 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Concepts Lie Within? Detecting and Suppressing Risky Content in Diffusion Transformers
May 11, 2026The rise of text-to-image (T2I) models has increasingly raised concerns regarding the generation of risky content, such as sexual, violent, and copyright-protected images, highlighting the need for effective safeguards within the models themselves. Although existing methods have been proposed to eliminate risky concepts from T2I models, they are primarily developed for earlier U-Net architectures, leaving the state-of-the-art Diffusion-Transformer-based T2I models inadequately protected. This gap stems from a fundamental architectural shift: Diffusion Transformers (DiTs) entangle semantic injection and visual synthesis via joint attention, which makes it difficult to isolate and erase risky content within the generation. To bridge this gap, we investigate how semantic concepts are represented in DiTs and discover that attention heads exhibit concept-specific sensitivity. This property enables both the detection and suppression of risky content. Building on this discovery, we propose AHV-D\&S, a training-free inference-time safeguard for image generation in DiTs. Specifically, AHV-D\&S quantifies each textual token's sensitivity across all attention heads as an Attention Head Vector (AHV), which serves as a discriminative signature for detecting risky generation tendencies. In the inference stage, we propose a momentum-based strategy to dynamically track token-wise AHVs across denoising steps, and a sensitivity-guided adaptive suppression strategy that suppresses the attention weights of identified risky tokens based on head-specific risk scores. Extensive experiments demonstrate that AHV-D\&S effectively suppresses sexual, copyrighted-style, and various harmful content while preserving visual quality, and further exhibits strong robustness against adversarial prompts and transferability across different DiT-based T2I models.
What if Agents Could Imagine? Reinforcing Open-Vocabulary HOI Comprehension through Generation
Feb 12, 2026Multimodal Large Language Models have shown promising capabilities in bridging visual and textual reasoning, yet their reasoning capabilities in Open-Vocabulary Human-Object Interaction (OV-HOI) are limited by cross-modal hallucinations and occlusion-induced ambiguity. To address this, we propose \textbf{ImagineAgent}, an agentic framework that harmonizes cognitive reasoning with generative imagination for robust visual understanding. Specifically, our method innovatively constructs cognitive maps that explicitly model plausible relationships between detected entities and candidate actions. Subsequently, it dynamically invokes tools including retrieval augmentation, image cropping, and diffusion models to gather domain-specific knowledge and enriched visual evidence, thereby achieving cross-modal alignment in ambiguous scenarios. Moreover, we propose a composite reward that balances prediction accuracy and tool efficiency. Evaluations on SWIG-HOI and HICO-DET datasets demonstrate our SOTA performance, requiring approximately 20\% of training data compared to existing methods, validating our robustness and efficiency.
T2I-RiskyPrompt: A Benchmark for Safety Evaluation, Attack, and Defense on Text-to-Image Model
Oct 25, 2025



Using risky text prompts, such as pornography and violent prompts, to test the safety of text-to-image (T2I) models is a critical task. However, existing risky prompt datasets are limited in three key areas: 1) limited risky categories, 2) coarse-grained annotation, and 3) low effectiveness. To address these limitations, we introduce T2I-RiskyPrompt, a comprehensive benchmark designed for evaluating safety-related tasks in T2I models. Specifically, we first develop a hierarchical risk taxonomy, which consists of 6 primary categories and 14 fine-grained subcategories. Building upon this taxonomy, we construct a pipeline to collect and annotate risky prompts. Finally, we obtain 6,432 effective risky prompts, where each prompt is annotated with both hierarchical category labels and detailed risk reasons. Moreover, to facilitate the evaluation, we propose a reason-driven risky image detection method that explicitly aligns the MLLM with safety annotations. Based on T2I-RiskyPrompt, we conduct a comprehensive evaluation of eight T2I models, nine defense methods, five safety filters, and five attack strategies, offering nine key insights into the strengths and limitations of T2I model safety. Finally, we discuss potential applications of T2I-RiskyPrompt across various research fields. The dataset and code are provided in https://github.com/datar001/T2I-RiskyPrompt.
TRCE: Towards Reliable Malicious Concept Erasure in Text-to-Image Diffusion Models
Mar 10, 2025Recent advances in text-to-image diffusion models enable photorealistic image generation, but they also risk producing malicious content, such as NSFW images. To mitigate risk, concept erasure methods are studied to facilitate the model to unlearn specific concepts. However, current studies struggle to fully erase malicious concepts implicitly embedded in prompts (e.g., metaphorical expressions or adversarial prompts) while preserving the model's normal generation capability. To address this challenge, our study proposes TRCE, using a two-stage concept erasure strategy to achieve an effective trade-off between reliable erasure and knowledge preservation. Firstly, TRCE starts by erasing the malicious semantics implicitly embedded in textual prompts. By identifying a critical mapping objective(i.e., the [EoT] embedding), we optimize the cross-attention layers to map malicious prompts to contextually similar prompts but with safe concepts. This step prevents the model from being overly influenced by malicious semantics during the denoising process. Following this, considering the deterministic properties of the sampling trajectory of the diffusion model, TRCE further steers the early denoising prediction toward the safe direction and away from the unsafe one through contrastive learning, thus further avoiding the generation of malicious content. Finally, we conduct comprehensive evaluations of TRCE on multiple malicious concept erasure benchmarks, and the results demonstrate its effectiveness in erasing malicious concepts while better preserving the model's original generation ability. The code is available at: http://github.com/ddgoodgood/TRCE. CAUTION: This paper includes model-generated content that may contain offensive material.
Point-PC: Point Cloud Completion Guided by Prior Knowledge via Causal Inference
May 28, 2023Point cloud completion aims to recover raw point clouds captured by scanners from partial observations caused by occlusion and limited view angles. Many approaches utilize a partial-complete paradigm in which missing parts are directly predicted by a global feature learned from partial inputs. This makes it hard to recover details because the global feature is unlikely to capture the full details of all missing parts. In this paper, we propose a novel approach to point cloud completion called Point-PC, which uses a memory network to retrieve shape priors and designs an effective causal inference model to choose missing shape information as additional geometric information to aid point cloud completion. Specifically, we propose a memory operating mechanism where the complete shape features and the corresponding shapes are stored in the form of ``key-value'' pairs. To retrieve similar shapes from the partial input, we also apply a contrastive learning-based pre-training scheme to transfer features of incomplete shapes into the domain of complete shape features. Moreover, we use backdoor adjustment to get rid of the confounder, which is a part of the shape prior that has the same semantic structure as the partial input. Experimental results on the ShapeNet-55, PCN, and KITTI datasets demonstrate that Point-PC performs favorably against the state-of-the-art methods.
T2TD: Text-3D Generation Model based on Prior Knowledge Guidance
May 25, 2023



In recent years, 3D models have been utilized in many applications, such as auto-driver, 3D reconstruction, VR, and AR. However, the scarcity of 3D model data does not meet its practical demands. Thus, generating high-quality 3D models efficiently from textual descriptions is a promising but challenging way to solve this problem. In this paper, inspired by the ability of human beings to complement visual information details from ambiguous descriptions based on their own experience, we propose a novel text-3D generation model (T2TD), which introduces the related shapes or textual information as the prior knowledge to improve the performance of the 3D generation model. In this process, we first introduce the text-3D knowledge graph to save the relationship between 3D models and textual semantic information, which can provide the related shapes to guide the target 3D model generation. Second, we integrate an effective causal inference model to select useful feature information from these related shapes, which removes the unrelated shape information and only maintains feature information that is strongly relevant to the textual description. Meanwhile, to effectively integrate multi-modal prior knowledge into textual information, we adopt a novel multi-layer transformer structure to progressively fuse related shape and textual information, which can effectively compensate for the lack of structural information in the text and enhance the final performance of the 3D generation model. The final experimental results demonstrate that our approach significantly improves 3D model generation quality and outperforms the SOTA methods on the text2shape datasets.
A Distributional Robustness Certificate by Randomized Smoothing
Oct 21, 2020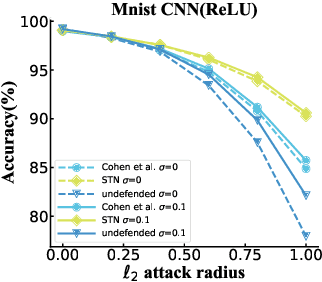

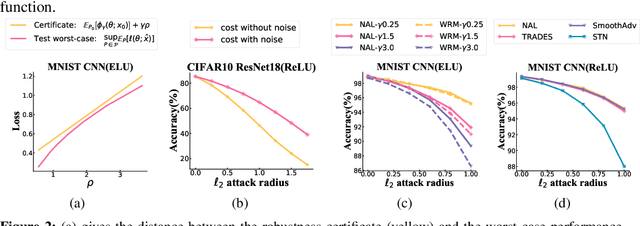
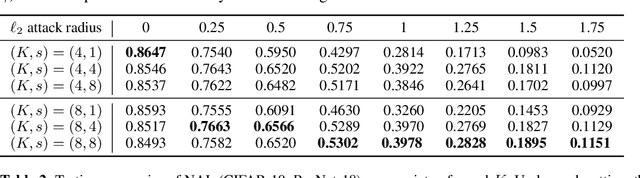
The robustness of deep neural networks against adversarial example attacks has received much attention recently. We focus on certified robustness of smoothed classifiers in this work, and propose to use the worst-case population loss over noisy inputs as a robustness metric. Under this metric, we provide a tractable upper bound serving as a robustness certificate by exploiting the duality. To improve the robustness, we further propose a noisy adversarial learning procedure to minimize the upper bound following the robust optimization framework. The smoothness of the loss function ensures the problem easy to optimize even for non-smooth neural networks. We show how our robustness certificate compares with others and the improvement over previous works. Experiments on a variety of datasets and models verify that in terms of empirical accuracies, our approach exceeds the state-of-the-art certified/heuristic methods in defending adversarial examples.