 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Modal Neuro-Symbolic Approach for Spatial Reasoning-Based Visual Grounding in Robotics
Oct 30, 2025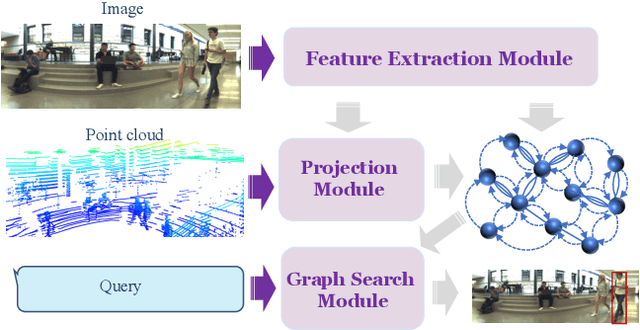
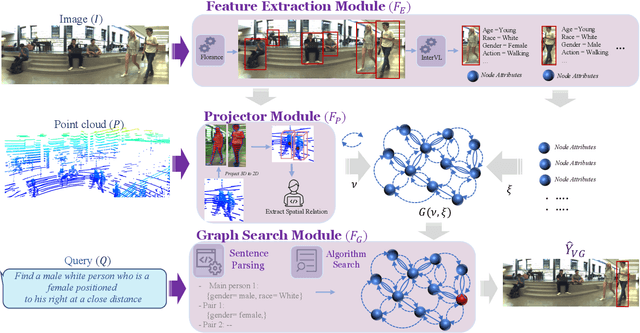

Visual reasoning, particularly spatial reasoning, is a challenging cognitive task that requires understanding object relationships and their interactions within complex environments, especially in robotics domain. Existing vision_language models (VLMs) excel at perception tasks but struggle with fine-grained spatial reasoning due to their implicit, correlation-driven reasoning and reliance solely on images. We propose a novel neuro_symbolic framework that integrates both panoramic-image and 3D point cloud information, combining neural perception with symbolic reasoning to explicitly model spatial and logical relationships. Our framework consists of a perception module for detecting entities and extracting attributes, and a reasoning module that constructs a structured scene graph to support precise, interpretable queries. Evaluated on the JRDB-Reasoning dataset, our approach demonstrates superior performance and reliability in crowded, human_built environments while maintaining a lightweight design suitable for robotics and embodied AI applications.
JRDB-Reasoning: A Difficulty-Graded Benchmark for Visual Reasoning in Robotics
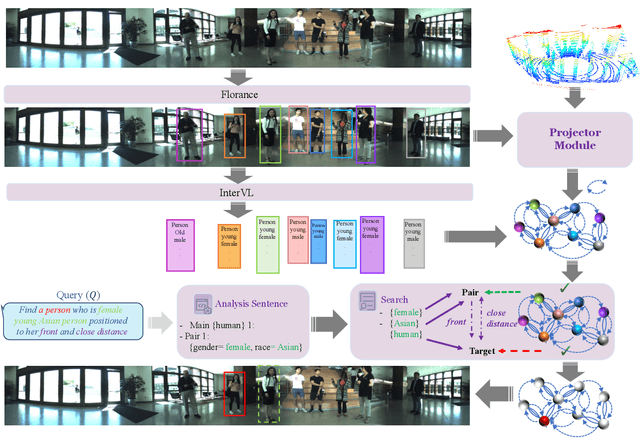
Aug 14, 2025Recent advances in Vision-Language Models (VLMs) and large language models (LLMs) have greatly enhanced visual reasoning, a key capability for embodied AI agents like robots. However, existing visual reasoning benchmarks often suffer from several limitations: they lack a clear definition of reasoning complexity, offer have no control to generate questions over varying difficulty and task customization, and fail to provide structured, step-by-step reasoning annotations (workflows). To bridge these gaps, we formalize reasoning complexity, introduce an adaptive query engine that generates customizable questions of varying complexity with detailed intermediate annotations, and extend the JRDB dataset with human-object interaction and geometric relationship annotations to create JRDB-Reasoning, a benchmark tailored for visual reasoning in human-crowded environments. Our engine and benchmark enable fine-grained evaluation of visual reasoning frameworks and dynamic assessment of visual-language models across reasoning levels.
JRDB-Social: A Multifaceted Robotic Dataset for Understanding of Context and Dynamics of Human Interactions Within Social Groups
Apr 06, 2024



Understanding human social behaviour is crucial in computer vision and robotics. Micro-level observations like individual actions fall short, necessitating a comprehensive approach that considers individual behaviour, intra-group dynamics, and social group levels for a thorough understanding. To address dataset limitations, this paper introduces JRDB-Social, an extension of JRDB. Designed to fill gaps in human understanding across diverse indoor and outdoor social contexts, JRDB-Social provides annotations at three levels: individual attributes, intra-group interactions, and social group context. This dataset aims to enhance our grasp of human social dynamics for robotic applications. Utilizing the recent cutting-edge multi-modal large language models, we evaluated our benchmark to explore their capacity to decipher social human behaviour.
HYDRA: A Hyper Agent for Dynamic Compositional Visual Reasoning
Mar 19, 2024



Recent advances in visual reasoning (VR), particularly with the aid of Large Vision-Language Models (VLMs), show promise but require access to large-scale datasets and face challenges such as high computational costs and limited generalization capabilities. Compositional visual reasoning approaches have emerged as effective strategies; however, they heavily rely on the commonsense knowledge encoded in Large Language Models (LLMs) to perform planning, reasoning, or both, without considering the effect of their decisions on the visual reasoning process, which can lead to errors or failed procedures. To address these challenges, we introduce HYDRA, a multi-stage dynamic compositional visual reasoning framework designed for reliable and incrementally progressive general reasoning. HYDRA integrates three essential modules: a planner, a Reinforcement Learning (RL) agent serving as a cognitive controller, and a reasoner. The planner and reasoner modules utilize an LLM to generate instruction samples and executable code from the selected instruction, respectively, while the RL agent dynamically interacts with these modules, making high-level decisions on selection of the best instruction sample given information from the historical state stored through a feedback loop. This adaptable design enables HYDRA to adjust its actions based on previous feedback received during the reasoning process, leading to more reliable reasoning outputs and ultimately enhancing its overall effectiveness. Our framework demonstrates state-of-the-art performance in various VR tasks on four different widely-used datasets.
Real-time Trajectory-based Social Group Detection
Apr 12, 2023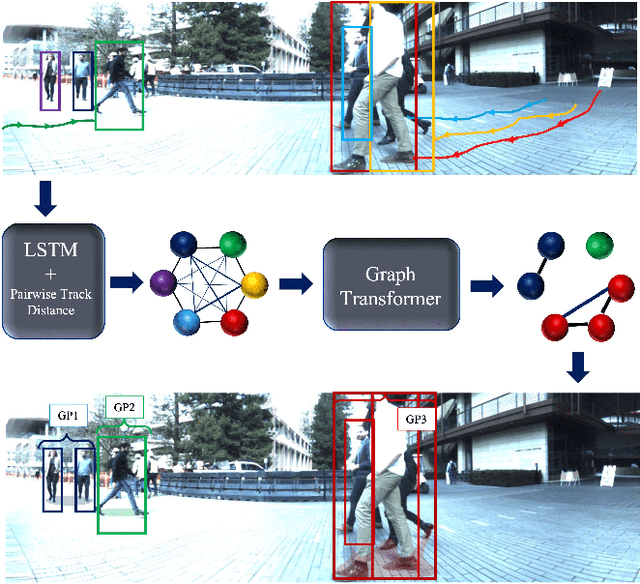
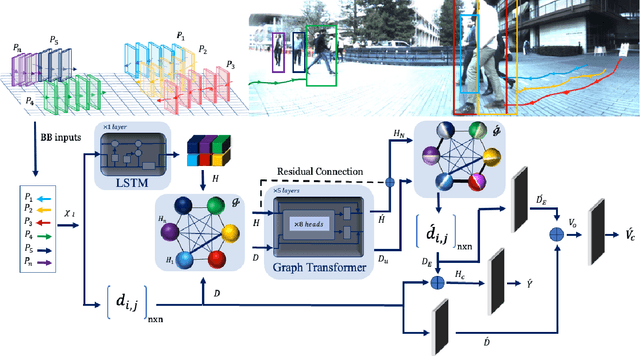
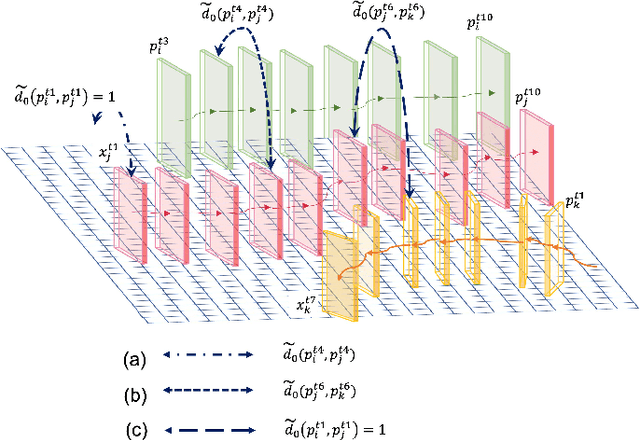

Social group detection is a crucial aspect of various robotic applications, including robot navigation and human-robot interactions. To date, a range of model-based techniques have been employed to address this challenge, such as the F-formation and trajectory similarity frameworks. However, these approaches often fail to provide reliable results in crowded and dynamic scenarios. Recent advancements in this area have mainly focused on learning-based methods, such as deep neural networks that use visual content or human pose. Although visual content-based methods have demonstrated promising performance on large-scale datasets, their computational complexity poses a significant barrier to their practical use in real-time applications. To address these issues, we propose a simple and efficient framework for social group detection. Our approach explores the impact of motion trajectory on social grouping and utilizes a novel, reliable, and fast data-driven method. We formulate the individuals in a scene as a graph, where the nodes are represented by LSTM-encoded trajectories and the edges are defined by the distances between each pair of tracks. Our framework employs a modified graph transformer module and graph clustering losses to detect social groups. Our experiments on the popular JRDBAct dataset reveal noticeable improvements in performance, with relative improvements ranging from 2% to 11%. Furthermore, our framework is significantly faster, with up to 12x faster inference times compared to state-of-the-art methods under the same computation resources. These results demonstrate that our proposed method is suitable for real-time robotic applications.
DoubleU-Net++: Architecture with Exploit Multiscale Features for Vertebrae Segmentation
Jan 28, 2022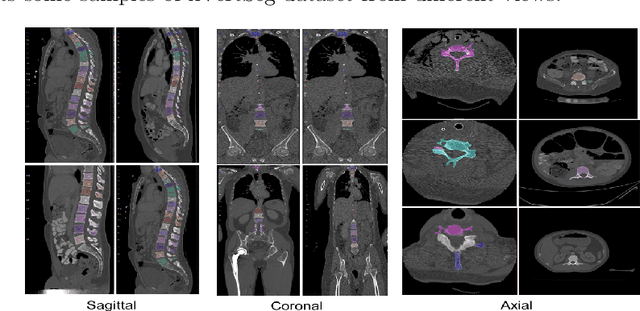
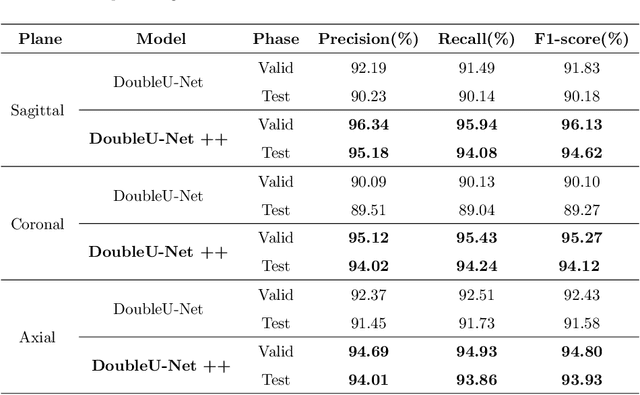
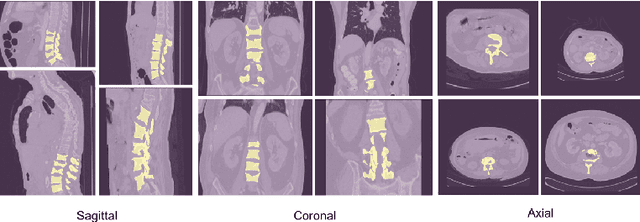
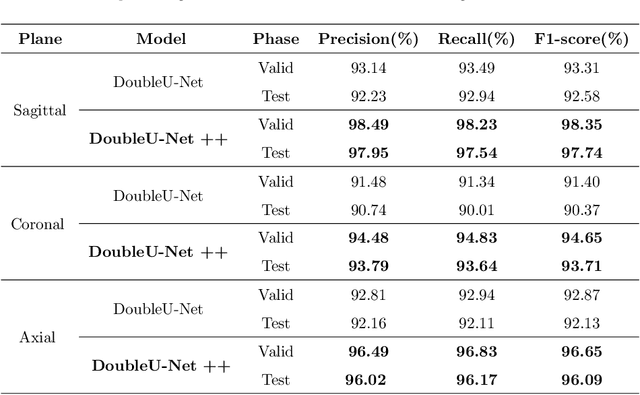
Accurate segmentation of the vertebra is an important prerequisite in various medical applications (E.g. tele surgery) to assist surgeons. Following the successful development of deep neural networks, recent studies have focused on the essential rule of vertebral segmentation. Prior works contain a large number of parameters, and their segmentation is restricted to only one view. Inspired by DoubleU-Net, we propose a novel model named DoubleU-Net++ in which DensNet as feature extractor, special attention module from Convolutional Block Attention on Module (CBAM) and, Pyramid Squeeze Attention (PSA) module are employed to improve extracted features. We evaluate our proposed model on three different views (sagittal, coronal, and axial) of VerSe2020 and xVertSeg datasets. Compared with state-of-the-art studies, our architecture is trained faster and achieves higher precision, recall, and F1-score as evaluation (imporoved by 4-6%) and the result of above 94% for sagittal view and above 94% for both coronal view and above 93% axial view were gained for VerSe2020 dataset, respectively. Also, for xVertSeg dataset, we achieved precision, recall,and F1-score of above 97% for sagittal view, above 93% for coronal view ,and above 96% for axial view.
Predicting Driver Intention Using Deep Neural Network
Jun 01, 2021



To improve driving safety and avoid car accidents, Advanced Driver Assistance Systems (ADAS) are given significant attention. Recent studies have focused on predicting driver intention as a key part of these systems. In this study, we proposed new framework in which 4 inputs are employed to anticipate diver maneuver using Brain4Cars dataset and the maneuver prediction is achieved from 5, 4, 3, 2, 1 seconds before the actual action occurs. We evaluated our framework in three scenarios: using only 1) inside view 2) outside view and 3) both inside and outside view. We divided the dataset into training, validation and test sets, also K-fold cross validation is utilized. Compared with state-of-the-art studies, our architecture is faster and achieved higher performance in second and third scenario. Accuracy, precision, recall and f1-score as evaluation metrics were utilized and the result of 82.41%, 82.28%, 82,42% and 82.24% for outside view and 98.90%, 98.96%, 98.90% and 98.88% for both inside and outside view were gained, respectively.
Persian Handwritten Digit, Character, and Words Recognition by Using Deep Learning Methods
Oct 24, 2020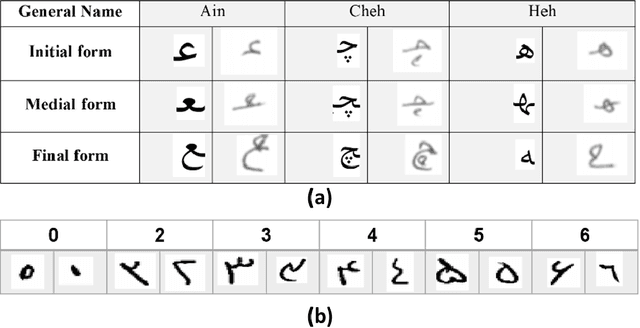
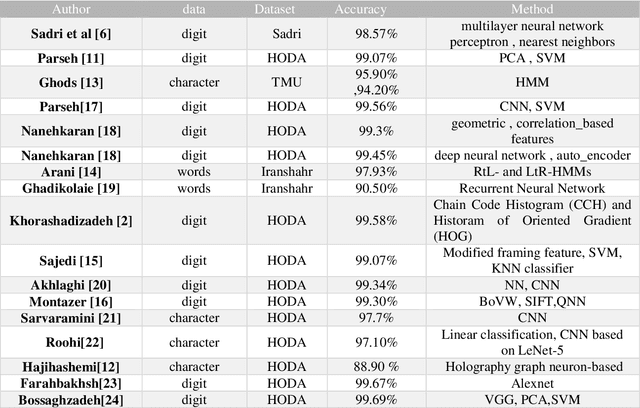
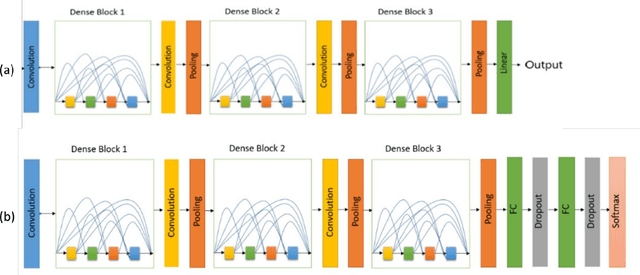
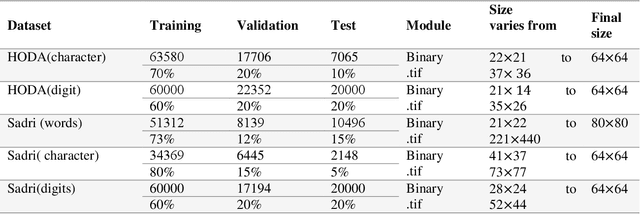
Digit, character, and word recognition of a particular script play a key role in the field of pattern recognition. These days, Optical Character Recognition (OCR) systems are widely used in commercial market in various applications. In recent years, there are intensive research studies on optical character, digit, and word recognition. However, only a limited number of works are offered for numeral, character, and word recognition of Persian scripts. In this paper, we have used deep neural network and investigated different versions of DensNet models and Xception and compare our results with the state-of-the-art methods and approaches in recognizing Persian character, number, and word. Two holistic Persian handwritten datasets, HODA and Sadri, have been used. For a comparison of our proposed deep neural network with previously published research studies, the best state-of-the-art results have been considered. We used accuracy as our criteria for evaluation. For HODA dataset, we achieved 99.72% and 89.99% for digit and character, respectively. For Sadri dataset, we obtained accuracy rates of 99.72%, 98.32%, and 98.82% for digit, character, and words, respectively.
U-Net Based Architecture for an Improved Multiresolution Segmentation in Medical Images
Jul 17, 2020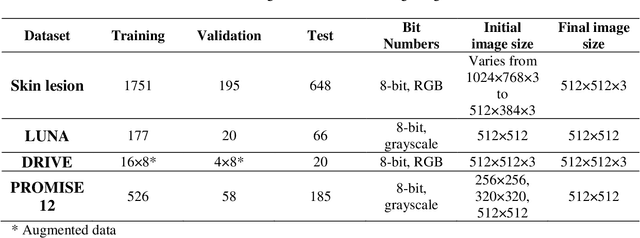
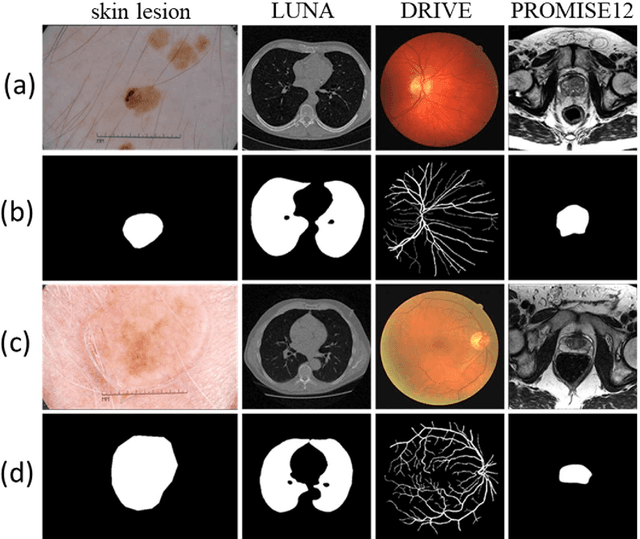
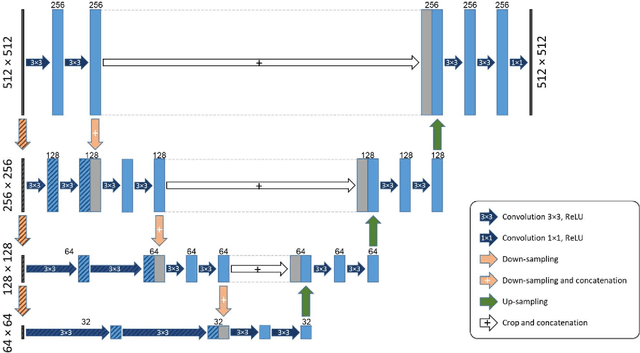
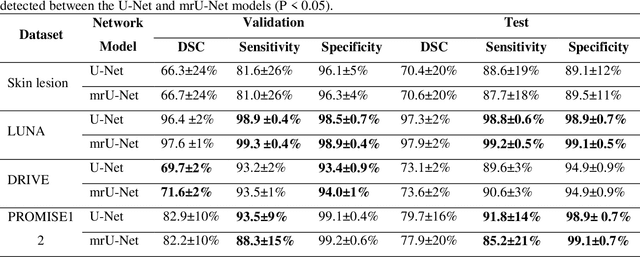
Purpose: Manual medical image segmentation is an exhausting and time-consuming task along with high inter-observer variability. In this study, our objective is to improve the multi-resolution image segmentation performance of U-Net architecture. Approach: We have proposed a fully convolutional neural network for image segmentation in a multi-resolution framework. We used U-Net as the base architecture and modified that to improve its image segmentation performance. In the proposed architecture (mrU-Net), the input image and its down-sampled versions were used as the network inputs. We added more convolution layers to extract features directly from the down-sampled images. We trained and tested the network on four different medical datasets, including skin lesion photos, lung computed tomography (CT) images (LUNA dataset), retina images (DRIVE dataset), and prostate magnetic resonance (MR) images (PROMISE12 dataset). We compared the performance of mrU-Net to U-Net under similar training and testing conditions. Results: Comparing the results to manual segmentation labels, mrU-Net achieved average Dice similarity coefficients of 70.6%, 97.9%, 73.6%, and 77.9% for the skin lesion, LUNA, DRIVE, and PROMISE12 segmentation, respectively. For the skin lesion, LUNA, and DRIVE datasets, mrU-Net outperformed U-Net with significantly higher accuracy and for the PROMISE12 dataset, both networks achieved similar accuracy. Furthermore, using mrU-Net led to a faster training rate on LUNA and DRIVE datasets when compared to U-Net. Conclusions: The striking feature of the proposed architecture is its higher capability in extracting image-derived features compared to U-Net. mrU-Net illustrated a faster training rate and slightly more accurate image segmentation compared to U-Net.
In Situ Cane Toad Recognition
Jun 09, 2019
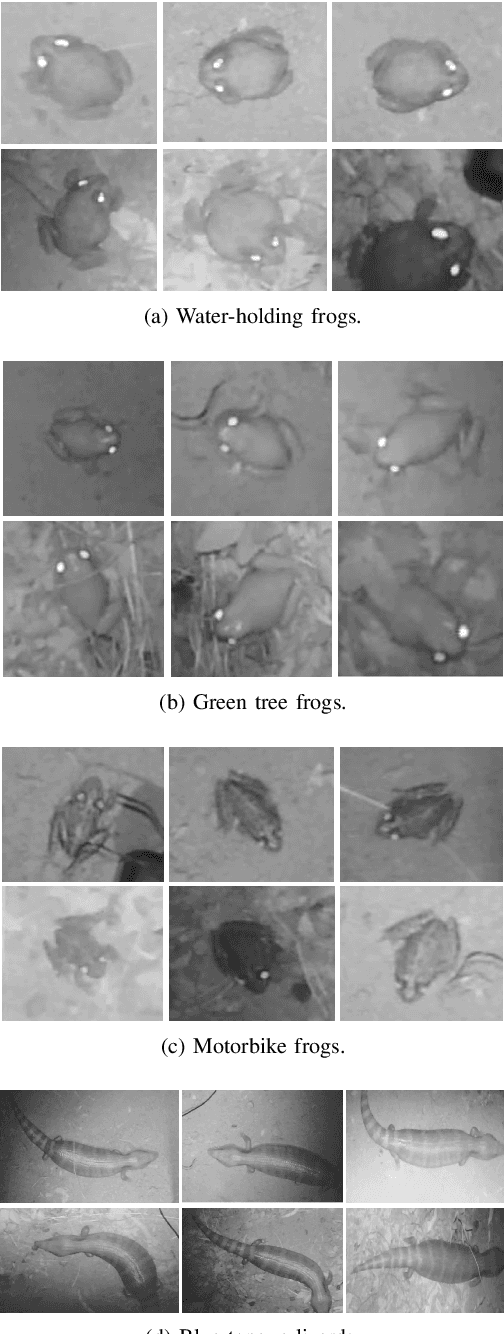


Cane toads are invasive, toxic to native predators, compete with native insectivores, and have a devastating impact on Australian ecosystems, prompting the Australian government to list toads as a key threatening process under the Environment Protection and Biodiversity Conservation Act 1999. Mechanical cane toad traps could be made more native-fauna friendly if they could distinguish invasive cane toads from native species. Here we designed and trained a Convolution Neural Network (CNN) starting from the Xception CNN. The XToadGmp toad-recognition CNN we developed was trained end-to-end using heat-map Gaussian targets. After training, XToadGmp required minimum image pre/post-processing and when tested on 720x1280 shaped images, it achieved 97.1% classification accuracy on 1863 toad and 2892 not-toad test images, which were not used in training.
* Accepted for DICTA2018 https://doi.org/10.1109/DICTA.2018.8615780