 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOAR: Improved Indexing for Approximate Nearest Neighbor Search
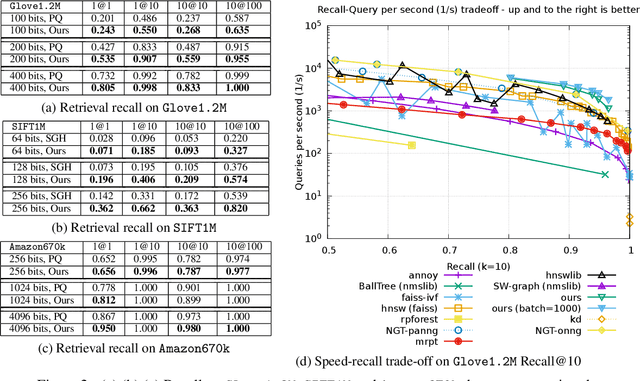
Mar 31, 2024This paper introduces SOAR: Spilling with Orthogonality-Amplified Residuals, a novel data indexing technique for approximate nearest neighbor (ANN) search. SOAR extends upon previous approaches to ANN search, such as spill trees, that utilize multiple redundant representations while partitioning the data to reduce the probability of missing a nearest neighbor during search. Rather than training and computing these redundant representations independently, however, SOAR uses an orthogonality-amplified residual loss, which optimizes each representation to compensate for cases where other representations perform poorly. This drastically improves the overall index quality, resulting in state-of-the-art ANN benchmark performance while maintaining fast indexing times and low memory consumption.
Scaling Hierarchical Agglomerative Clustering to Billion-sized Datasets
May 25, 2021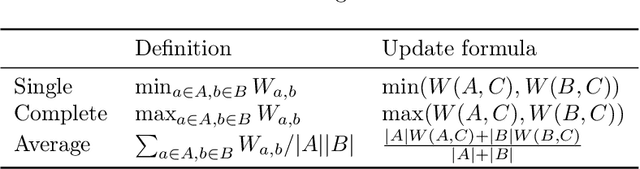
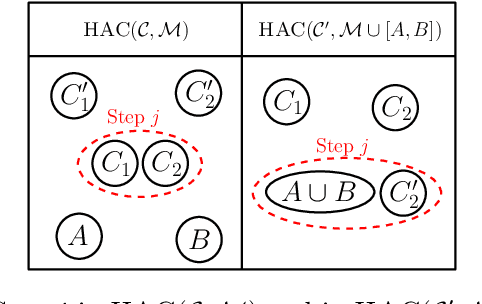

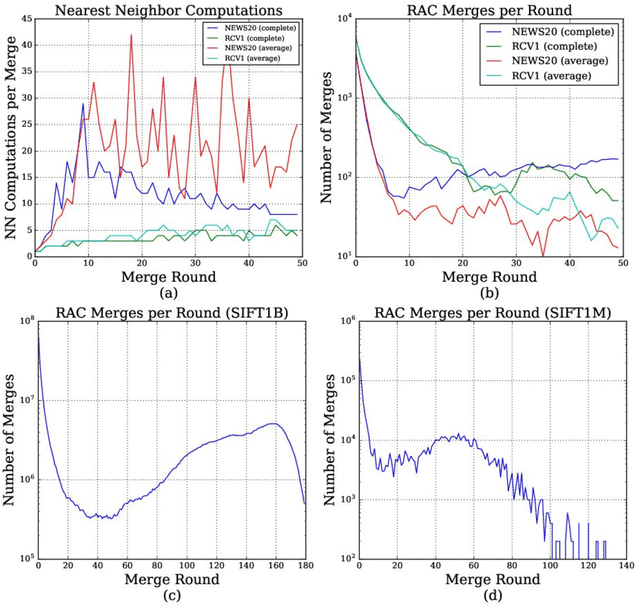
Hierarchical Agglomerative Clustering (HAC) is one of the oldest but still most widely used clustering methods. However, HAC is notoriously hard to scale to large data sets as the underlying complexity is at least quadratic in the number of data points and many algorithms to solve HAC are inherently sequential. In this paper, we propose {Reciprocal Agglomerative Clustering (RAC)}, a distributed algorithm for HAC, that uses a novel strategy to efficiently merge clusters in parallel. We prove theoretically that RAC recovers the exact solution of HAC. Furthermore, under clusterability and balancedness assumption we show provable speedups in total runtime due to the parallelism. We also show that these speedups are achievable for certain probabilistic data models. In extensive experiments, we show that this parallelism is achieved on real world data sets and that the proposed RAC algorithm can recover the HAC hierarchy on billions of data points connected by trillions of edges in less than an hour.
New Loss Functions for Fast Maximum Inner Product Search
Sep 11, 2019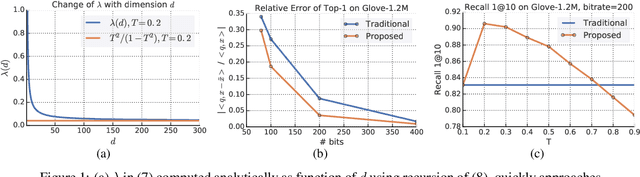
Quantization based methods are popular for solving large scale maximum inner product search problems. However, in most traditional quantization works, the objective is to minimize the reconstruction error for datapoints to be searched. In this work, we focus directly on minimizing error in inner product approximation and derive a new class of quantization loss functions. One key aspect of the new loss functions is that we weight the error term based on the value of the inner product, giving more importance to pairs of queries and datapoints whose inner products are high. We provide theoretical grounding to the new quantization loss function, which is simple, intuitive and able to work with a variety of quantization techniques, including binary quantization and product quantization. We conduct experiments on standard benchmarking datasets to demonstrate that our method using the new objective outperforms other state-of-the-art methods.
Local Orthogonal Decomposition for Maximum Inner Product Search
Mar 25, 2019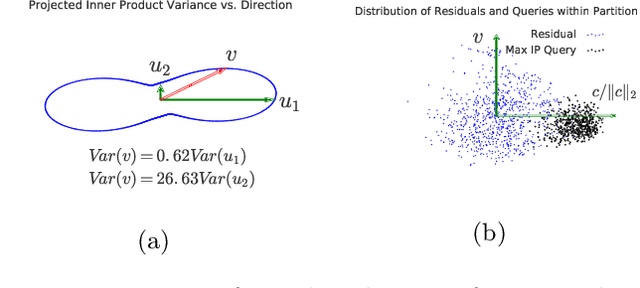

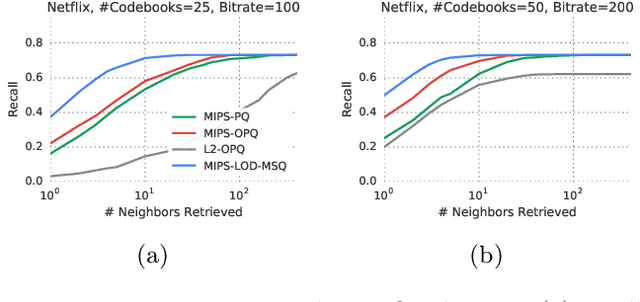
Inverted file and asymmetric distance computation (IVFADC) have been successfully applied to approximate nearest neighbor search and subsequently maximum inner product search. In such a framework, vector quantization is used for coarse partitioning while product quantization is used for quantizing residuals. In the original IVFADC as well as all of its variants, after residuals are computed, the second production quantization step is completely independent of the first vector quantization step. In this work, we seek to exploit the connection between these two steps when we perform non-exhaustive search. More specifically, we decompose a residual vector locally into two orthogonal components and perform uniform quantization and multiscale quantization to each component respectively. The proposed method, called local orthogonal decomposition, combined with multiscale quantization consistently achieves higher recall than previous methods under the same bitrates. We conduct comprehensive experiments on large scale datasets as well as detailed ablation tests, demonstrating effectiveness of our method.
Efficient Inner Product Approximation in Hybrid Spaces
Mar 20, 2019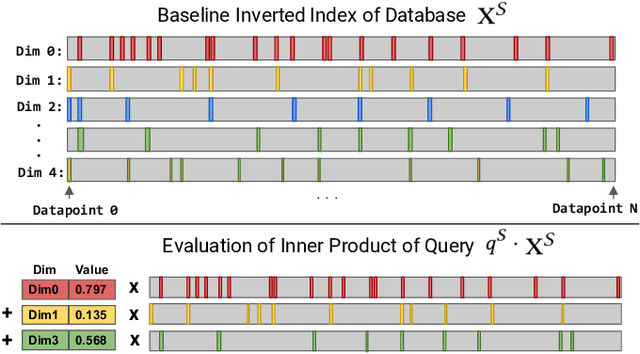
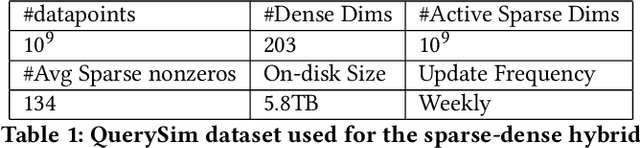
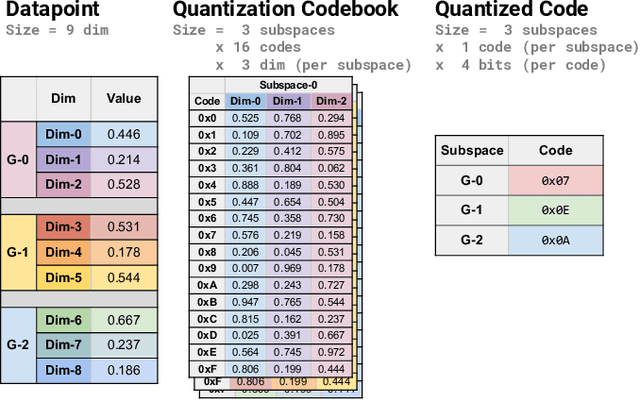
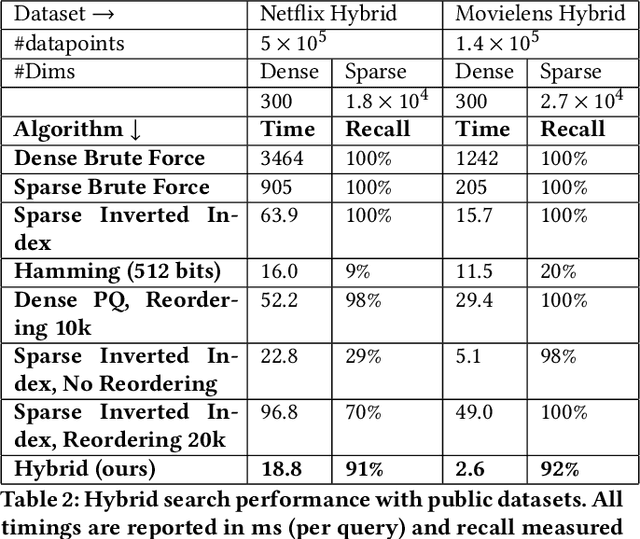
Many emerging use cases of data mining and machine learning operate on large datasets with data from heterogeneous sources, specifically with both sparse and dense components. For example, dense deep neural network embedding vectors are often used in conjunction with sparse textual features to provide high dimensional hybrid representation of documents. Efficient search in such hybrid spaces is very challenging as the techniques that perform well for sparse vectors have little overlap with those that work well for dense vectors. Popular techniques like Locality Sensitive Hashing (LSH) and its data-dependent variants also do not give good accuracy in high dimensional hybrid spaces. Even though hybrid scenarios are becoming more prevalent, currently there exist no efficient techniques in literature that are both fast and accurate. In this paper, we propose a technique that approximates the inner product computation in hybrid vectors, leading to substantial speedup in search while maintaining high accuracy. We also propose efficient data structures that exploit modern computer architectures, resulting in orders of magnitude faster search than the existing baselines. The performance of the proposed method is demonstrated on several datasets including a very large scale industrial dataset containing one billion vectors in a billion dimensional space, achieving over 10x speedup and higher accuracy against competitive baselines.
Quantization based Fast Inner Product Search
Sep 04, 2015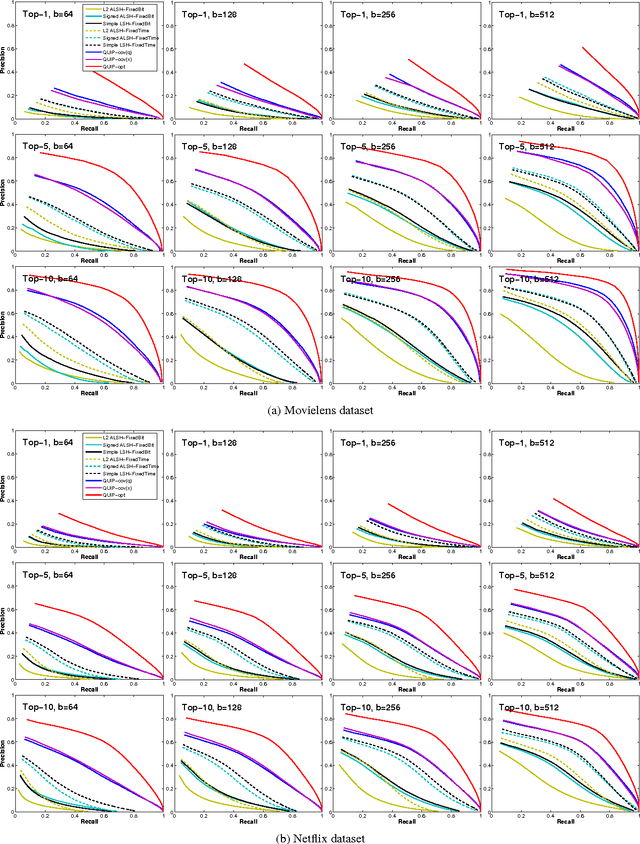
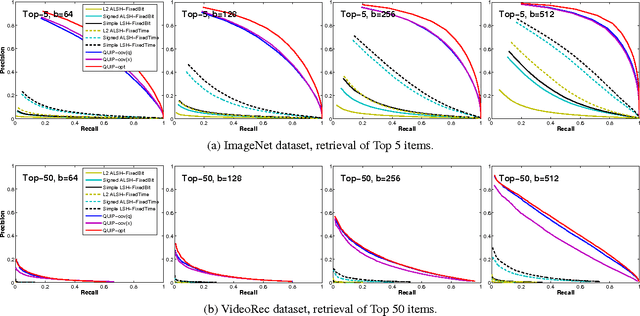
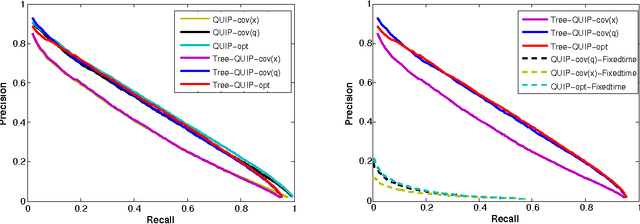
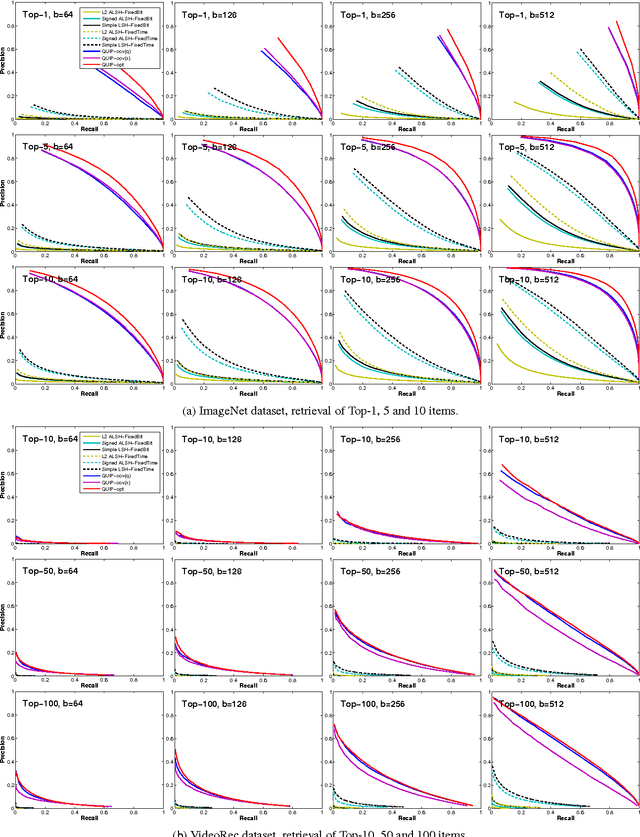
We propose a quantization based approach for fast approximate Maximum Inner Product Search (MIPS). Each database vector is quantized in multiple subspaces via a set of codebooks, learned directly by minimizing the inner product quantization error. Then, the inner product of a query to a database vector is approximated as the sum of inner products with the subspace quantizers. Different from recently proposed LSH approaches to MIPS, the database vectors and queries do not need to be augmented in a higher dimensional feature space. We also provide a theoretical analysis of the proposed approach, consisting of the concentration results under mild assumptions. Furthermore, if a small sample of example queries is given at the training time, we propose a modified codebook learning procedure which further improves the accuracy. Experimental results on a variety of datasets including those arising from deep neural networks show that the proposed approach significantly outperforms the existing state-of-the-art.