 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetinaMask: Learning to predict masks improves state-of-the-art single-shot detection for free
Paper and Code
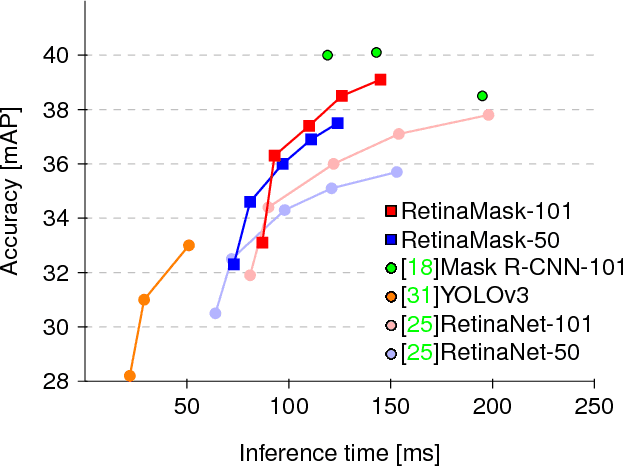
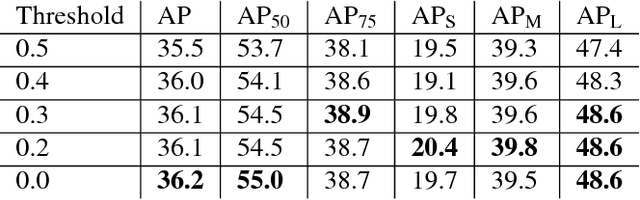
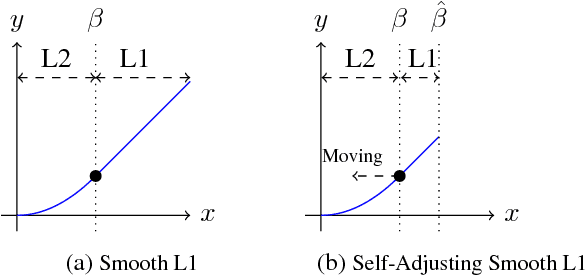
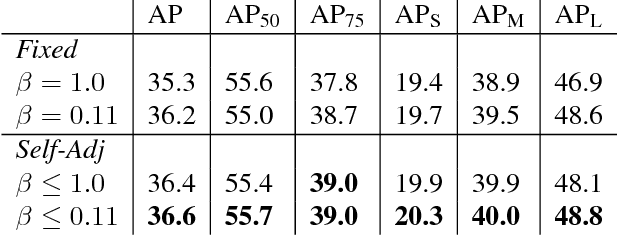
Recently two-stage detectors have surged ahead of single-shot detectors in the accuracy-vs-speed trade-off. Nevertheless single-shot detectors are immensely popular in embedded vision applications. This paper brings single-shot detectors up to the same level as current two-stage techniques. We do this by improving training for the state-of-the-art single-shot detector, RetinaNet, in three ways: integrating instance mask prediction for the first time, making the loss function adaptive and more stable, and including additional hard examples in training. We call the resulting augmented network RetinaMask. The detection component of RetinaMask has the same computational cost as the original RetinaNet, but is more accurate. COCO test-dev results are up to 41.4 mAP for RetinaMask-101 vs 39.1mAP for RetinaNet-101, while the runtime is the same during evaluation. Adding Group Normalization increases the performance of RetinaMask-101 to 41.7 mAP. Code is at:https://github.com/chengyangfu/retinamask