 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Hierarchical Agglomerative Clustering to Billion-sized Datasets
May 25, 2021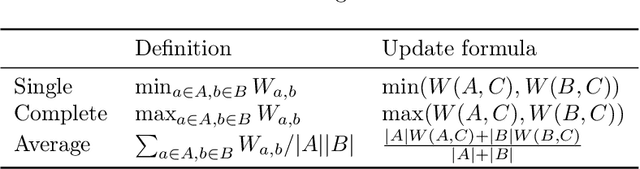
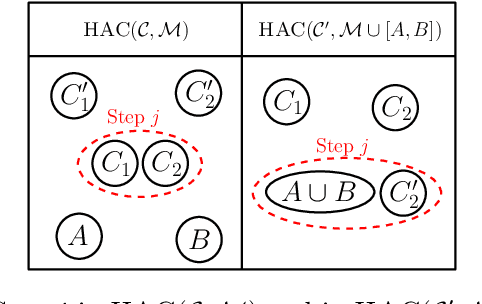

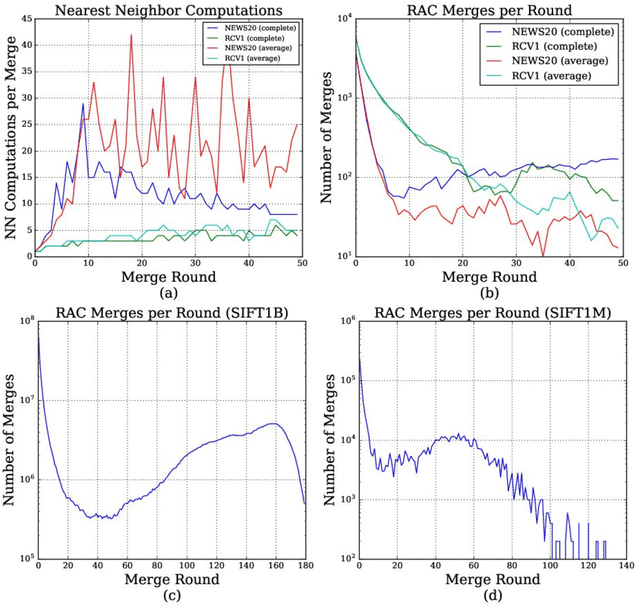
Hierarchical Agglomerative Clustering (HAC) is one of the oldest but still most widely used clustering methods. However, HAC is notoriously hard to scale to large data sets as the underlying complexity is at least quadratic in the number of data points and many algorithms to solve HAC are inherently sequential. In this paper, we propose {Reciprocal Agglomerative Clustering (RAC)}, a distributed algorithm for HAC, that uses a novel strategy to efficiently merge clusters in parallel. We prove theoretically that RAC recovers the exact solution of HAC. Furthermore, under clusterability and balancedness assumption we show provable speedups in total runtime due to the parallelism. We also show that these speedups are achievable for certain probabilistic data models. In extensive experiments, we show that this parallelism is achieved on real world data sets and that the proposed RAC algorithm can recover the HAC hierarchy on billions of data points connected by trillions of edges in less than an hour.
Online Hierarchical Clustering Approximations
Sep 20, 2019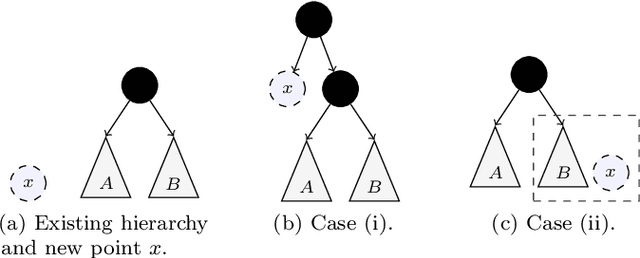

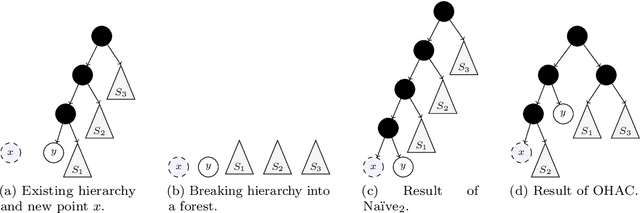
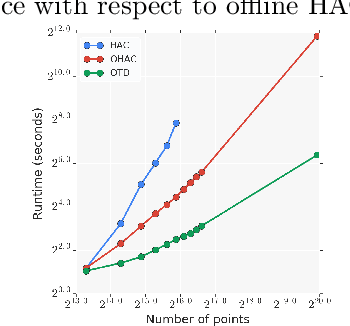
Hierarchical clustering is a widely used approach for clustering datasets at multiple levels of granularity. Despite its popularity, existing algorithms such as hierarchical agglomerative clustering (HAC) are limited to the offline setting, and thus require the entire dataset to be available. This prohibits their use on large datasets commonly encountered in modern learning applications. In this paper, we consider hierarchical clustering in the online setting, where points arrive one at a time. We propose two algorithms that seek to optimize the Moseley and Wang (MW) revenue function, a variant of the Dasgupta cost. These algorithms offer different tradeoffs between efficiency and MW revenue performance. The first algorithm, OTD, is a highly efficient Online Top Down algorithm which provably achieves a 1/3-approximation to the MW revenue under a data separation assumption. The second algorithm, OHAC, is an online counterpart to offline HAC, which is known to yield a 1/3-approximation to the MW revenue, and produce good quality clusters in practice. We show that OHAC approximates offline HAC by leveraging a novel split-merge procedure. We empirically show that OTD and OHAC offer significant efficiency and cluster quality gains respectively over baselines.