 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeU-Net Based Architecture for an Improved Multiresolution Segmentation in Medical Images
Paper and Code
Jul 17, 2020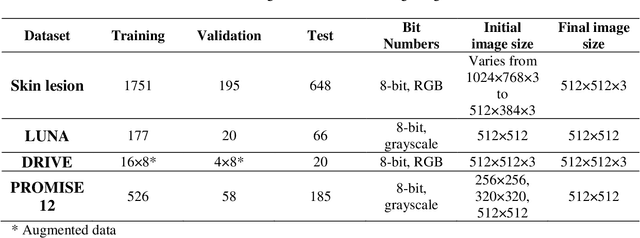
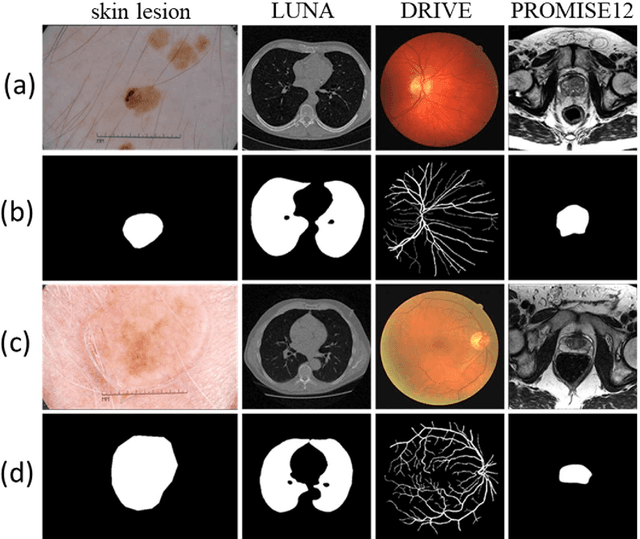
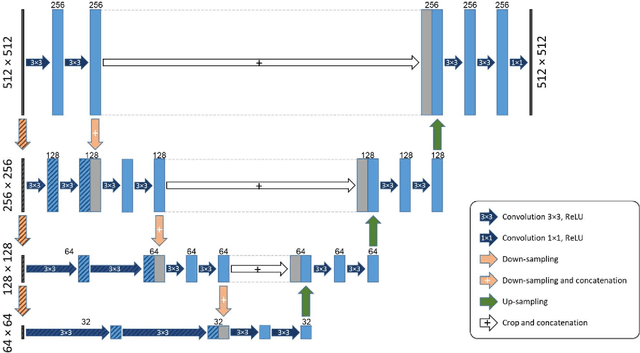
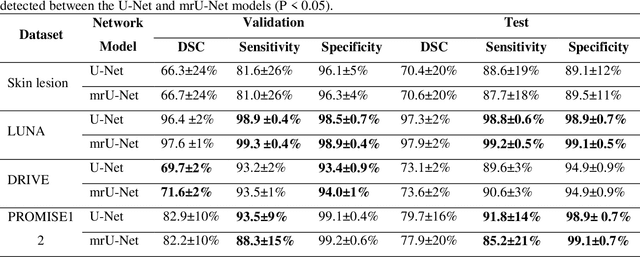
Purpose: Manual medical image segmentation is an exhausting and time-consuming task along with high inter-observer variability. In this study, our objective is to improve the multi-resolution image segmentation performance of U-Net architecture. Approach: We have proposed a fully convolutional neural network for image segmentation in a multi-resolution framework. We used U-Net as the base architecture and modified that to improve its image segmentation performance. In the proposed architecture (mrU-Net), the input image and its down-sampled versions were used as the network inputs. We added more convolution layers to extract features directly from the down-sampled images. We trained and tested the network on four different medical datasets, including skin lesion photos, lung computed tomography (CT) images (LUNA dataset), retina images (DRIVE dataset), and prostate magnetic resonance (MR) images (PROMISE12 dataset). We compared the performance of mrU-Net to U-Net under similar training and testing conditions. Results: Comparing the results to manual segmentation labels, mrU-Net achieved average Dice similarity coefficients of 70.6%, 97.9%, 73.6%, and 77.9% for the skin lesion, LUNA, DRIVE, and PROMISE12 segmentation, respectively. For the skin lesion, LUNA, and DRIVE datasets, mrU-Net outperformed U-Net with significantly higher accuracy and for the PROMISE12 dataset, both networks achieved similar accuracy. Furthermore, using mrU-Net led to a faster training rate on LUNA and DRIVE datasets when compared to U-Net. Conclusions: The striking feature of the proposed architecture is its higher capability in extracting image-derived features compared to U-Net. mrU-Net illustrated a faster training rate and slightly more accurate image segmentation compared to U-Net.