 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations
Jul 28, 2025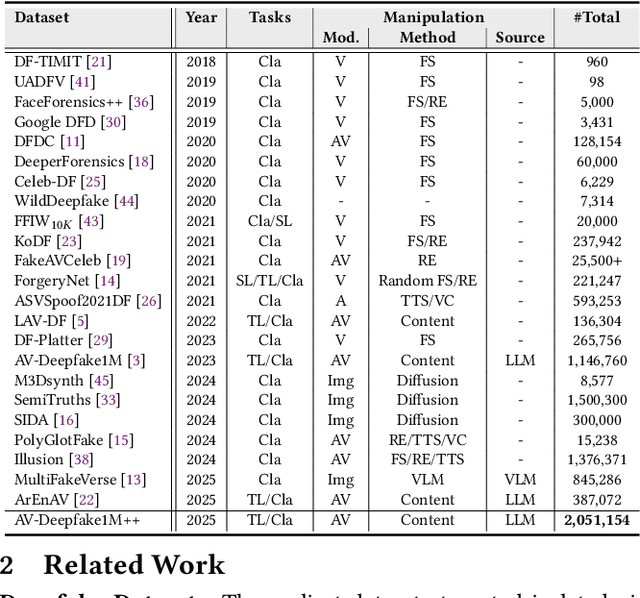
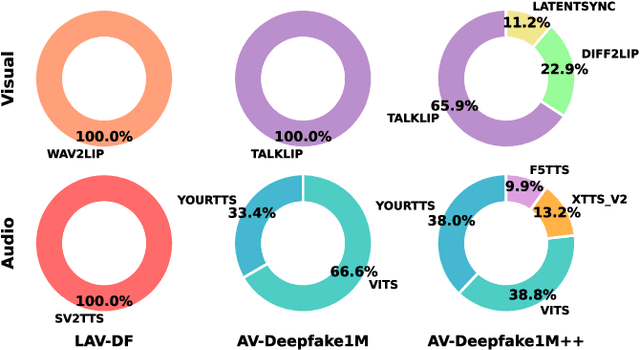
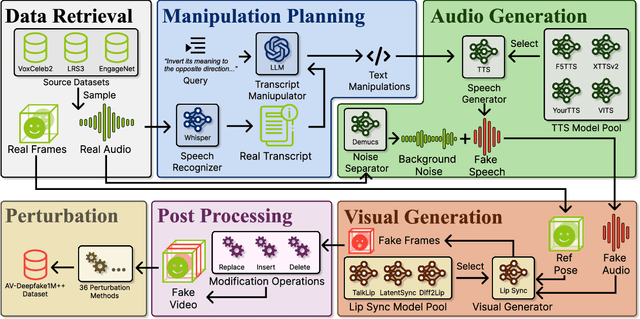
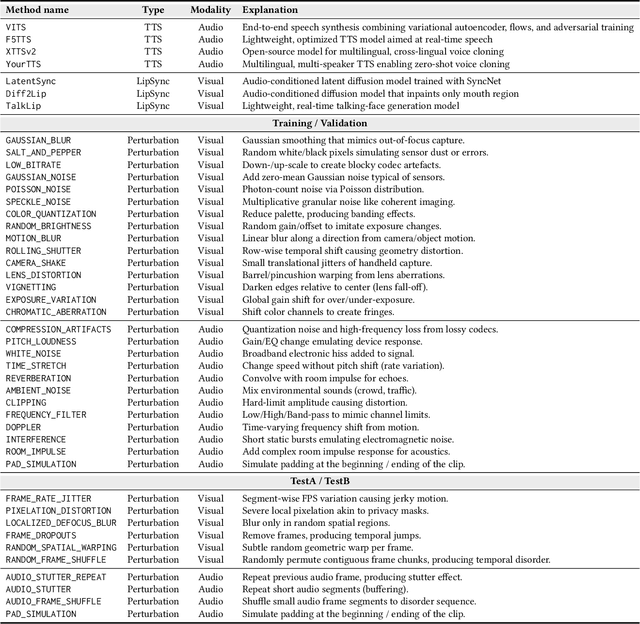
The rapid surge of text-to-speech and face-voice reenactment models makes video fabrication easier and highly realistic. To encounter this problem, we require datasets that rich in type of generation methods and perturbation strategy which is usually common for online videos. To this end, we propose AV-Deepfake1M++, an extension of the AV-Deepfake1M having 2 million video clips with diversified manipulation strategy and audio-visual perturbation. This paper includes the description of data generation strategies along with benchmarking of AV-Deepfake1M++ using state-of-the-art methods. We believe that this dataset will play a pivotal role in facilitating research in Deepfake domain. Based on this dataset, we host the 2025 1M-Deepfakes Detection Challenge. The challenge details, dataset and evaluation scripts are available online under a research-only license at https://deepfakes1m.github.io/2025.
1M-Deepfakes Detection Challenge
Sep 11, 2024



The detection and localization of deepfake content, particularly when small fake segments are seamlessly mixed with real videos, remains a significant challenge in the field of digital media security. Based on the recently released AV-Deepfake1M dataset, which contains more than 1 million manipulated videos across more than 2,000 subjects, we introduce the 1M-Deepfakes Detection Challenge. This challenge is designed to engage the research community in developing advanced methods for detecting and localizing deepfake manipulations within the large-scale high-realistic audio-visual dataset. The participants can access the AV-Deepfake1M dataset and are required to submit their inference results for evaluation across the metrics for detection or localization tasks. The methodologies developed through the challenge will contribute to the development of next-generation deepfake detection and localization systems. Evaluation scripts, baseline models, and accompanying code will be available on https://github.com/ControlNet/AV-Deepfake1M.
Real, fake and synthetic faces -- does the coin have three sides?
Apr 02, 2024
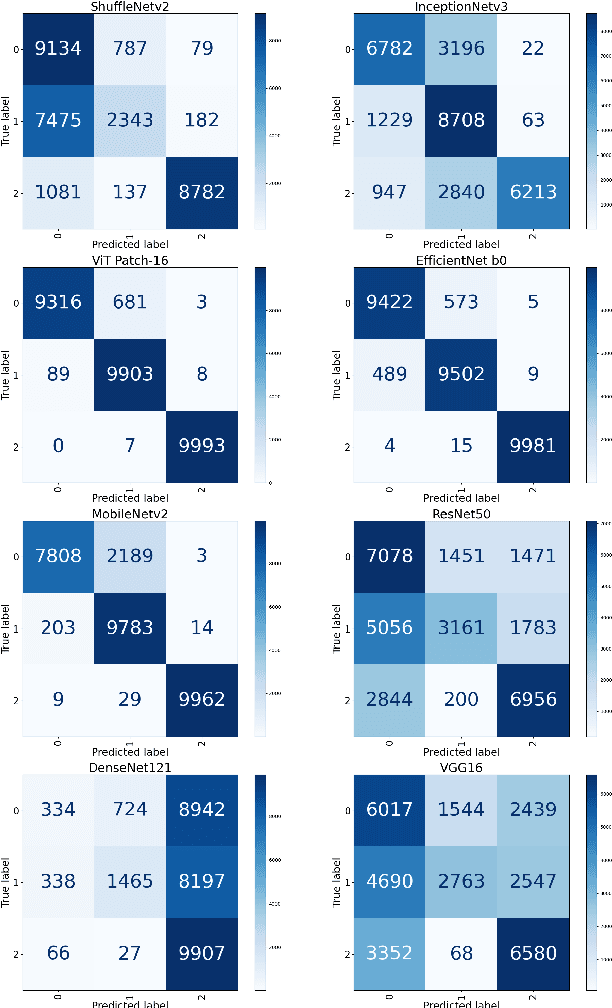
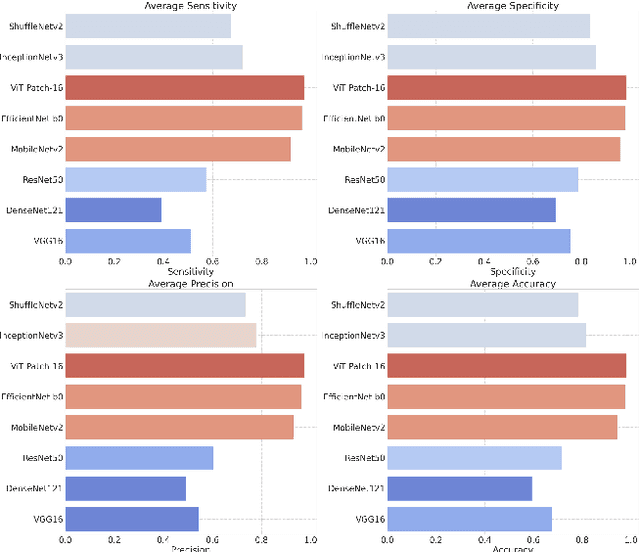
With the ever-growing power of generative artificial intelligence, deepfake and artificially generated (synthetic) media have continued to spread online, which creates various ethical and moral concerns regarding their usage. To tackle this, we thus present a novel exploration of the trends and patterns observed in real, deepfake and synthetic facial images. The proposed analysis is done in two parts: firstly, we incorporate eight deep learning models and analyze their performances in distinguishing between the three classes of images. Next, we look to further delve into the similarities and differences between these three sets of images by investigating their image properties both in the context of the entire image as well as in the context of specific regions within the image. ANOVA test was also performed and provided further clarity amongst the patterns associated between the images of the three classes. From our findings, we observe that the investigated deeplearning models found it easier to detect synthetic facial images, with the ViT Patch-16 model performing best on this task with a class-averaged sensitivity, specificity, precision, and accuracy of 97.37%, 98.69%, 97.48%, and 98.25%, respectively. This observation was supported by further analysis of various image properties. We saw noticeable differences across the three category of images. This analysis can help us build better algorithms for facial image generation, and also shows that synthetic, deepfake and real face images are indeed three different classes.
Generation and Detection of Sign Language Deepfakes -- A Linguistic and Visual Analysis
Apr 01, 2024A question in the realm of deepfakes is slowly emerging pertaining to whether we can go beyond facial deepfakes and whether it would be beneficial to society. Therefore, this research presents a positive application of deepfake technology in upper body generation, while performing sign-language for the Deaf and Hard of Hearing (DHoH) community. The resulting videos are later vetted with a sign language expert. This is particularly helpful, given the intricate nature of sign language, a scarcity of sign language experts, and potential benefits for health and education. The objectives of this work encompass constructing a reliable deepfake dataset, evaluating its technical and visual credibility through computer vision and natural language processing models, and assessing the plausibility of the generated content. With over 1200 videos, featuring both previously seen and unseen individuals for the generation model, using the help of a sign language expert, we establish a deepfake dataset in sign language that can further be utilized to detect fake videos that may target certain people of determination.
Self-Supervised Approach for Facial Movement Based Optical Flow
May 04, 2021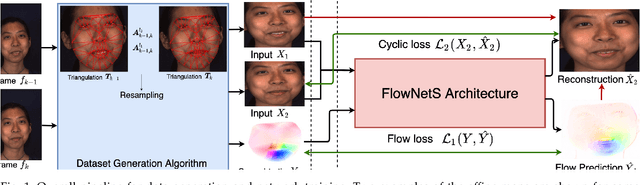
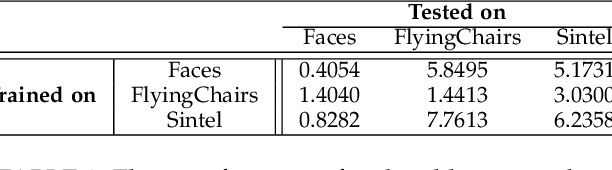

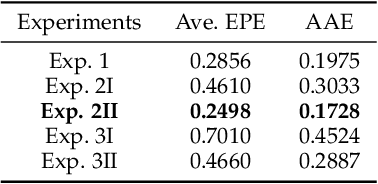
Computing optical flow is a fundamental problem in computer vision. However, deep learning-based optical flow techniques do not perform well for non-rigid movements such as those found in faces, primarily due to lack of the training data representing the fine facial motion. We hypothesize that learning optical flow on face motion data will improve the quality of predicted flow on faces. The aim of this work is threefold: (1) exploring self-supervised techniques to generate optical flow ground truth for face images; (2) computing baseline results on the effects of using face data to train Convolutional Neural Networks (CNN) for predicting optical flow; and (3) using the learned optical flow in micro-expression recognition to demonstrate its effectiveness. We generate optical flow ground truth using facial key-points in the BP4D-Spontaneous dataset. The generated optical flow is used to train the FlowNetS architecture to test its performance on the generated dataset. The performance of FlowNetS trained on face images surpassed that of other optical flow CNN architectures, demonstrating its usefulness. Our optical flow features are further compared with other methods using the STSTNet micro-expression classifier, and the results indicate that the optical flow obtained using this work has promising applications in facial expression analysis.
Hyperrealistic Image Inpainting with Hypergraphs
Nov 05, 2020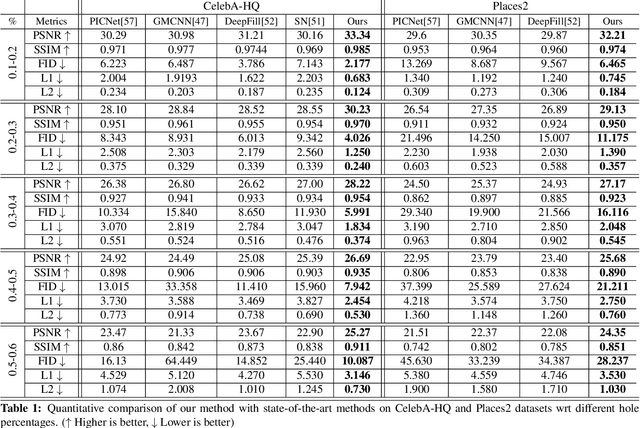
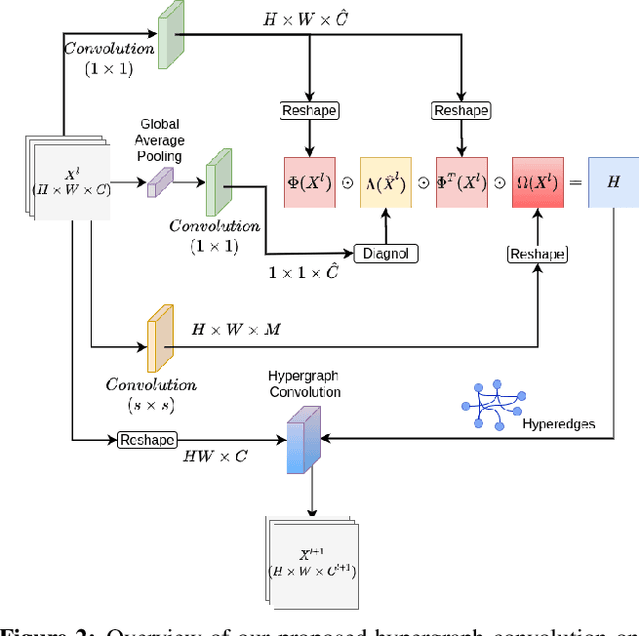
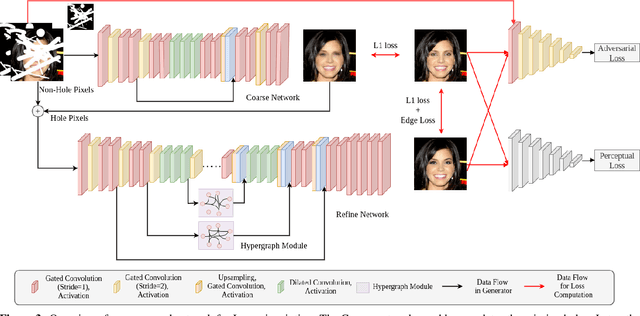

Image inpainting is a non-trivial task in computer vision due to multiple possibilities for filling the missing data, which may be dependent on the global information of the image. Most of the existing approaches use the attention mechanism to learn the global context of the image. This attention mechanism produces semantically plausible but blurry results because of incapability to capture the global context. In this paper, we introduce hypergraph convolution on spatial features to learn the complex relationship among the data. We introduce a trainable mechanism to connect nodes using hyperedges for hypergraph convolution. To the best of our knowledge, hypergraph convolution have never been used on spatial features for any image-to-image tasks in computer vision. Further, we introduce gated convolution in the discriminator to enforce local consistency in the predicted image. The experiments on Places2, CelebA-HQ, Paris Street View, and Facades datasets, show that our approach achieves state-of-the-art results.