 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Spectrum-Aware Latent Steering for Zero-Shot Generalization in Vision-Language Models
Nov 12, 2025
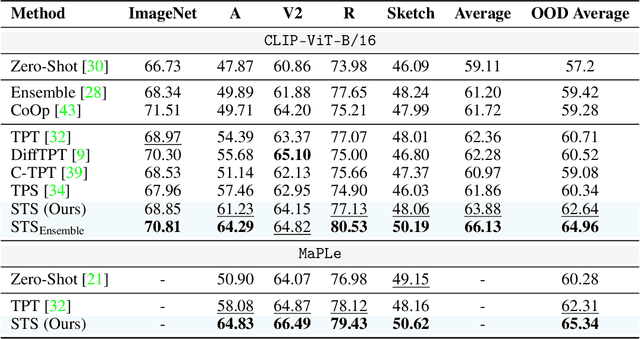

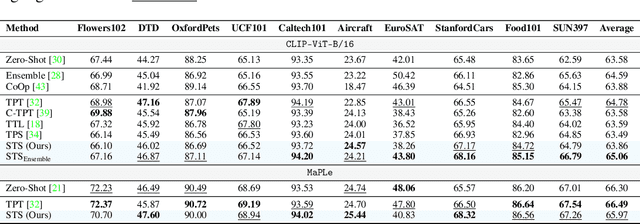
Vision-Language Models (VLMs) excel at zero-shot inference but often degrade under test-time domain shifts. For this reason, episodic test-time adaptation strategies have recently emerged as powerful techniques for adapting VLMs to a single unlabeled image. However, existing adaptation strategies, such as test-time prompt tuning, typically require backpropagating through large encoder weights or altering core model components. In this work, we introduce Spectrum-Aware Test-Time Steering (STS), a lightweight adaptation framework that extracts a spectral subspace from the textual embeddings to define principal semantic directions and learns to steer latent representations in a spectrum-aware manner by adapting a small number of per-sample shift parameters to minimize entropy across augmented views. STS operates entirely at inference in the latent space, without backpropagation through or modification of the frozen encoders. Building on standard evaluation protocols, our comprehensive experiments demonstrate that STS largely surpasses or compares favorably against state-of-the-art test-time adaptation methods, while introducing only a handful of additional parameters and achieving inference speeds up to 8x faster with a 12x smaller memory footprint than conventional test-time prompt tuning. The code is available at https://github.com/kdafnis/STS.
OmniLabel: A Challenging Benchmark for Language-Based Object Detection
Apr 22, 2023



Language-based object detection is a promising direction towards building a natural interface to describe objects in images that goes far beyond plain category names. While recent methods show great progress in that direction, proper evaluation is lacking. With OmniLabel, we propose a novel task definition, dataset, and evaluation metric. The task subsumes standard- and open-vocabulary detection as well as referring expressions. With more than 28K unique object descriptions on over 25K images, OmniLabel provides a challenging benchmark with diverse and complex object descriptions in a naturally open-vocabulary setting. Moreover, a key differentiation to existing benchmarks is that our object descriptions can refer to one, multiple or even no object, hence, providing negative examples in free-form text. The proposed evaluation handles the large label space and judges performance via a modified average precision metric, which we validate by evaluating strong language-based baselines. OmniLabel indeed provides a challenging test bed for future research on language-based detection.