 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Neural Network for (Un-)supervised Learning of Monocular VideoVisual Odometry and Depth
Paper and Code

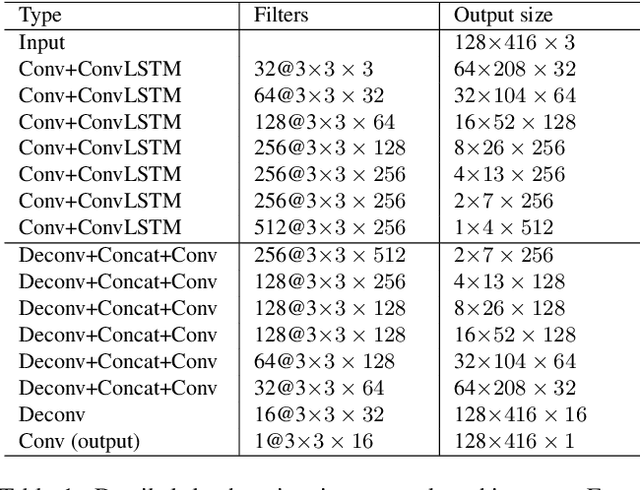

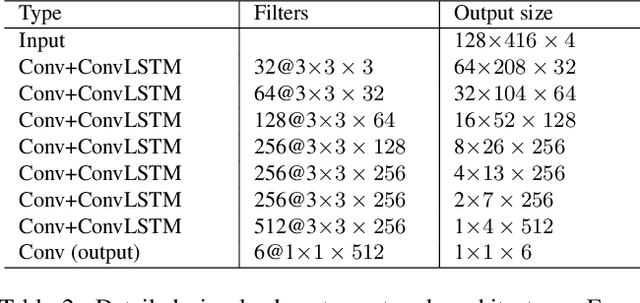
Deep learning-based, single-view depth estimation methods have recently shown highly promising results. However, such methods ignore one of the most important features for determining depth in the human vision system, which is motion. We propose a learning-based, multi-view dense depth map and odometry estimation method that uses Recurrent Neural Networks (RNN) and trains utilizing multi-view image reprojection and forward-backward flow-consistency losses. Our model can be trained in a supervised or even unsupervised mode. It is designed for depth and visual odometry estimation from video where the input frames are temporally correlated. However, it also generalizes to single-view depth estimation. Our method produces superior results to the state-of-the-art approaches for single-view and multi-view learning-based depth estimation on the KITTI driving dataset.