 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterior Object Geometry via Fitted Frames
Jul 19, 2024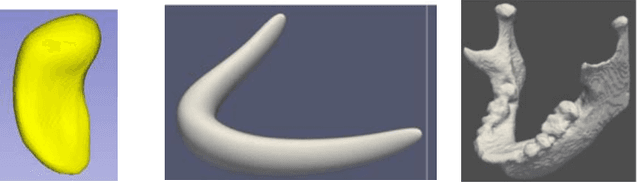
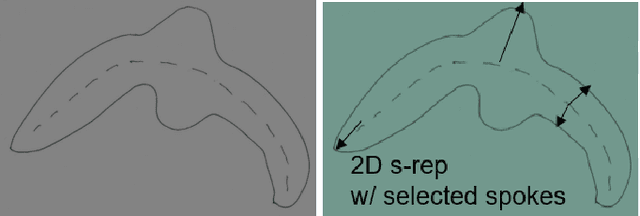

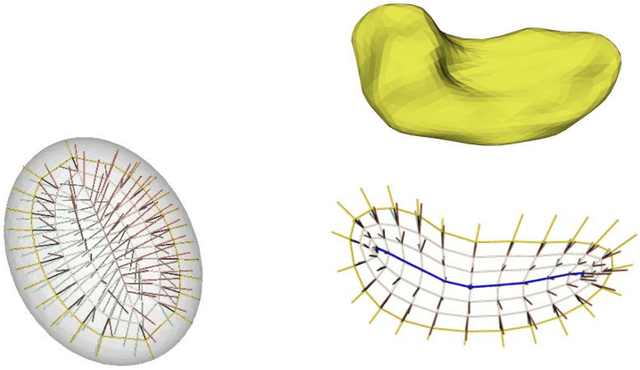
We describe a representation targeted for anatomic objects which is designed to enable strong locational correspondence within object populations and thus to provide powerful object statistics. The method generates fitted frames on the boundary and in the interior of objects and produces alignment-free geometric features from them. It accomplishes this by understanding an object as the diffeomorphic deformation of an ellipsoid and using a skeletal representation fitted throughout the deformation to produce a model of the target object, where the object is provided initially in the form of a boundary mesh. Via classification performance on hippocampi shape between individuals with a disorder vs. others, we compare our method to two state-of-the-art methods for producing object representations that are intended to capture geometric correspondence across a population of objects and to yield geometric features useful for statistics, and we show improved classification performance by this new representation, which we call the evolutionary s-rep. The geometric features that are derived from each of the representations, especially via fitted frames, is discussed.
Leveraging Near-Field Lighting for Monocular Depth Estimation from Endoscopy Videos
Mar 26, 2024



Monocular depth estimation in endoscopy videos can enable assistive and robotic surgery to obtain better coverage of the organ and detection of various health issues. Despite promising progress on mainstream, natural image depth estimation, techniques perform poorly on endoscopy images due to a lack of strong geometric features and challenging illumination effects. In this paper, we utilize the photometric cues, i.e., the light emitted from an endoscope and reflected by the surface, to improve monocular depth estimation. We first create two novel loss functions with supervised and self-supervised variants that utilize a per-pixel shading representation. We then propose a novel depth refinement network (PPSNet) that leverages the same per-pixel shading representation. Finally, we introduce teacher-student transfer learning to produce better depth maps from both synthetic data with supervision and clinical data with self-supervision. We achieve state-of-the-art results on the C3VD dataset while estimating high-quality depth maps from clinical data. Our code, pre-trained models, and supplementary materials can be found on our project page: https://ppsnet.github.io/
A Surface-normal Based Neural Framework for Colonoscopy Reconstruction
Mar 13, 2023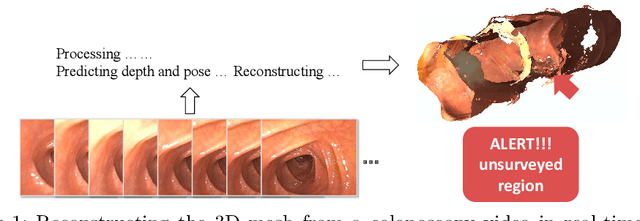
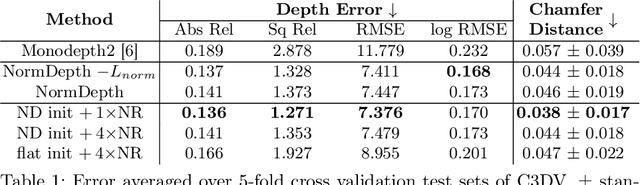
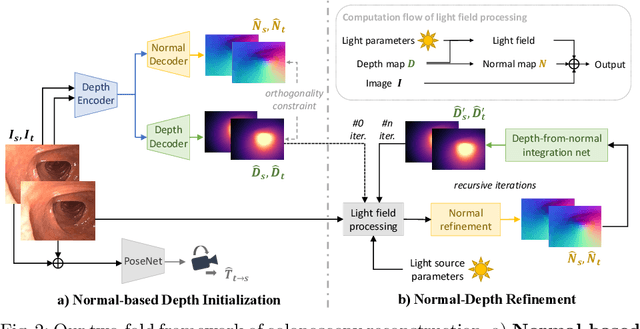
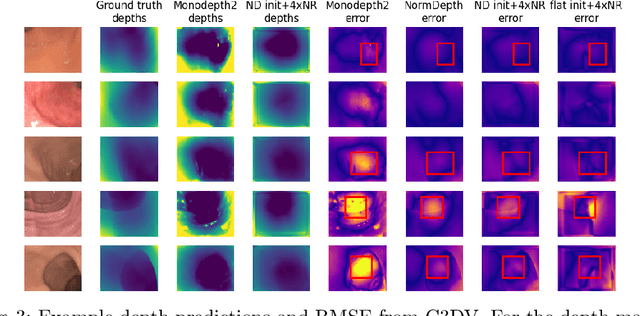
Reconstructing a 3D surface from colonoscopy video is challenging due to illumination and reflectivity variation in the video frame that can cause defective shape predictions. Aiming to overcome this challenge, we utilize the characteristics of surface normal vectors and develop a two-step neural framework that significantly improves the colonoscopy reconstruction quality. The normal-based depth initialization network trained with self-supervised normal consistency loss provides depth map initialization to the normal-depth refinement module, which utilizes the relationship between illumination and surface normals to refine the frame-wise normal and depth predictions recursively. Our framework's depth accuracy performance on phantom colonoscopy data demonstrates the value of exploiting the surface normals in colonoscopy reconstruction, especially on en face views. Due to its low depth error, the prediction result from our framework will require limited post-processing to be clinically applicable for real-time colonoscopy reconstruction.
ColDE: A Depth Estimation Framework for Colonoscopy Reconstruction
Nov 19, 2021
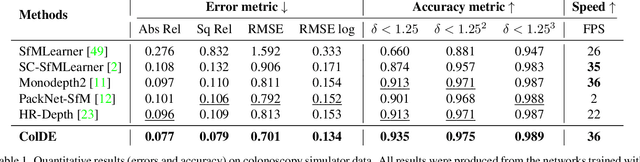
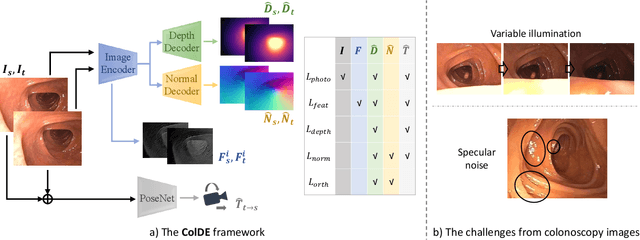
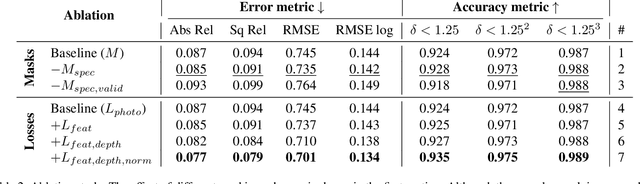
One of the key elements of reconstructing a 3D mesh from a monocular video is generating every frame's depth map. However, in the application of colonoscopy video reconstruction, producing good-quality depth estimation is challenging. Neural networks can be easily fooled by photometric distractions or fail to capture the complex shape of the colon surface, predicting defective shapes that result in broken meshes. Aiming to fundamentally improve the depth estimation quality for colonoscopy 3D reconstruction, in this work we have designed a set of training losses to deal with the special challenges of colonoscopy data. For better training, a set of geometric consistency objectives was developed, using both depth and surface normal information. Also, the classic photometric loss was extended with feature matching to compensate for illumination noise. With the training losses powerful enough, our self-supervised framework named ColDE is able to produce better depth maps of colonoscopy data as compared to the previous work utilizing prior depth knowledge. Used in reconstruction, our network is able to reconstruct good-quality colon meshes in real-time without any post-processing, making it the first to be clinically applicable.
Lighting Enhancement Aids Reconstruction of Colonoscopic Surfaces
Mar 18, 2021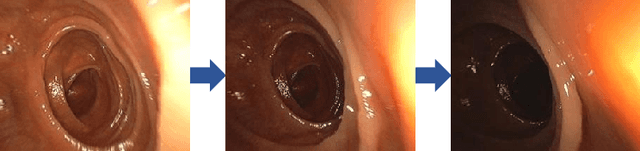
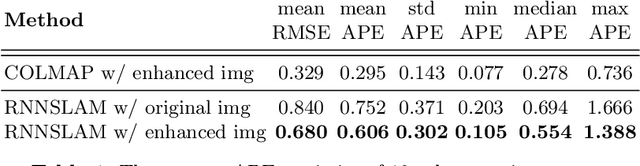

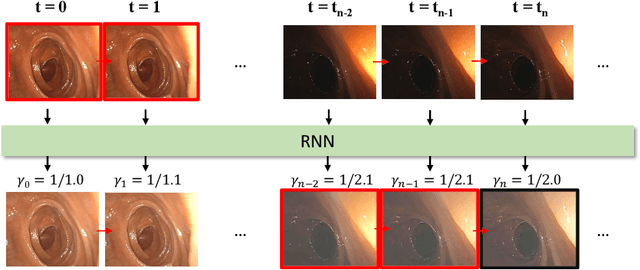
High screening coverage during colonoscopy is crucial to effectively prevent colon cancer. Previous work has allowed alerting the doctor to unsurveyed regions by reconstructing the 3D colonoscopic surface from colonoscopy videos in real-time. However, the lighting inconsistency of colonoscopy videos can cause a key component of the colonoscopic reconstruction system, the SLAM optimization, to fail. In this work we focus on the lighting problem in colonoscopy videos. To successfully improve the lighting consistency of colonoscopy videos, we have found necessary a lighting correction that adapts to the intensity distribution of recent video frames. To achieve this in real-time, we have designed and trained an RNN network. This network adapts the gamma value in a gamma-correction process. Applied in the colonoscopic surface reconstruction system, our light-weight model significantly boosts the reconstruction success rate, making a larger proportion of colonoscopy video segments reconstructable and improving the reconstruction quality of the already reconstructed segments.
Recurrent Neural Network for (Un-)supervised Learning of Monocular VideoVisual Odometry and Depth
Apr 15, 2019
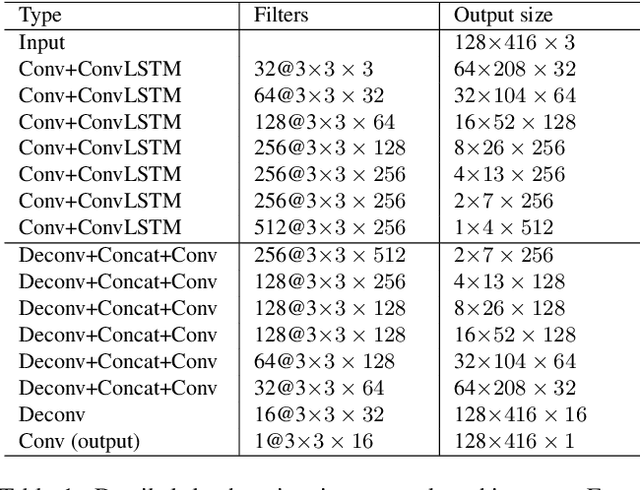

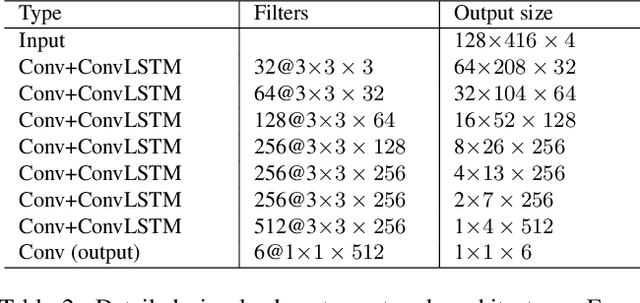
Deep learning-based, single-view depth estimation methods have recently shown highly promising results. However, such methods ignore one of the most important features for determining depth in the human vision system, which is motion. We propose a learning-based, multi-view dense depth map and odometry estimation method that uses Recurrent Neural Networks (RNN) and trains utilizing multi-view image reprojection and forward-backward flow-consistency losses. Our model can be trained in a supervised or even unsupervised mode. It is designed for depth and visual odometry estimation from video where the input frames are temporally correlated. However, it also generalizes to single-view depth estimation. Our method produces superior results to the state-of-the-art approaches for single-view and multi-view learning-based depth estimation on the KITTI driving dataset.
Recurrent Neural Network for Learning DenseDepth and Ego-Motion from Video
May 17, 2018
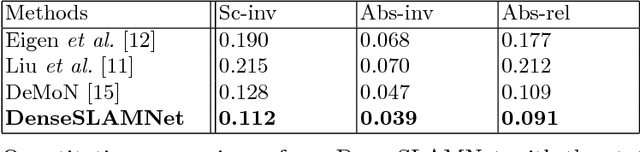

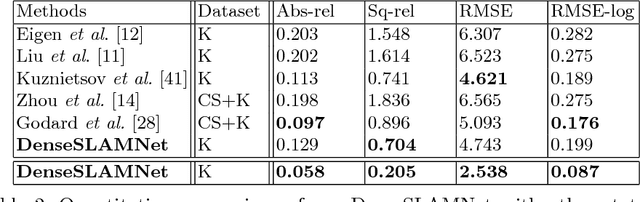
Learning-based, single-view depth estimation often generalizes poorly to unseen datasets. While learning-based, two-frame depth estimation solves this problem to some extent by learning to match features across frames, it performs poorly at large depth where the uncertainty is high. There exists few learning-based, multi-view depth estimation methods. In this paper, we present a learning-based, multi-view dense depth map and ego-motion estimation method that uses Recurrent Neural Networks (RNN). Our model is designed for 3D reconstruction from video where the input frames are temporally correlated. It is generalizable to single- or two-view dense depth estimation. Compared to recent single- or two-view CNN-based depth estimation methods, our model leverages more views and achieves more accurate results, especially at large distances. Our method produces superior results to the state-of-the-art learning-based, single- or two-view depth estimation methods on both indoor and outdoor benchmark datasets. We also demonstrate that our method can even work on extremely difficult sequences, such as endoscopic video, where none of the assumptions (static scene, constant lighting, Lambertian reflection, etc.) from traditional 3D reconstruction methods hold.