 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Hierarchical Agglomerative Clustering to Billion-sized Datasets
May 25, 2021

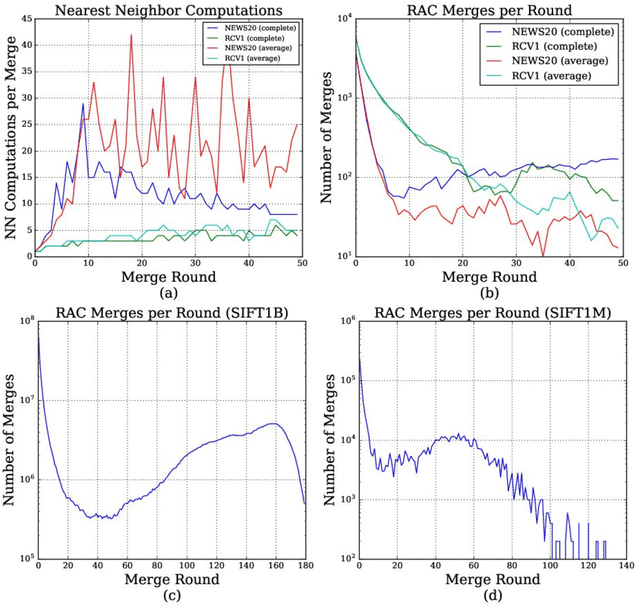
Hierarchical Agglomerative Clustering (HAC) is one of the oldest but still most widely used clustering methods. However, HAC is notoriously hard to scale to large data sets as the underlying complexity is at least quadratic in the number of data points and many algorithms to solve HAC are inherently sequential. In this paper, we propose {Reciprocal Agglomerative Clustering (RAC)}, a distributed algorithm for HAC, that uses a novel strategy to efficiently merge clusters in parallel. We prove theoretically that RAC recovers the exact solution of HAC. Furthermore, under clusterability and balancedness assumption we show provable speedups in total runtime due to the parallelism. We also show that these speedups are achievable for certain probabilistic data models. In extensive experiments, we show that this parallelism is achieved on real world data sets and that the proposed RAC algorithm can recover the HAC hierarchy on billions of data points connected by trillions of edges in less than an hour.