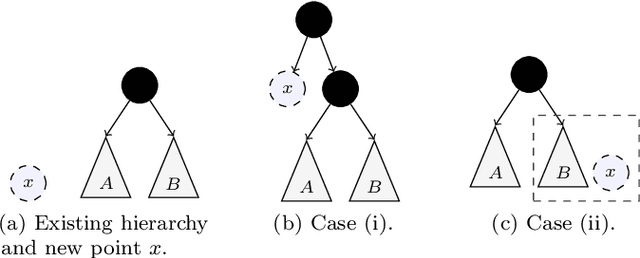

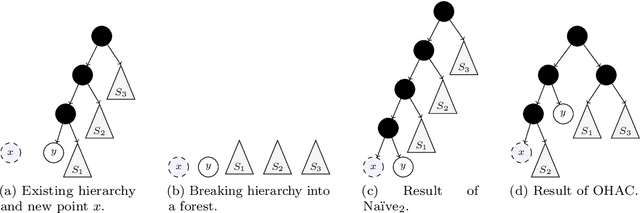
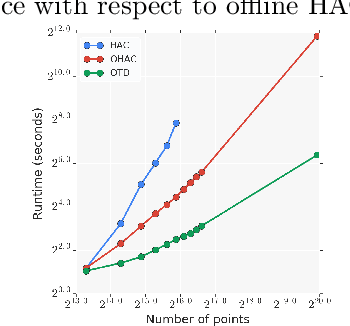
Hierarchical clustering is a widely used approach for clustering datasets at multiple levels of granularity. Despite its popularity, existing algorithms such as hierarchical agglomerative clustering (HAC) are limited to the offline setting, and thus require the entire dataset to be available. This prohibits their use on large datasets commonly encountered in modern learning applications. In this paper, we consider hierarchical clustering in the online setting, where points arrive one at a time. We propose two algorithms that seek to optimize the Moseley and Wang (MW) revenue function, a variant of the Dasgupta cost. These algorithms offer different tradeoffs between efficiency and MW revenue performance. The first algorithm, OTD, is a highly efficient Online Top Down algorithm which provably achieves a 1/3-approximation to the MW revenue under a data separation assumption. The second algorithm, OHAC, is an online counterpart to offline HAC, which is known to yield a 1/3-approximation to the MW revenue, and produce good quality clusters in practice. We show that OHAC approximates offline HAC by leveraging a novel split-merge procedure. We empirically show that OTD and OHAC offer significant efficiency and cluster quality gains respectively over baselines.
Neural SDE: Stabilizing Neural ODE Networks with Stochastic Noise
Jun 05, 2019

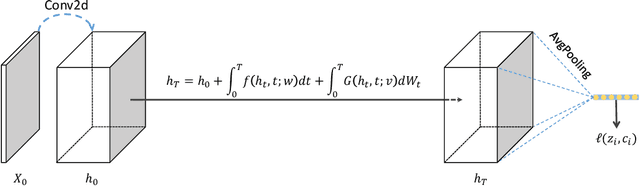
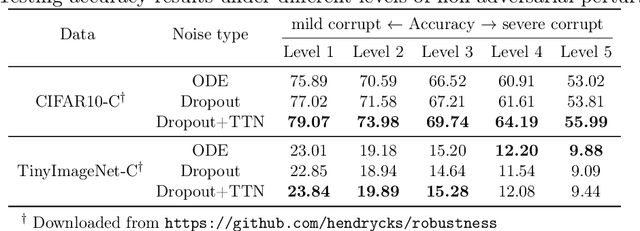
Neural Ordinary Differential Equation (Neural ODE) has been proposed as a continuous approximation to the ResNet architecture. Some commonly used regularization mechanisms in discrete neural networks (e.g. dropout, Gaussian noise) are missing in current Neural ODE networks. In this paper, we propose a new continuous neural network framework called Neural Stochastic Differential Equation (Neural SDE) network, which naturally incorporates various commonly used regularization mechanisms based on random noise injection. Our framework can model various types of noise injection frequently used in discrete networks for regularization purpose, such as dropout and additive/multiplicative noise in each block. We provide theoretical analysis explaining the improved robustness of Neural SDE models against input perturbations/adversarial attacks. Furthermore, we demonstrate that the Neural SDE network can achieve better generalization than the Neural ODE and is more resistant to adversarial and non-adversarial input perturbations.