 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
VideoDirector: Precise Video Editing via Text-to-Video Models
Nov 26, 2024



Despite the typical inversion-then-editing paradigm using text-to-image (T2I) models has demonstrated promising results, directly extending it to text-to-video (T2V) models still suffers severe artifacts such as color flickering and content distortion. Consequently, current video editing methods primarily rely on T2I models, which inherently lack temporal-coherence generative ability, often resulting in inferior editing results. In this paper, we attribute the failure of the typical editing paradigm to: 1) Tightly Spatial-temporal Coupling. The vanilla pivotal-based inversion strategy struggles to disentangle spatial-temporal information in the video diffusion model; 2) Complicated Spatial-temporal Layout. The vanilla cross-attention control is deficient in preserving the unedited content. To address these limitations, we propose a spatial-temporal decoupled guidance (STDG) and multi-frame null-text optimization strategy to provide pivotal temporal cues for more precise pivotal inversion. Furthermore, we introduce a self-attention control strategy to maintain higher fidelity for precise partial content editing. Experimental results demonstrate that our method (termed VideoDirector) effectively harnesses the powerful temporal generation capabilities of T2V models, producing edited videos with state-of-the-art performance in accuracy, motion smoothness, realism, and fidelity to unedited content.
Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation
Jan 27, 2024Recently, text-to-3D approaches have achieved high-fidelity 3D content generation using text description. However, the generated objects are stochastic and lack fine-grained control. Sketches provide a cheap approach to introduce such fine-grained control. Nevertheless, it is challenging to achieve flexible control from these sketches due to their abstraction and ambiguity. In this paper, we present a multi-view sketch-guided text-to-3D generation framework (namely, Sketch2NeRF) to add sketch control to 3D generation. Specifically, our method leverages pretrained 2D diffusion models (e.g., Stable Diffusion and ControlNet) to supervise the optimization of a 3D scene represented by a neural radiance field (NeRF). We propose a novel synchronized generation and reconstruction method to effectively optimize the NeRF. In the experiments, we collected two kinds of multi-view sketch datasets to evaluate the proposed method. We demonstrate that our method can synthesize 3D consistent contents with fine-grained sketch control while being high-fidelity to text prompts. Extensive results show that our method achieves state-of-the-art performance in terms of sketch similarity and text alignment.
EFMVFL: An Efficient and Flexible Multi-party Vertical Federated Learning without a Third Party
Jan 17, 2022Federated learning allows multiple participants to conduct joint modeling without disclosing their local data. Vertical federated learning (VFL) handles the situation where participants share the same ID space and different feature spaces. In most VFL frameworks, to protect the security and privacy of the participants' local data, a third party is needed to generate homomorphic encryption key pairs and perform decryption operations. In this way, the third party is granted the right to decrypt information related to model parameters. However, it isn't easy to find such a credible entity in the real world. Existing methods for solving this problem are either communication-intensive or unsuitable for multi-party scenarios. By combining secret sharing and homomorphic encryption, we propose a novel VFL framework without a third party called EFMVFL, which supports flexible expansion to multiple participants with low communication overhead and is applicable to generalized linear models. We give instantiations of our framework under logistic regression and Poisson regression. Theoretical analysis and experiments show that our framework is secure, more efficient, and easy to be extended to multiple participants.
A Distributional Robustness Certificate by Randomized Smoothing
Oct 21, 2020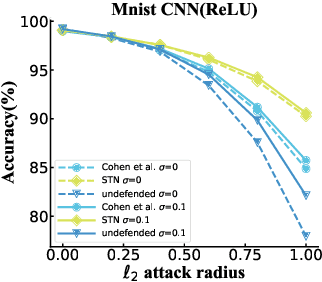

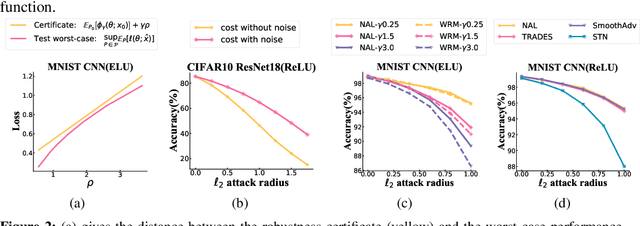
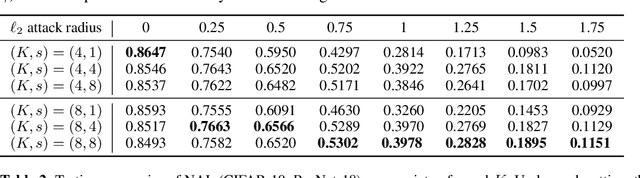
The robustness of deep neural networks against adversarial example attacks has received much attention recently. We focus on certified robustness of smoothed classifiers in this work, and propose to use the worst-case population loss over noisy inputs as a robustness metric. Under this metric, we provide a tractable upper bound serving as a robustness certificate by exploiting the duality. To improve the robustness, we further propose a noisy adversarial learning procedure to minimize the upper bound following the robust optimization framework. The smoothness of the loss function ensures the problem easy to optimize even for non-smooth neural networks. We show how our robustness certificate compares with others and the improvement over previous works. Experiments on a variety of datasets and models verify that in terms of empirical accuracies, our approach exceeds the state-of-the-art certified/heuristic methods in defending adversarial examples.