 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperrealistic Image Inpainting with Hypergraphs
Nov 05, 2020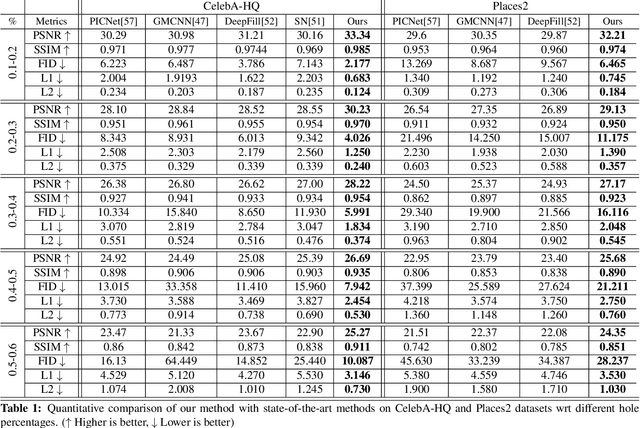
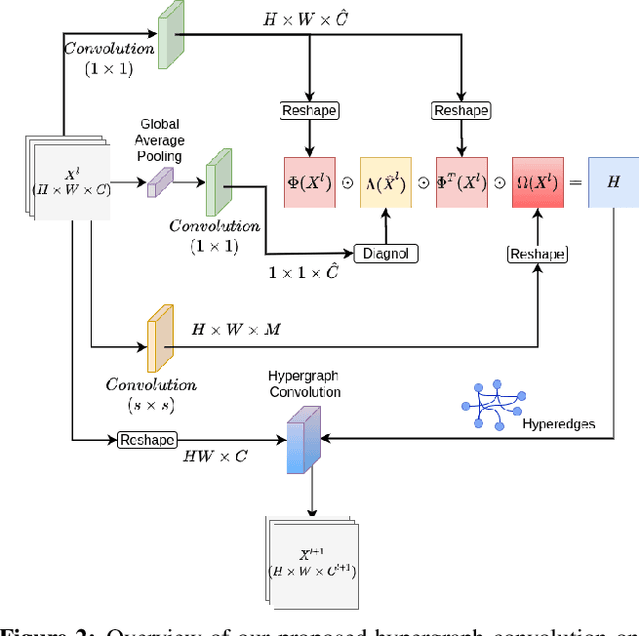
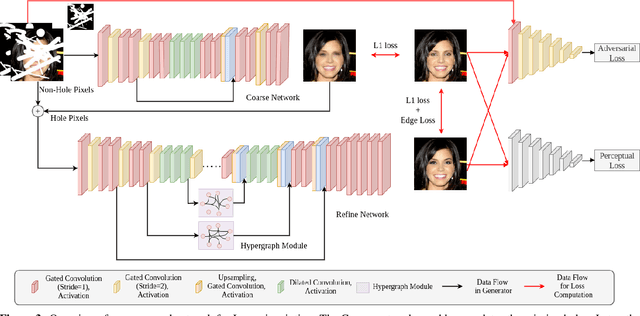

Image inpainting is a non-trivial task in computer vision due to multiple possibilities for filling the missing data, which may be dependent on the global information of the image. Most of the existing approaches use the attention mechanism to learn the global context of the image. This attention mechanism produces semantically plausible but blurry results because of incapability to capture the global context. In this paper, we introduce hypergraph convolution on spatial features to learn the complex relationship among the data. We introduce a trainable mechanism to connect nodes using hyperedges for hypergraph convolution. To the best of our knowledge, hypergraph convolution have never been used on spatial features for any image-to-image tasks in computer vision. Further, we introduce gated convolution in the discriminator to enforce local consistency in the predicted image. The experiments on Places2, CelebA-HQ, Paris Street View, and Facades datasets, show that our approach achieves state-of-the-art results.