 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Inner Product Approximation in Hybrid Spaces
Paper and Code
Mar 20, 2019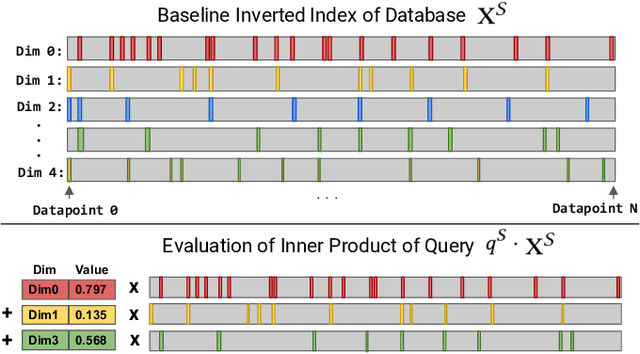
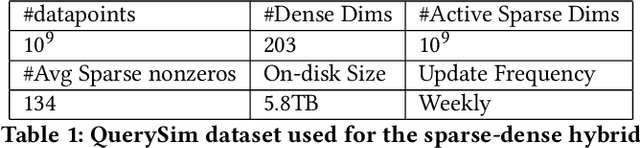
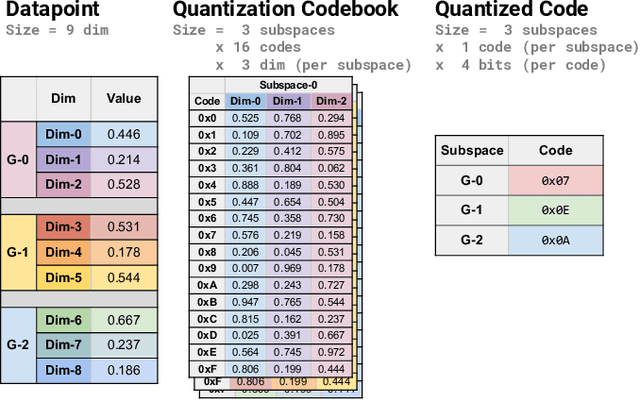
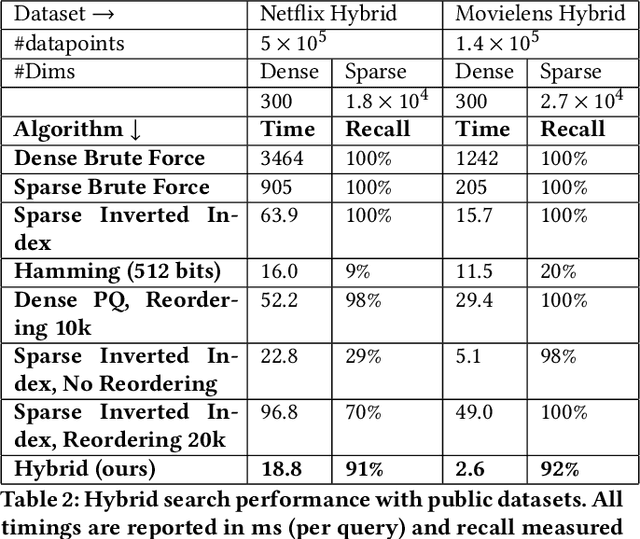
Many emerging use cases of data mining and machine learning operate on large datasets with data from heterogeneous sources, specifically with both sparse and dense components. For example, dense deep neural network embedding vectors are often used in conjunction with sparse textual features to provide high dimensional hybrid representation of documents. Efficient search in such hybrid spaces is very challenging as the techniques that perform well for sparse vectors have little overlap with those that work well for dense vectors. Popular techniques like Locality Sensitive Hashing (LSH) and its data-dependent variants also do not give good accuracy in high dimensional hybrid spaces. Even though hybrid scenarios are becoming more prevalent, currently there exist no efficient techniques in literature that are both fast and accurate. In this paper, we propose a technique that approximates the inner product computation in hybrid vectors, leading to substantial speedup in search while maintaining high accuracy. We also propose efficient data structures that exploit modern computer architectures, resulting in orders of magnitude faster search than the existing baselines. The performance of the proposed method is demonstrated on several datasets including a very large scale industrial dataset containing one billion vectors in a billion dimensional space, achieving over 10x speedup and higher accuracy against competitive baselines.