 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniMotion: Multimodal Motion Generation with Continuous Masked Autoregression
Oct 16, 2025



Whole-body multi-modal human motion generation poses two primary challenges: creating an effective motion generation mechanism and integrating various modalities, such as text, speech, and music, into a cohesive framework. Unlike previous methods that usually employ discrete masked modeling or autoregressive modeling, we develop a continuous masked autoregressive motion transformer, where a causal attention is performed considering the sequential nature within the human motion. Within this transformer, we introduce a gated linear attention and an RMSNorm module, which drive the transformer to pay attention to the key actions and suppress the instability caused by either the abnormal movements or the heterogeneous distributions within multi-modalities. To further enhance both the motion generation and the multimodal generalization, we employ the DiT structure to diffuse the conditions from the transformer towards the targets. To fuse different modalities, AdaLN and cross-attention are leveraged to inject the text, speech, and music signals. Experimental results demonstrate that our framework outperforms previous methods across all modalities, including text-to-motion, speech-to-gesture, and music-to-dance. The code of our method will be made public.
LHM: Large Animatable Human Reconstruction Model from a Single Image in Seconds
Mar 13, 2025Animatable 3D human reconstruction from a single image is a challenging problem due to the ambiguity in decoupling geometry, appearance, and deformation. Recent advances in 3D human reconstruction mainly focus on static human modeling, and the reliance of using synthetic 3D scans for training limits their generalization ability. Conversely, optimization-based video methods achieve higher fidelity but demand controlled capture conditions and computationally intensive refinement processes. Motivated by the emergence of large reconstruction models for efficient static reconstruction, we propose LHM (Large Animatable Human Reconstruction Model) to infer high-fidelity avatars represented as 3D Gaussian splatting in a feed-forward pass. Our model leverages a multimodal transformer architecture to effectively encode the human body positional features and image features with attention mechanism, enabling detailed preservation of clothing geometry and texture. To further boost the face identity preservation and fine detail recovery, we propose a head feature pyramid encoding scheme to aggregate multi-scale features of the head regions. Extensive experiments demonstrate that our LHM generates plausible animatable human in seconds without post-processing for face and hands, outperforming existing methods in both reconstruction accuracy and generalization ability.
MulSMo: Multimodal Stylized Motion Generation by Bidirectional Control Flow
Dec 13, 2024Generating motion sequences conforming to a target style while adhering to the given content prompts requires accommodating both the content and style. In existing methods, the information usually only flows from style to content, which may cause conflict between the style and content, harming the integration. Differently, in this work we build a bidirectional control flow between the style and the content, also adjusting the style towards the content, in which case the style-content collision is alleviated and the dynamics of the style is better preserved in the integration. Moreover, we extend the stylized motion generation from one modality, i.e. the style motion, to multiple modalities including texts and images through contrastive learning, leading to flexible style control on the motion generation. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, while also enabling multimodal signals control. The code of our method will be made publicly available.
LaMP: Language-Motion Pretraining for Motion Generation, Retrieval, and Captioning
Oct 09, 2024



Language plays a vital role in the realm of human motion. Existing methods have largely depended on CLIP text embeddings for motion generation, yet they fall short in effectively aligning language and motion due to CLIP's pretraining on static image-text pairs. This work introduces LaMP, a novel Language-Motion Pretraining model, which transitions from a language-vision to a more suitable language-motion latent space. It addresses key limitations by generating motion-informative text embeddings, significantly enhancing the relevance and semantics of generated motion sequences. With LaMP, we advance three key tasks: text-to-motion generation, motion-text retrieval, and motion captioning through aligned language-motion representation learning. For generation, we utilize LaMP to provide the text condition instead of CLIP, and an autoregressive masked prediction is designed to achieve mask modeling without rank collapse in transformers. For retrieval, motion features from LaMP's motion transformer interact with query tokens to retrieve text features from the text transformer, and vice versa. For captioning, we finetune a large language model with the language-informative motion features to develop a strong motion captioning model. In addition, we introduce the LaMP-BertScore metric to assess the alignment of generated motions with textual descriptions. Extensive experimental results on multiple datasets demonstrate substantial improvements over previous methods across all three tasks. The code of our method will be made public.
MoGenTS: Motion Generation based on Spatial-Temporal Joint Modeling
Sep 26, 2024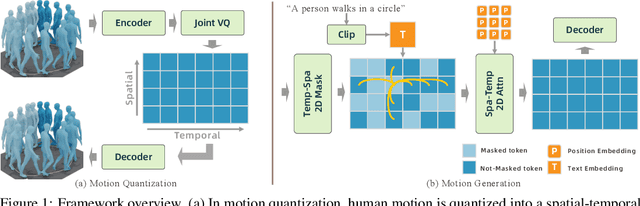
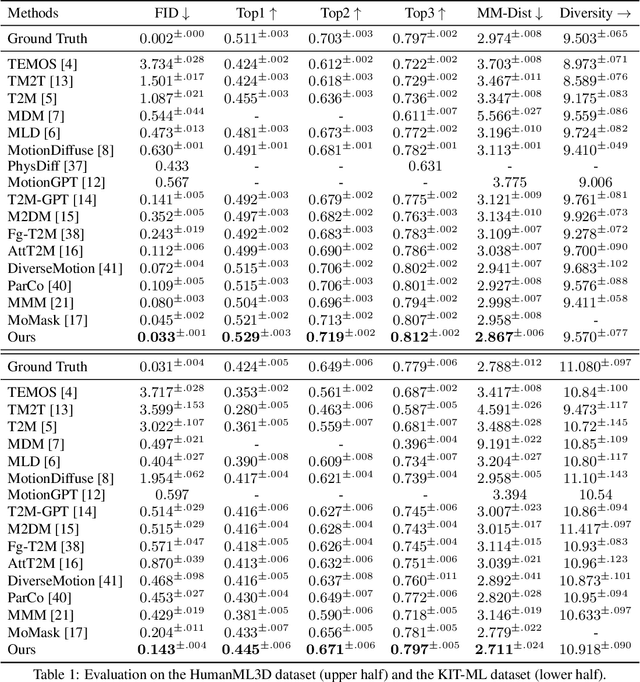
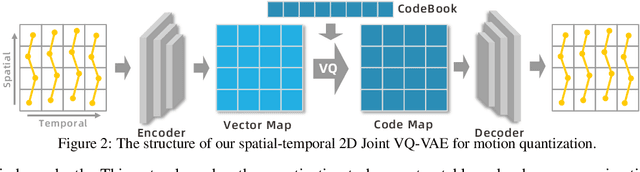
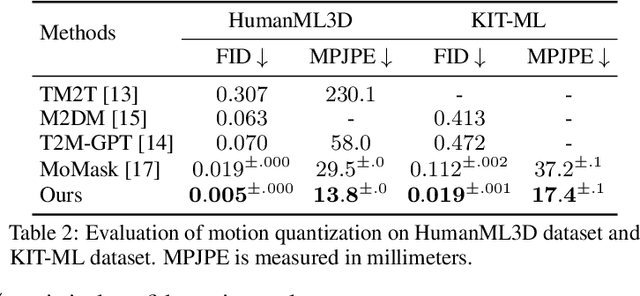
Motion generation from discrete quantization offers many advantages over continuous regression, but at the cost of inevitable approximation errors. Previous methods usually quantize the entire body pose into one code, which not only faces the difficulty in encoding all joints within one vector but also loses the spatial relationship between different joints. Differently, in this work we quantize each individual joint into one vector, which i) simplifies the quantization process as the complexity associated with a single joint is markedly lower than that of the entire pose; ii) maintains a spatial-temporal structure that preserves both the spatial relationships among joints and the temporal movement patterns; iii) yields a 2D token map, which enables the application of various 2D operations widely used in 2D images. Grounded in the 2D motion quantization, we build a spatial-temporal modeling framework, where 2D joint VQVAE, temporal-spatial 2D masking technique, and spatial-temporal 2D attention are proposed to take advantage of spatial-temporal signals among the 2D tokens. Extensive experiments demonstrate that our method significantly outperforms previous methods across different datasets, with a $26.6\%$ decrease of FID on HumanML3D and a $29.9\%$ decrease on KIT-ML.
${S}^{2}$Net: Accurate Panorama Depth Estimation on Spherical Surface
Jan 14, 2023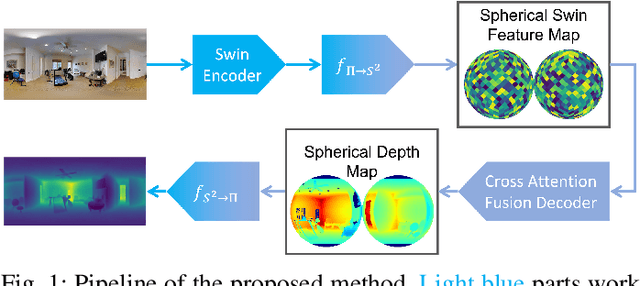

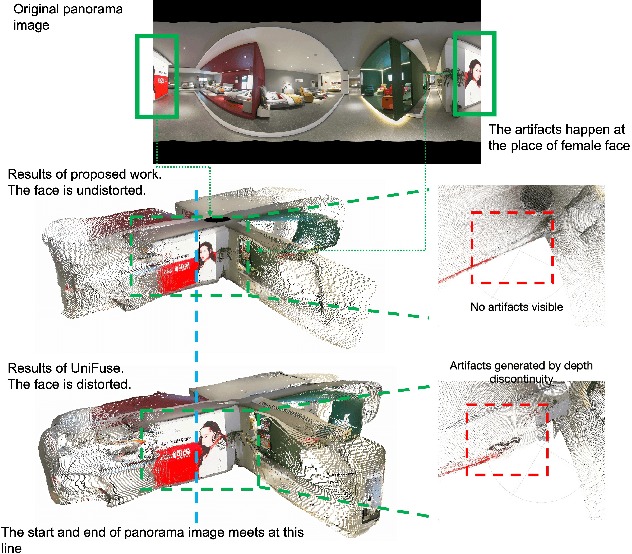
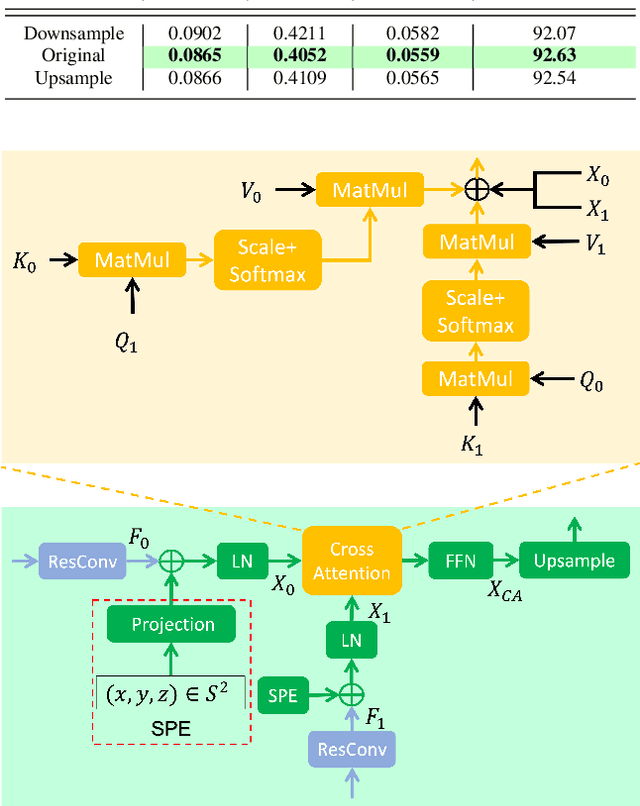
Monocular depth estimation is an ambiguous problem, thus global structural cues play an important role in current data-driven single-view depth estimation methods. Panorama images capture the complete spatial information of their surroundings utilizing the equirectangular projection which introduces large distortion. This requires the depth estimation method to be able to handle the distortion and extract global context information from the image. In this paper, we propose an end-to-end deep network for monocular panorama depth estimation on a unit spherical surface. Specifically, we project the feature maps extracted from equirectangular images onto unit spherical surface sampled by uniformly distributed grids, where the decoder network can aggregate the information from the distortion-reduced feature maps. Meanwhile, we propose a global cross-attention-based fusion module to fuse the feature maps from skip connection and enhance the ability to obtain global context. Experiments are conducted on five panorama depth estimation datasets, and the results demonstrate that the proposed method substantially outperforms previous state-of-the-art methods. All related codes will be open-sourced in the upcoming days.
PanoViT: Vision Transformer for Room Layout Estimation from a Single Panoramic Image
Dec 23, 2022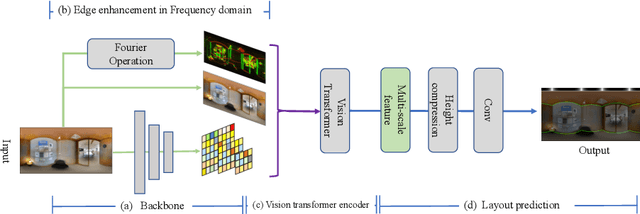
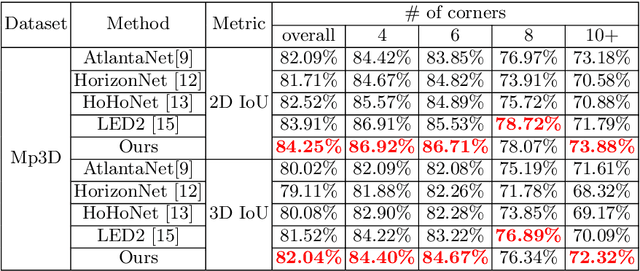
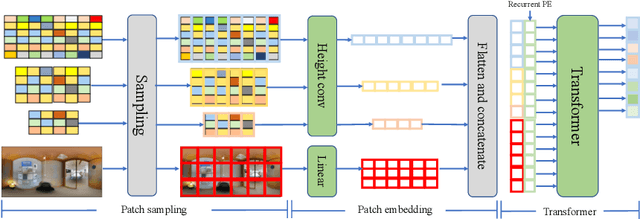
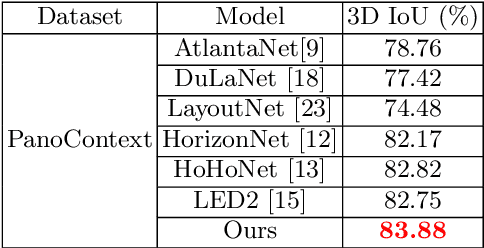
In this paper, we propose PanoViT, a panorama vision transformer to estimate the room layout from a single panoramic image. Compared to CNN models, our PanoViT is more proficient in learning global information from the panoramic image for the estimation of complex room layouts. Considering the difference between a perspective image and an equirectangular image, we design a novel recurrent position embedding and a patch sampling method for the processing of panoramic images. In addition to extracting global information, PanoViT also includes a frequency-domain edge enhancement module and a 3D loss to extract local geometric features in a panoramic image. Experimental results on several datasets demonstrate that our method outperforms state-of-the-art solutions in room layout prediction accuracy.