 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Biases and Preserving Privacy on Balanced Faces in the Wild
Mar 16, 2021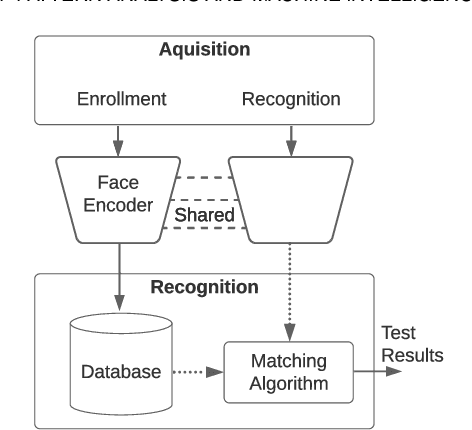
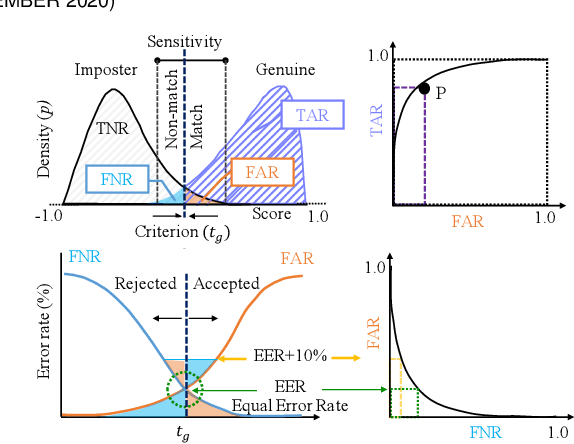
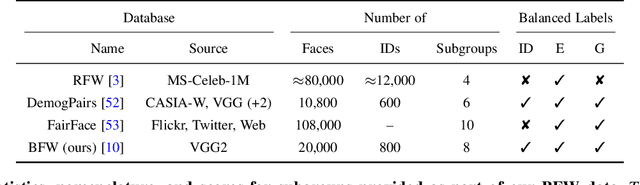
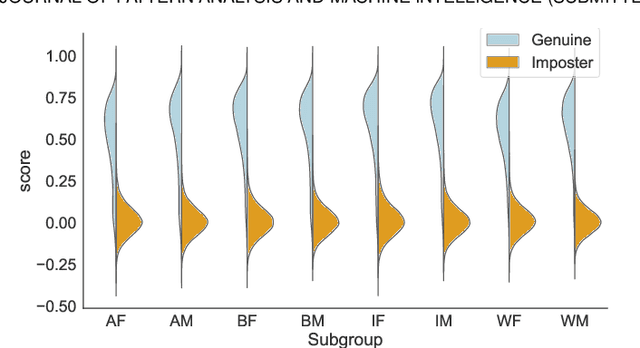
There are demographic biases in the SOTA CNN used for FR. Our BFW dataset serves as a proxy to measure bias across ethnicity and gender subgroups, allowing us to characterize FR performances per subgroup. We show performances are non-optimal when a single score threshold is used to determine whether sample pairs are genuine or imposter. Furthermore, actual performance ratings vary greatly from the reported across subgroups. Thus, claims of specific error rates only hold true for populations matching that of the validation data. We mitigate the imbalanced performances using a novel domain adaptation learning scheme on the facial encodings extracted using SOTA deep nets. Not only does this technique balance performance, but it also boosts the overall performance. A benefit of the proposed is to preserve identity information in facial features while removing demographic knowledge in the lower dimensional features. The removal of demographic knowledge prevents future potential biases from being injected into decision-making. Additionally, privacy concerns are satisfied by this removal. We explore why this works qualitatively with hard samples. We also show quantitatively that subgroup classifiers can no longer learn from the encodings mapped by the proposed.
Visual Kinship Recognition: A Decade in the Making
Jun 29, 2020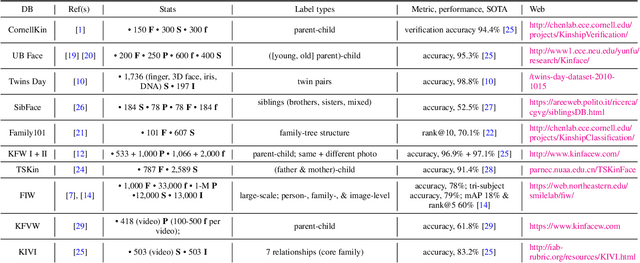
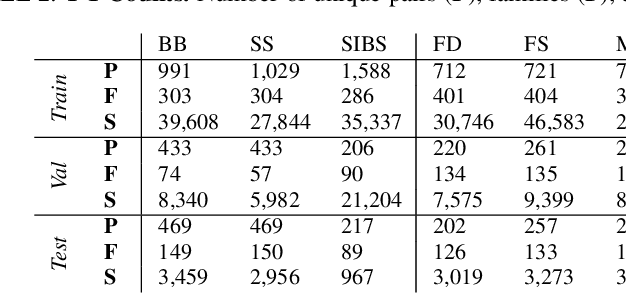

Kinship recognition is a challenging problem with many practical applications. With much progress and milestones having been reached after ten years since pioneered - it is now that today we are able to survey their research and create new milestones. We list and review the public resources and data challenges that enabled and inspired many to hone-in on one or more views of automatic kinship recognition in the visual domain. The different tasks are described in technical terms and syntax consistent across the problem domain and the practical value of each discussed and measured. State-of-the-art methods for visual kinship recognition problems, whether to discriminate between or generate from, are examined. As part of such, we review systems proposed as part of a recent data challenge held in conjunction with the 2020 IEEE Conference on Automatic Face and Gesture Recognition. We establish a stronghold for the state of progress for the different problems in a consistent manner. We intend for this survey will serve as the central resource for work of the next decade to build upon. For the tenth anniversary, demo code is provided for the various kin-based tasks. Detecting relatives with visual recognition and classifying the relationship is an area with high potential for impact in research and practice.
Face Recognition: Too Bias, or Not Too Bias?
Feb 16, 2020
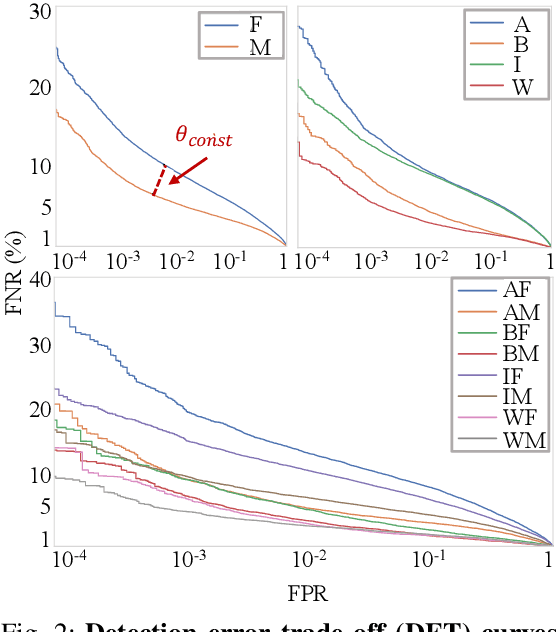
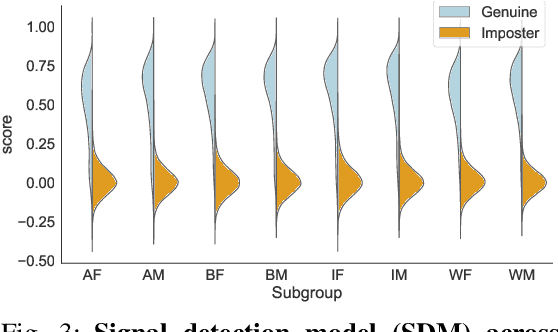
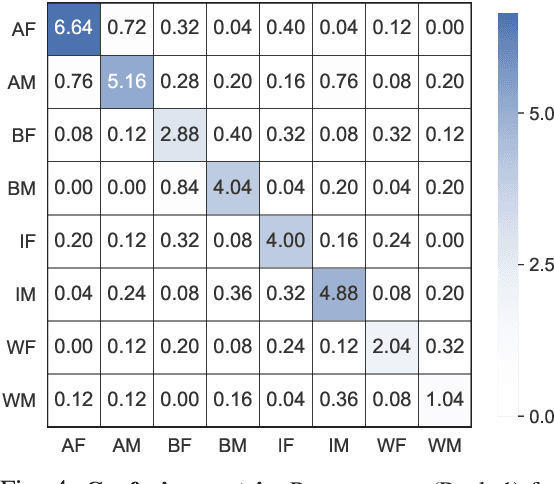
We reveal critical insights into problems of bias in state-of-the-art facial recognition (FR) systems using a novel Balanced Faces In the Wild (BFW) dataset: data balanced for gender and ethnic groups. We show variations in the optimal scoring threshold for face-pairs across different subgroups. Thus, the conventional approach of learning a global threshold for all pairs resulting in performance gaps among subgroups. By learning subgroup-specific thresholds, we not only mitigate problems in performance gaps but also show a notable boost in the overall performance. Furthermore, we do a human evaluation to measure the bias in humans, which supports the hypothesis that such a bias exists in human perception. For the BFW database, source code, and more, visit github.com/visionjo/facerec-bias-bfw.
Laplace Landmark Localization
Mar 27, 2019
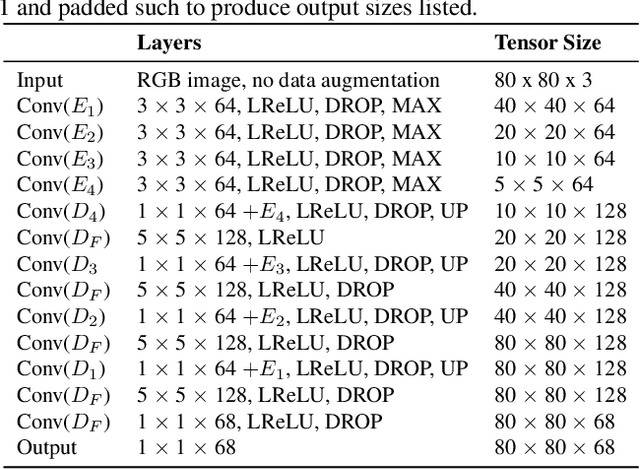
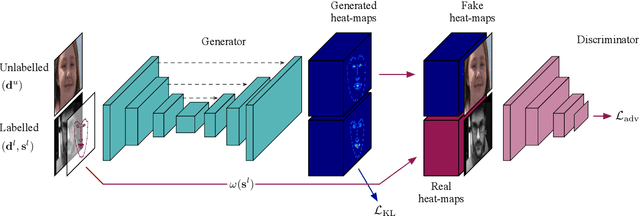
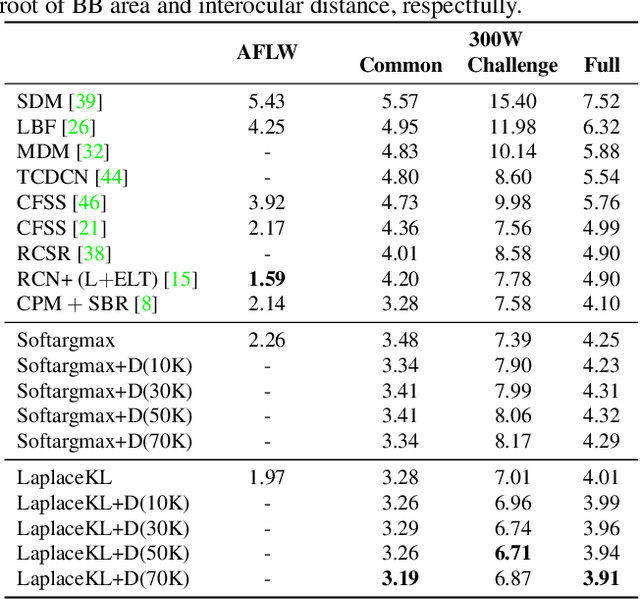
Landmark localization in images and videos is a classic problem solved in various ways. Nowadays, with deep networks prevailing throughout machine learning, there are revamped interests in pushing facial landmark detection technologies to handle more challenging data. Most efforts use network objectives based on L1 or L2 norms, which have several disadvantages. First of all, the locations of landmarks are determined from generated heatmaps (i.e., confidence maps) from which predicted landmark locations (i.e., the means) get penalized without accounting for the spread: a high scatter corresponds to low confidence and vice-versa. For this, we introduce a LaplaceKL objective that penalizes for a low confidence. Another issue is a dependency on labeled data, which are expensive to obtain and susceptible to error. To address both issues we propose an adversarial training framework that leverages unlabeled data to improve model performance. Our method claims state-of-the-art on all of the 300W benchmarks and ranks second-to-best on the Annotated Facial Landmarks in the Wild (AFLW) dataset. Furthermore, our model is robust with a reduced size: 1/8 the number of channels (i.e., 0.0398MB) is comparable to state-of-that-art in real-time on CPU. Thus, we show that our method is of high practical value to real-life application.