 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFFN: Multi-view Feature Fusion Network for Camouflaged Object Detection
Oct 19, 2022
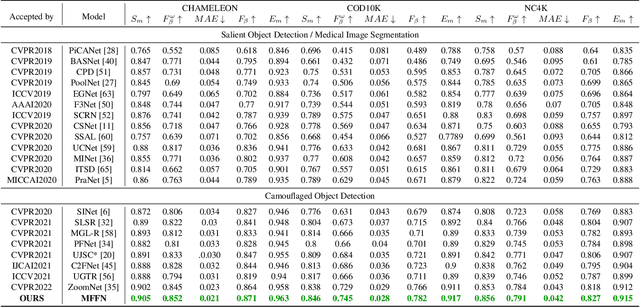
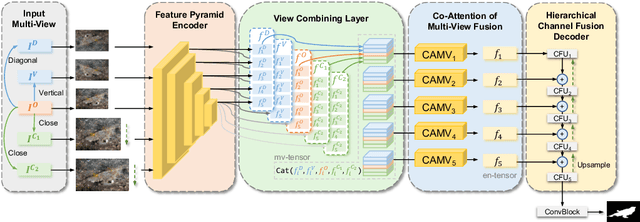

Recent research about camouflaged object detection (COD) aims to segment highly concealed objects hidden in complex surroundings. The tiny, fuzzy camouflaged objects result in visually indistinguishable properties. However, current single-view COD detectors are sensitive to background distractors. Therefore, blurred boundaries and variable shapes of the camouflaged objects are challenging to be fully captured with a single-view detector. To overcome these obstacles, we propose a behavior-inspired framework, called Multi-view Feature Fusion Network (MFFN), which mimics the human behaviors of finding indistinct objects in images, i.e., observing from multiple angles, distances, perspectives. Specifically, the key idea behind it is to generate multiple ways of observation (multi-view) by data augmentation and apply them as inputs. MFFN captures critical boundary and semantic information by comparing and fusing extracted multi-view features. In addition, our MFFN exploits the dependence and interaction between views and channels. Specifically, our methods leverage the complementary information between different views through a two-stage attention module called Co-attention of Multi-view (CAMV). And we design a local-overall module called Channel Fusion Unit (CFU) to explore the channel-wise contextual clues of diverse feature maps in an iterative manner. The experiment results show that our method performs favorably against existing state-of-the-art methods via training with the same data. The code will be available at https://github.com/dwardzheng/MFFN_COD.