 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Dynamic Concept Personalization with Grid-Based LoRA
Jul 23, 2025
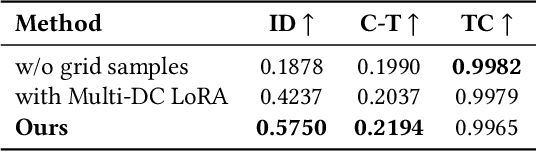
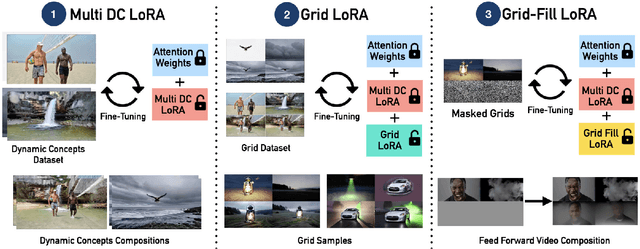
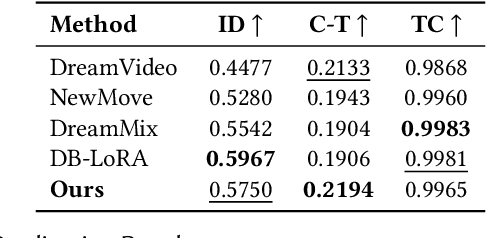
Recent advances in text-to-video generation have enabled high-quality synthesis from text and image prompts. While the personalization of dynamic concepts, which capture subject-specific appearance and motion from a single video, is now feasible, most existing methods require per-instance fine-tuning, limiting scalability. We introduce a fully zero-shot framework for dynamic concept personalization in text-to-video models. Our method leverages structured 2x2 video grids that spatially organize input and output pairs, enabling the training of lightweight Grid-LoRA adapters for editing and composition within these grids. At inference, a dedicated Grid Fill module completes partially observed layouts, producing temporally coherent and identity preserving outputs. Once trained, the entire system operates in a single forward pass, generalizing to previously unseen dynamic concepts without any test-time optimization. Extensive experiments demonstrate high-quality and consistent results across a wide range of subjects beyond trained concepts and editing scenarios.
Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers
Feb 29, 2024



The quality of the data and annotation upper-bounds the quality of a downstream model. While there exist large text corpora and image-text pairs, high-quality video-text data is much harder to collect. First of all, manual labeling is more time-consuming, as it requires an annotator to watch an entire video. Second, videos have a temporal dimension, consisting of several scenes stacked together, and showing multiple actions. Accordingly, to establish a video dataset with high-quality captions, we propose an automatic approach leveraging multimodal inputs, such as textual video description, subtitles, and individual video frames. Specifically, we curate 3.8M high-resolution videos from the publicly available HD-VILA-100M dataset. We then split them into semantically consistent video clips, and apply multiple cross-modality teacher models to obtain captions for each video. Next, we finetune a retrieval model on a small subset where the best caption of each video is manually selected and then employ the model in the whole dataset to select the best caption as the annotation. In this way, we get 70M videos paired with high-quality text captions. We dub the dataset as Panda-70M. We show the value of the proposed dataset on three downstream tasks: video captioning, video and text retrieval, and text-driven video generation. The models trained on the proposed data score substantially better on the majority of metrics across all the tasks.
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis
Feb 22, 2024



Contemporary models for generating images show remarkable quality and versatility. Swayed by these advantages, the research community repurposes them to generate videos. Since video content is highly redundant, we argue that naively bringing advances of image models to the video generation domain reduces motion fidelity, visual quality and impairs scalability. In this work, we build Snap Video, a video-first model that systematically addresses these challenges. To do that, we first extend the EDM framework to take into account spatially and temporally redundant pixels and naturally support video generation. Second, we show that a U-Net - a workhorse behind image generation - scales poorly when generating videos, requiring significant computational overhead. Hence, we propose a new transformer-based architecture that trains 3.31 times faster than U-Nets (and is ~4.5 faster at inference). This allows us to efficiently train a text-to-video model with billions of parameters for the first time, reach state-of-the-art results on a number of benchmarks, and generate videos with substantially higher quality, temporal consistency, and motion complexity. The user studies showed that our model was favored by a large margin over the most recent methods. See our website at https://snap-research.github.io/snapvideo/.