 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVD3D: Taming Large Video Diffusion Transformers for 3D Camera Control
Jul 17, 2024



Modern text-to-video synthesis models demonstrate coherent, photorealistic generation of complex videos from a text description. However, most existing models lack fine-grained control over camera movement, which is critical for downstream applications related to content creation, visual effects, and 3D vision. Recently, new methods demonstrate the ability to generate videos with controllable camera poses these techniques leverage pre-trained U-Net-based diffusion models that explicitly disentangle spatial and temporal generation. Still, no existing approach enables camera control for new, transformer-based video diffusion models that process spatial and temporal information jointly. Here, we propose to tame video transformers for 3D camera control using a ControlNet-like conditioning mechanism that incorporates spatiotemporal camera embeddings based on Plucker coordinates. The approach demonstrates state-of-the-art performance for controllable video generation after fine-tuning on the RealEstate10K dataset. To the best of our knowledge, our work is the first to enable camera control for transformer-based video diffusion models.
GTR: Improving Large 3D Reconstruction Models through Geometry and Texture Refinement
Jun 09, 2024We propose a novel approach for 3D mesh reconstruction from multi-view images. Our method takes inspiration from large reconstruction models like LRM that use a transformer-based triplane generator and a Neural Radiance Field (NeRF) model trained on multi-view images. However, in our method, we introduce several important modifications that allow us to significantly enhance 3D reconstruction quality. First of all, we examine the original LRM architecture and find several shortcomings. Subsequently, we introduce respective modifications to the LRM architecture, which lead to improved multi-view image representation and more computationally efficient training. Second, in order to improve geometry reconstruction and enable supervision at full image resolution, we extract meshes from the NeRF field in a differentiable manner and fine-tune the NeRF model through mesh rendering. These modifications allow us to achieve state-of-the-art performance on both 2D and 3D evaluation metrics, such as a PSNR of 28.67 on Google Scanned Objects (GSO) dataset. Despite these superior results, our feed-forward model still struggles to reconstruct complex textures, such as text and portraits on assets. To address this, we introduce a lightweight per-instance texture refinement procedure. This procedure fine-tunes the triplane representation and the NeRF color estimation model on the mesh surface using the input multi-view images in just 4 seconds. This refinement improves the PSNR to 29.79 and achieves faithful reconstruction of complex textures, such as text. Additionally, our approach enables various downstream applications, including text- or image-to-3D generation.
Improving Lesion Segmentation for Diabetic Retinopathy using Adversarial Learning
Jul 27, 2020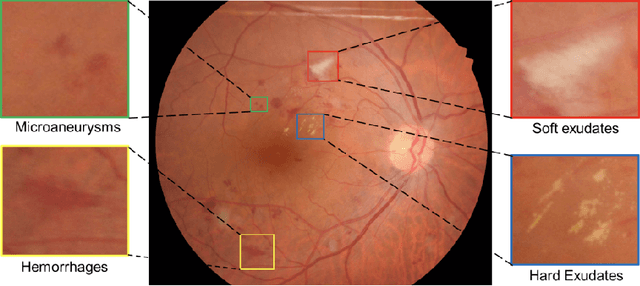
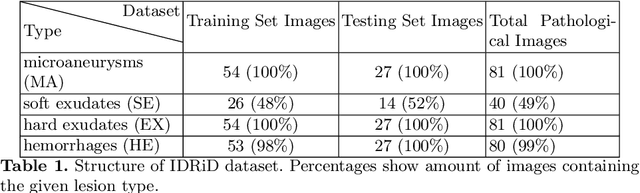
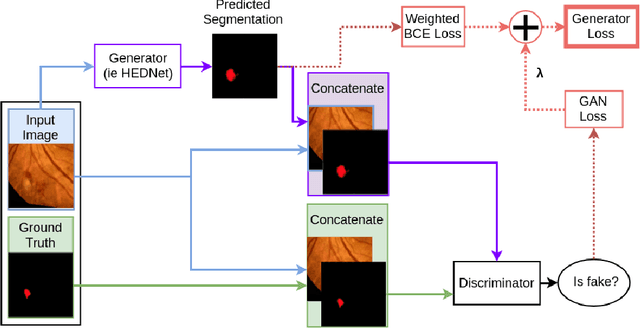
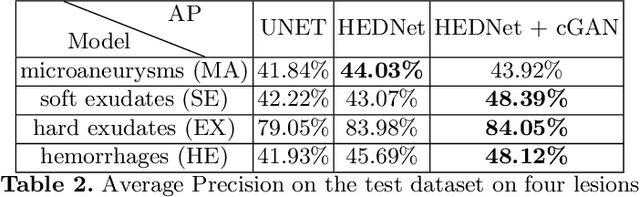
Diabetic Retinopathy (DR) is a leading cause of blindness in working age adults. DR lesions can be challenging to identify in fundus images, and automatic DR detection systems can offer strong clinical value. Of the publicly available labeled datasets for DR, the Indian Diabetic Retinopathy Image Dataset (IDRiD) presents retinal fundus images with pixel-level annotations of four distinct lesions: microaneurysms, hemorrhages, soft exudates and hard exudates. We utilize the HEDNet edge detector to solve a semantic segmentation task on this dataset, and then propose an end-to-end system for pixel-level segmentation of DR lesions by incorporating HEDNet into a Conditional Generative Adversarial Network (cGAN). We design a loss function that adds adversarial loss to segmentation loss. Our experiments show that the addition of the adversarial loss improves the lesion segmentation performance over the baseline.